Особые IP-адреса
В протоколе IP существует несколько соглашений об особой интерпретации IP-адресов.
Если весь IP-адрес состоит только из двоичных нулей, то он обозначает адрес того узла, который сгенерировал этот пакет; этот режим используется только в некоторых сообщениях ICMP.
Если в поле номера сети стоят только нули, то по умолчанию считается, что узел назначения принадлежит той же самой сети, что и узел, который отправил пакет.
Если все двоичные разряды IP-адреса равны 1, то пакет с таким адресом назначения должен рассылаться всем узлам, находящимся в той же сети, что и источник этого пакета. Такая рассылка называется ограниченным широковещательным. сообщением (limited broadcast).
Если в поле номера узла назначения стоят только единицы, то пакет, имеющий такой адрес, рассылается всем узлам сети с заданным номером сети. Например, пакет с адресом 192.190.21.255 доставляется всем узлам сети 192.190.21.0. Такая рассылка называется широковещательным сообщением (broadcast).
При адресации необходимо учитывать те ограничения, которые вносятся особым назначением некоторых IP-адресов. Так, ни номер сети, ни номер узла не может состоять только из одних двоичных единиц или только из одних двоичных нулей. Отсюда следует, что максимальное количество узлов, приведенное в таблице для сетей каждого класса, на практике должно быть уменьшено на 2. Например, в сетях класса С под номер узла отводится 8 бит, которые позволяют задавать 256 номеров: от 0 до 255. Однако на практике максимальное число узлов в сети класса С не может превышать 254, так как адреса 0 и 255 имеют специальное назначение. Из этих же соображений следует, что конечный узел не может иметь адрес типа 98.255.255.255, поскольку номер узла в этом адресе класса А состоит из одних двоичных единиц.
Особый смысл имеет IP-адрес, первый октет которого равен 127. Он используется для тестирования программ и взаимодействия процессов в пределах одной машины. Когда программа посылает данные по IP-адресу 127.0.0.1, то образуется как бы «петля».
Данные не передаются по сети, а возвращаются модулям верхнего уровня как только что принятые. Поэтому в IP-сети запрещается присваивать машинам IP-адреса, начинающиеся со 127. Этот адрес имеет название loopback. Можно отнести адрес 127.0.0.0 ко внутренней сети модуля маршрутизации узла, а адрес 127.0.0.1 - к адресу этого модуля на внутренней сети. На самом деле любой адрес сети 127.0.0.0 служит для обозначения своего модуля маршрутизации, а не только 127.0.0.1, например 127.0.0.3.
В протоколе IP нет понятия широковещательности в том смысле, в котором оно используется в протоколах канального уровня локальных сетей, когда данные должны быть доставлены абсолютно всем узлам. Как ограниченный широковещательный IP-адрес, так и широковещательный IP-адрес имеют пределы распространения в интерсети - они ограничены либо сетью, к которой принадлежит узел-источник пакета, либо сетью, номер которой указан в адресе назначения. Поэтому деление сети с помощью маршрутизаторов на части локализует широковещательный шторм пределами одной из составляющих общую сеть частей просто потому, что нет способа адресовать пакет одновременно всем узлам всех сетей составной сети.
Уже упоминавшаяся форма группового IP-адреса - multicast - означает, что данный пакет должен быть доставлен сразу нескольким узлам, которые образуют группу с номером, указанным в поле адреса. Узлы сами идентифицируют себя, то есть определяют, к какой из групп они относятся. Один и тот же узел может входить в несколько групп. Члены какой-либо группы multicast не обязательно должны принадлежать одной сети. В общем случае они могут распределяться по совершенно различным сетям, находящимся друг от друга на произвольном количестве хопов. Групповой адрес не делится на поля номера сети и узла и обрабатывается маршрутизатором особым образом.
Основное назначение multicast-адресов - распространение информации по схеме «один-ко-многим». Хост, который хочет передавать одну и ту же информацию многим абонентам, с помощью специального протокола IGMP (Internet Group Management Protocol) сообщает о создании в сети новой мультивещательной группы с определенным адресом.
Машрутизаторы, поддерживающие мультивещательность, распространяют информацию о создании новой группы в сетях, подключенных к портам этого маршрутизатора. Хосты, которые хотят присоединиться к вновь создаваемой мультивещательной группе, сообщают об этом своим локальным маршрутизаторам и те передают эту информацию хосту, инициатору создания новой группы.
Чтобы маршрутизаторы могли автоматически распространять пакеты с адресом multicast по составной сети, необходимо использовать в конечных маршрутизаторах модифицированные протоколы обмена маршрутной информацией, такие как, например, MOSPF (Multicast OSPF, аналог OSPF).
Групповая адресация предназначена для экономичного распространения в Internet или большой корпоративной сети аудио- или видеопрограмм, предназначенных сразу большой аудитории слушателей или зрителей. Если такие средства найдут широкое применение (сейчас они представляют в основном небольшие экспериментальные островки в общем Internet), то Internet сможет создать серьезную конкуренцию радио и телевидению.
Отказ от маршрутизации
За последние годы основные усилия были сосредоточены в первом направлении: применять маршрутизацию как можно реже, только там, где от нее никак нельзя отказаться. Например, на границе между локальной и глобальной сетью. Отказ от маршрутизаторов означает переход к так называемой плоской сети, то есть сети, построенной только на коммутаторах, а значит, и отказ от всех интеллектуальных возможностей обработки трафика, присущих маршрутизаторам. Такой подход повышает производительность, но приводит к потере всех преимуществ, которые давали маршрутизаторы, а именно:
маршрутизаторы более надежно, чем коммутаторы, изолируют части большой составной сети друг от друга, защищая их от ошибочных кадров, порождаемых неисправным программным или аппаратным обеспечением других сетей (например, от широковещательных штормов);
маршрутизаторы обладают более развитыми возможностями защиты от несанкционированного доступа за счет функций анализа и фильтрации трафика на более высоких уровнях: сетевом и транспортном;
сеть, не разделенная маршрутизаторами, имеет ограничения на число узлов (для популярного протокола IP это ограничение составляет 255 узлов для сетей самого доступного класса С).
Из этого следует, что в сети необходимо сохранять функции маршрутизации в привычном смысле этого слова.
Что касается второго направления - повышение производительности маршрутизаторов, - сложилось так, что самые активные действия в этом направлении были предприняты производителями коммутаторов, наделявшими свои продукты некоторыми возможностями маршрутизаторов. Именно в модифицированных коммутаторах были впервые достигнуты скорости маршрутизации в 5-7 миллионов пакетов в секунду, а также опробованы многие важные концепции ускорения функций маршрутизации.
Отказоустойчивость технологии FDDI
Для обеспечения отказоустойчивости в стандарте FDDI предусмотрено создание двух оптоволоконных колец - первичного и вторичного. В стандарте FDDI допускаются два вида подсоединения станций к сети. Одновременное подключение к первичному и вторичному кольцам называется двойным подключением - Dual Attachment, DA. Подключение только к первичному кольцу называется одиночным подключением - Single Attachment, SA.
В стандарте FDDI предусмотрено наличие в сети конечных узлов - станций (Station), а также концентраторов (Concentrator). Для станций и концентраторов допустим любой вид подключения к сети - как одиночный, так и двойной. Соответственно такие устройства имеют соответствующие названия: SAS (Single Attachment Station), DAS (Dual Attachment Station), SAC (Single Attachment Concentrator) и DAC (Dual Attachment Concentrator).
Обычно концентраторы имеют двойное подключение, а станции - одинарное, как это показано на рис. 3.18, хотя это и не обязательно. Чтобы устройства легче было правильно присоединять к сети, их разъемы маркируются. Разъемы типа А и В должны быть у устройств с двойным подключением, разъем М (Master) имеется у концентратора для одиночного подключения станции, у которой ответный разъем должен иметь тип S (Slave).

Рис. 3.18. Подключение узлов к кольцам FDDI
В случае однократного обрыва кабеля между устройствами с двойным подключением сеть FDDI сможет продолжить нормальную работу за счет автоматической реконфигурации внутренних путей передачи кадров между портами концентратора (рис. 3.19). Двукратный обрыв кабеля приведет к образованию двух изолированных сетей FDDI. При обрыве кабеля, идущего к станции с одиночным подключением, она становится отрезанной от сети, а кольцо продолжает работать за счет реконфигурации внутреннего пути в концентраторе - порт М, к которому была подключена данная станция, будет исключен из общего пути.

Рис. 3.19. Реконфигурация сети FDDI при обрыве провода
Для сохранения работоспособности сети при отключении питания в станциях с двойным подключением, то есть станциях DAS, последние должны быть оснащены оптическими обходными переключателями (Optical Bypass Switch), которые создают обходной путь для световых потоков при исчезновении питания, которое они получают от станции.
И наконец, станции DAS или концентраторы DAC можно подключать к двум портам М одного или двух концентраторов, создавая древовидную структуру с основными и резервными связями. По умолчанию порт В поддерживает основную связь, а порт А - резервную. Такая конфигурация называется подключением Dual Homing
Отказоустойчивость поддерживается за счет постоянного слежения уровня SMT концентраторов и станций за временными интервалами циркуляции маркера и кадров, а также за наличием физического соединения между соседними портами в сети. В сети FDDI нет выделенного активного монитора - все станции и концентраторы равноправны, и при обнаружении отклонений от нормы они начинают процесс повторной инициализации сети, а затем и ее реконфигурации.
Реконфигурация внутренних путей в концентраторах и сетевых адаптерах выполняется специальными оптическими переключателями, которые перенаправляют световой луч и имеют достаточно сложную конструкцию.
Отключение портов
Очень полезной при эксплуатации сети является способность концентратора отключать некорректно работающие порты, изолируя тем самым остальную часть сети от возникших в узле проблем. Эту функцию называют автосегментацией (autopartitioning).
Для концентратора FDDI эта функция для многих ошибочных ситуаций является основной, так как определена в протоколе. В то же время для концентратора Ethernet или Token Ring функция автосегментации для многих ситуаций является дополнительной, так как стандарт не описывает реакцию концентратора на эту ситуацию. Основной причиной отключения порта в стандартах Ethernet и Fast Ethernet является отсутствие ответа на последовательность импульсов link test, посылаемых во все порты каждые 16 мс. В этом случае неисправный порт переводится в состояние «отключен», но импульсы link test будут продолжать посылаться в порт с тем, чтобы при восстановлении устройства работа с ним была продолжена автоматически.
Рассмотрим ситуации, в которых концентраторы Ethernet и Fast Ethernet выполняют отключение порта.
Ошибки на уровне кадра. Если интенсивность прохождения через порт кадров, имеющих ошибки, превышает заданный порог, то порт отключается, а затем, при отсутствии ошибок в течение заданного времени, включается снова. Такими ошибками могут быть: неверная контрольная сумм, неверная длина кадра (больше 1518 байт или меньше 64 байт), неоформленный заголовок кадра.
Множественные коллизии. Если концентратор фиксирует, что источником коллизии был один и тот же порт 60 раз подряд, то порт отключается. Через некоторое время порт снова будет включен.
Затянувшаяся передача (jabber).
Как и сетевой адаптер, концентратор контролирует время прохождения одного кадра через порт. Если это время превышает время передачи кадра максимальной длины в 3 раза, то порт отключается.
Отличия локальных сетей от глобальных
Рассмотрим основные отличия локальных сетей от глобальных более детально. Так как в последнее время эти отличия становятся все менее заметными, то будем считать, что в данном разделе мы рассматриваем сети конца 80-х годов, когда эти отличия проявлялись весьма отчетливо, а современные тенденции сближения технологий локальных и глобальных сетей будут рассмотрены в следующем разделе.
Протяженность, качество и способ прокладки линий связи. Класс локальных вычислительных сетей по определению отличается от класса глобальных сетей небольшим расстоянием между узлами сети. Это в принципе делает возможным использование в локальных сетях качественных линий связи: коаксиального кабеля, витой пары, оптоволоконного кабеля, которые не всегда доступны (из-за экономических ограничений) на больших расстояниях, свойственных глобальным сетям, В глобальных сетях часто применяются уже существующие линии связи (телеграфные или телефонные), а в локальных сетях они прокладываются заново.
Сложность методов передачи и оборудования. В условиях низкой надежности физических каналов в глобальных сетях требуются более сложные, чем в локальных сетях, методы передачи данных и соответствующее оборудование. Так, в глобальных сетях широко применяются модуляция, асинхронные методы, сложные методы контрольного суммирования, квитирование и повторные передачи искаженных кадров. С другой стороны, качественные линии связи в локальных сетях позволили упростить процедуры передачи данных за счет применения немодулированных сигналов и отказа от обязательного подтверждения получения пакета.
Скорость обмена данными. Одним из главных отличий локальных сетей от глобальных является наличие высокоскоростных каналов обмена данными между компьютерами, скорость которых (10,16и100 Мбит/с) сравнима со скоростями работы устройств и узлов компьютера - дисков, внутренних шин обмена данными и т. п. За счет этого у пользователя локальной сети, подключенного к удаленному разделяемому ресурсу (например, диску сервера), складывается впечатление, что он пользуется этим диском, как «своим».
Для глобальных сетей типичны гораздо более низкие скорости передачи данных - 2400,9600,28800,33600 бит/с, 56 и 64 Кбит/с и только на магистральных каналах - до 2 Мбит/с.
Разнообразие услуг. Локальные сети предоставляют, как правило, широкий набор услуг - это различные виды услуг файловой службы, услуги печати, услуги службы передачи факсимильных сообщений, услуги баз данных, электронная почта и другие, в то время как глобальные сети в основном предоставляют почтовые услуги и иногда файловые услуги с ограниченными возможностями - передачу файлов из публичных архивов удаленных серверов без предварительного просмотра их содержания.
Оперативность выполнения запросов. Время прохождения пакета через локальную сеть обычно составляет несколько миллисекунд, время же его передачи через глобальную сеть может достигать нескольких секунд. Низкая скорость передачи данных в глобальных сетях затрудняет реализацию служб для режима on-line, который является обычным для локальных сетей.
Разделение каналов. В локальных сетях каналы связи используются, как правило, совместно сразу несколькими узлами сети, а в глобальных сетях - индивидуально.
Использование метода коммутации пакетов. Важной особенностью локальных сетей является неравномерное распределение нагрузки. Отношение пиковой нагрузки к средней может составлять 100:1 и даже выше. Такой трафик обычно называют пульсирующим. Из-за этой особенности трафика в локальных сетях для связи узлов применяется метод коммутации пакетов, который для пульсирующего трафика оказывается гораздо более эффективным, чем традиционный для глобальных сетей метод коммутации каналов. Эффективность метода коммутации пакетов состоит в том, что сеть в целом передает в единицу времени больше данных своих абонентов. В глобальных сетях метод коммутации пакетов также используется, но наряду с ним часто применяется и метод коммутации каналов, а также некоммутируемые каналы - как унаследованные технологии некомпьютерных сетей.
Масштабируемость. «Классические» локальные сети обладают плохой масштабируемостью из-за жесткости базовых топологий, определяющих способ подключения станций и длину линии.При использовании многих базовых топологий характеристики сети резко ухудшаются при достижении определенного предела по количеству узлов или протяженности линий связи. Глобальным же сетям присуща хорошая масштабируемость, так как они изначально разрабатывались в расчете на работу с произвольными топологиями.
Отображение IP-адресов на локальные адреса
Одной из главных задач, которая ставилась при создании протокола IP, являлось обеспечение совместной согласованной работы в сети, состоящей из подсетей, в общем случае использующих разные сетевые технологии. Непосредственно с решением этой задачи связан уровень межсетевых интерфейсов стека TCP/IP. На этом уровне определяются уже рассмотренные выше спецификации упаковки (инкапсуляции) IP-пакетов в кадры локальных технологий. Кроме этого, уровень межсетевых интерфейсов должен заниматься также крайне важной задачей отображения IP-адресов в локальные адреса.
Для определения локального адреса по IP-адресу используется протокол разрешения адреса (Address Resolution Protocol, ARP). Протокол ARP работает различным образом в зависимости от того, какой протокол канального уровня работает в данной сети - протокол локальной сети (Ethernet, Token Ring, FDDI) с возможностью широковещательного доступа одновременно ко всем узлам сети или же протокол глобальной сети (Х.25, frame relay), как правило не поддерживающий широковещательный доступ. Существует также протокол, решающий обратную задачу - нахождение IP-адреса по известному локальному адресу. Он называется реверсивным ARP (Reverse Address Resolution Protocol, RARP) и используется при старте бездисковых станций, не знающих в начальный момент своего IP-адреса, но знающих адрес своего сетевого адаптера.
Необходимость в обращении к протоколу ARP возникает каждый раз, когда модуль IP передает пакет на уровень сетевых интерфейсов, например драйверу Ethernet. IP-адрес узла назначения известен модулю IP. Требуется на его основе найти МАС - адрес узла назначения.
Работа протокола ARP начинается с просмотра так называемой АКР-таблицы (табл. 5.5). Каждая строка таблицы устанавливает соответствие между IP-адресом и МАС - адресом. Для каждой сети, подключенной к сетевому адаптеру компьютера или к порту маршрутизатора, строится отдельная ARP-таблица.
Таблица 5.5. Пример ARP-таблицы

Поле «Тип записи» может содержать одно из двух значений - «динамический» или «статический».
Статические записи создаются вручную с помощью утилиты агр и не имеют срока устаревания, точнее, они существуют до тех пор, пока компьютер или маршрутизатор не будут выключены. Динамические же записи создаются модулем протокола ARP, использующим широковещательные возможности локальных сетевых технологий. Динамические записи должны периодически обновляться. Если запись не обновлялась в течение определенного времени (порядка нескольких минут), то она исключается из таблицы. Таким образом, в ARP - таблице содержатся записи не обо всех узлах сети, а только о тех, которые активно участвуют в сетевых операциях. Поскольку такой способ хранения информации называют кэшированием, ARP-таблицы иногда называют ARP-кэш.
В глобальных сетях администратору сети чаще всего приходится вручную формировать ARP-таблицы, в которых он задает, например, соответствие IP-адреса адресу узла сети Х.25, который имеет для протокола IP смысл локального адреса. В последнее время наметилась тенденция автоматизации работы протокола ARP и в глобальных сетях. Для этой цели среди всех маршрутизаторов, подключенных к какой-либо глобальной сети, выделяется специальный маршрутизатор, который ведет ARP-таблицу для всех остальных узлов и маршрутизаторов этой сети. При таком централизованном подходе для всех узлов и маршрутизаторов вручную нужно задать только IP-адрес и локальный адрес выделенного маршрутизатора. Затем каждый узел и маршрутизатор регистрирует свои адреса в выделенном маршрутизаторе, а при необходимости установления соответствия между IP-адресом и локальным адресом узел обращается к выделенному маршрутизатору с запросом и автоматически получает ответ без участия администратора. Работающий таким образом маршрутизатор называют ARP-сервером.
Итак, после того как модуль IP обратился к модулю ARP с запросом на разрешение адреса, происходит поиск в ARP-таблице указанного в запросе IP-адреса. Если таковой адрес в ARP-таблице отсутствует, то исходящий IP-пакет, для которого нужно было определить локальный адрес, ставится в очередь.
Далее протокол ARP формирует свой запрос (ARP-запрос), вкладывает его в кадр протокола канального уровня и рассылает запрос широковещательно.
Все узлы локальной сети получают ARP-запрос и сравнивают указанный там IP-адрес с собственным. В случае их совпадения узел формирует ARP-ответ, в котором указывает свой IP-адрес и свой локальный адрес, а затем отправляет его уже направленно, так как в ARP-запросе отправитель указывает свой локальный адрес. ARP-запросы и ответы используют один и тот же формат пакета. В табл. 5.6 приведены значения полей примера ARP-запроса для передачи по сети Ethernet.
Таблица 5.6. Пример ARP-запроса

В поле «тип сети» для сетей Ethernet указывается значение 1.
Поле «тип протокола» позволяет использовать протокол ARP не только для протокола IP, но и для других сетевых протоколов. Для IP значение этого поля равно 0800 is.
Длина локального адреса для протокола Ethernet равна 6 байт, а длина IP-адреса - 4 байт. В поле операции для ARP-запросов указывается значение 1, если это запрос, и 2, если это ответ.
Из этого запроса видно, что в сети Ethernet узел с IP-адресом 194.85.135.75 пытается определить, какой МАС - адрес имеет другой узел той же сети, сетевой адрес которого 194.85.135.65. Поле искомого локального адреса заполнено нулями.
Ответ присылает узел, опознавший свой IP-адрес. Если в сети нет машины с искомым IP-адресом, то ARP-ответа не будет. Протокол IP уничтожает IP-пакеты, направляемые по этому адресу. (Заметим, что протоколы верхнего уровня не могут отличить случай повреждения сети Ethernet от случая отсутствия машины с искомым IP-адресом.) В табл. 5.7 помещены значения полей ARP-ответа, который мог бы поступить на приведенный выше пример ARP-запроса.
Таблица 5.7. Пример ARP-ответа

Этот ответ получает машина, сделавшая ARP-запрос. Модуль ARP анализирует ARP-ответ и добавляет запись в свою ARP-таблицу (табл. 5.8). В результате обмена этими двумя ARP-сообшениями модуль IP-узла 194.85.135.75 определил, что IP-адресу 194.85.135.65 соответствует МАС - адрес 00E0F77F1920.Новая запись в ARP-таблице появляется автоматически, спустя несколько миллисекунд после того, как она потребовалась.
Таблица 5.8. Обновленная ARP-таблица

ПРИМЕЧАНИЕ Некоторые реализации IP и ARP не ставят IP-пакеты в очередь на время ожидания ARP-ответов. Вместо этого IP-пакет просто уничтожается, о его восстановление возлагается на модуль TCP или прикладной процесс, работающий через UDP. Такое восстановление выполняется с помощью тайм-аутов и повторных передач. Повторная передача сообщения проходит успешно, так как первая попытка уже вызвала заполнение ARP-таблицы.
Ответы на вопросы
Далее приведены ответы на вопросы, не требующие развернутого обсуждения.
Передача с установлением соединения и без установления соединения
При передаче кадров данных на канальном уровне используются как дейтаграммные процедуры, работающие без становления соединения (connectionless), так и процедуры с предварительным установлением логического соединения (connection-oriented).
При дейтаграммной передаче кадр посылается в сеть «без предупреждения», и никакой ответственности за его утерю протокол не несет (рис. 2.23, а). Предполагается, что сеть всегда готова принять кадр от конечного узла. Дейтаграммный метод работает быстро, так как никаких предварительных действий перед отправкой данных не выполняется. Однако при таком методе трудно организовать в рамках протокола отслеживание факта доставки кадра узлу назначения. Этот метод не гарантирует доставку пакета.

Рис. 2.23. Протоколы без установления соединения (а) и с установлением соединения (б)
Передача с установлением соединения более надежна, но требует больше времени для передачи данных и вычислительных затрат от конечных узлов.
В этом случае узлу-получателю отправляется служебный кадр специального формата с предложением установить соединение (рис. 2.23, б). Если узел-получатель согласен с этим, то он посылает в ответ другой служебный кадр, подтверждающий установление соединения и предлагающий для данного логического соединения некоторые параметры, например идентификатор соединения, максимальное значение поля данных кадров, которые будут использоваться в рамках данного соединения, и т. п. Узел-инициатор соединения может завершить процесс установления соединения отправкой третьего служебного кадра, в котором сообщит, что предложенные параметры ему подходят. На этом логическое соединение считается установленным, и в его рамках можно передавать информационные кадры с пользовательскими данными. После передачи некоторого законченного набора данных, например определенного файла, узел инициирует разрыв данного логического соединения, посылая соответствующий служебный кадр.
Заметим, что, в отличие от протоколов дейтаграммного типа, которые поддерживают только один тип кадра - информационный, протоколы, работающие по процедуре с установлением соединения, должны поддерживать несколько типов кадров - служебные, для установления (и разрыва) соединения, и информационные, переносящие собственно пользовательские данные.
Логическое соединение обеспечивает передачу данных как в одном направлении - от инициатора соединения, так и в обоих направлениях.
Процедура установления соединения может использоваться для достижения различных целей.
Для взаимной аутентификации либо пользователей, либо оборудования (маршрутизаторы тоже могут иметь имена и пароли, которые нужны для уверенности в том, что злоумышленник не подменил корпоративный маршрутизатор и не отвел поток данных в свою сеть для анализа).
Для согласования изменяемых параметров протокола: MTU, различных тайм-аутов и т. п.
Для обнаружения и коррекции ошибок. Установление логического соединения дает точку отсчета для задания начальных значений номеров кадров. При потере нумерованного кадра приемник, во-первых, получает возможность обнаружить этот факт, а во-вторых, он может сообщить передатчику, какой в точности кадр нужно передать повторно.
В некоторых технологиях процедуру установления логического соединения используют при динамической настройке коммутаторов сети для маршрутизации всех последующих кадров, которые будут проходить через сеть в рамках данного логического соединения. Так работают сети технологий Х.25, frame relay и АТМ.
Как видно из приведенного списка, при установлении соединения могут преследоваться разные цели, в некоторых случаях - несколько одновременно. В этой главе мы рассмотрим использование логического соединения для обнаружения и коррекции ошибок, а остальные случаи будут рассматриваться в последующих главах по мере необходимости.
Передача трафика IP через сети АТМ
Технология АТМ привлекает к себе общее внимание, так как претендует на роль всеобщего и очень гибкого транспорта, на основе которого строятся другие сети. И хотя технология АТМ может использоваться непосредственно для транспортировки сообщений протоколов прикладного уровня, пока она чаще переносит пакеты других протоколов канального и сетевого уровней (Ethernet, IP, IPX, frame relay, X.25), сосуществуя с ними, а не полностью заменяя. Поэтому протоколы и спецификации, которые определяют способы взаимодействия технологии АТМ с другими технологиями, очень важны для современных сетей. А так как протокол IP является на сегодня основным протоколом построения составных сетей, то стандарты работы IP через сети АТМ являются стандартами, определяющими взаимодействие двух наиболее популярных технологий сегодняшнего дня.
Протокол Classical IP (RFC 1577) является первым (по времени появления) протоколом, определившим способ работы интерсети IP в том случае, когда одна из промежуточных сетей работает по технологии АТМ. Из-за классической концепции подсетей протокол и получил свое название - Classical.
Одной из основных задач, решаемых протоколом Classical IP, является традиционная для IP-сетей задача - поиск локального адреса следующего маршрутизатора или конечного узла по его IP-адресу, то есть задача, возлагаемая в локальных сетях на протокол ARP. Поскольку сеть АТМ не поддерживает широковещательность, традиционный для локальных сетей способ широковещательных ARP-запросов здесь не работает. Технология АТМ, конечно, не единственная технология, в которой возникает такая проблема, - для обозначения таких технологий даже ввели специальный термин - «Нешироковещательные сети с множественным доступом» (Non-Broadcast networks with Multiple Access, NBMA). К сетям NBMA относятся, в частности, сети X.25 и frame relay.
В общем случае для нешироковещательных сетей стандарты TCP/IP определяют только ручной способ построения ARP-таблиц, однако для технологии АТМ делается исключение - для нее разработана процедура автоматического отображения IP-адресов на локальные адреса.
Такой особый подход к технологии АТМ объясняется следующими причинами. Сети NBMA (в том числе X.25 и frame relay) используются, как правило, как транзитные глобальные сети, к которым подключается ограниченное число маршрутизаторов, а для небольшого числа маршрутизаторов можно задать ARP-таблицу вручную. Технология АТМ отличается тем, что она применяется для построения не только глобальных, но и локальных сетей. В последнем случае размерность ARP-таблицы, которая должна содержать записи и о пограничных маршрутизаторах, и о множестве конечных узлов, может быть очень большой. К тому же, для крупной локальной сети характерно постоянное изменение состава узлов, а значит, часто возникает необходимость в корректировке таблиц. Все это делает ручной вариант решения задачи отображения адресов для сетей АТМ мало пригодным.
В соответствии со спецификацией Classical IP одна сеть АТМ может быть представлена в виде нескольких IP-подсетей, так называемых логических подсетей (Logical IP Subnet, LIS) (рис. 6.33). Все узлы одной LIS имеют общий адрес сети. Как и в классической IP-сети, весь трафик между подсетями обязательно проходит через маршрутизатор, хотя и существует принципиальная возможность передавать его непосредственно через коммутаторы АТМ, на которых построена сеть АТМ. Маршрутизатор имеет интерфейсы во всех LIS, на которые разбита сеть АТМ.

Рис. 6.33.
Логические IP-подсети в сети АТМ
ПРИМЕЧАНИЕ Подход спецификации Classical IP к подсетям напоминает технику виртуальных локальных сетей VLAN -там также вводятся ограничения на имеющуюся возможность связи через коммутаторы для узлов, принадлежащих разным VLAN.
В отличие от классических подсетей маршрутизатор может быть подключен к сети АТМ одним физическим интерфейсом, которому присваивается несколько IP-адресов в соответствии с количеством LIS в сети.
Решение о введении логических подсетей связано с необходимостью обеспечения традиционного разделения большой сети АТМ на независимые части, связность которых контролируется маршрутизаторами, как к этому привыкли сетевые интеграторы и администраторы.
Решение имеет и очевидный недостаток — маршрутизатор должен быть достаточно производительным для передачи высокоскоростного трафика АТМ между логическими подсетями, в противном случае он станет узким местом сети. В связи с повышенными требованиями по производительности, предъявляемыми сетями АТМ к маршрутизаторам, многие ведущие производители разрабатывают или уже разработали модели маршрутизаторов с общей производительностью в несколько десятков миллионов пакетов в секунду.
Все конечные узлы конфигурируются традиционным образом — для них задается их собственный IP-адрес, маска и IP-адрес маршрутизатора по умолчанию. Кроме того, задается еще один дополнительный параметр — адрес АТМ (или номер VPI/VCI для случая использования постоянного виртуального канала, то есть PVC) так называемого сервера ATMARP. Введение центрального сервера, который поддерживает общую базу данных для всех узлов сети, — это типичный прием для работы через нешироковещательную сеть. Этот прием используется во многих протоколах, в частности в протоколе LAN Emulation, рассматриваемом далее.
Каждый узел использует адрес АТМ сервера ATMARP, чтобы выполнить обычный запрос ARP. Этот запрос имеет формат, очень близкий к формату запроса протокола ARP из стека TCP/IP. Длина аппаратного адреса в нем определена в 20 байт, что соответствует длине адреса АТМ. В каждой логической подсети имеется свой сервер ATMARP, так как узел может обращаться без посредничества маршрутизатора только к узлам своей подсети. Обычно роль сервера ATMARP выполняет маршрутизатор, имеющий интерфейсы во всех логических подсетях.
При поступлении первого запроса ARP от конечного узла сервер сначала направляет ему встречный инверсный запрос ATMARP, чтобы выяснить IP- и АТМ- адреса этого узла. Этим способом выполняется регистрация каждого узла в сервере ATMARP, и сервер получает возможность автоматически строить базу данных соответствия IP- и АТМ - адресов. Затем сервер пытается выполнить запрос ATMARP узла путем просмотра своей базы.Если искомый узел уже зарегистрировался в ней и он принадлежит той же логической подсети, что и запрашивающий узел, то сервер отправляет в качестве ответа запрашиваемый адрес. В противном случае дается негативный ответ (такой тип ответа в обычном широковещательном варианте протокола ARP не предусматривается).
Конечный узел, получив ответ ARP, узнает АТМ-адрес своего соседа по логической подсети и устанавливает с ним коммутируемое виртуальное соединение. Если же он запрашивал АТМ-адрес маршрутизатора по умолчанию, то он устанавливает с ним соединение, чтобы передать IP-пакет в другую сеть.
Для передачи IP-пакетов через сеть АТМ спецификация Classical IP определяет использование протокола уровня адаптации AAL5, при этом спецификация ничего не говорит ни о параметрах трафика и качества обслуживания, ни о требуемой категории услуг CBR, rtVBR, nrtVBR или UBR.
Первые локальные сети
В начале 70-х годов произошел технологический прорыв в области производства компьютерных компонентов - появились большие интегральные схемы. Их сравнительно невысокая стоимость и высокие функциональные возможности привели к созданию мини-компьютеров, которые стали реальными конкурентами мэйнфреймов. Закон Гроша перестал соответствовать действительности, так как десяток мини-компьютеров выполнял некоторые задачи (как правило, хорошо распараллеливаемые) быстрее одного мэйнфрейма, а стоимость такой мини-компьютерной системы была меньше.
Даже небольшие подразделения предприятий получили возможность покупать для себя компьютеры. Мини-компьютеры выполняли задачи управления технологическим оборудованием, складом и другие задачи уровня подразделения предприятия. Таким образом, появилась концепция распределения компьютерных ресурсов по всему предприятию. Однако при этом все компьютеры одной организации по-прежнему продолжали работать автономно (рис. 1.3).
Но шло время, потребности пользователей вычислительной техники росли, им стало недостаточно собственных компьютеров, им уже хотелось получить возможность обмена данными с другими близко расположенными компьютерами. В ответ на эту потребность предприятия и организации стали соединять свои мини-компьютеры вместе и разрабатывать программное обеспечение, необходимое для их взаимодействия. В результате появились первые локальные вычислительные сети (рис. 1.4). Они еще во многом отличались от современных локальных сетей, в первую очередь - своими устройствами сопряжения. На первых порах для соединения компьютеров друг с другом использовались самые разнообразные нестандартные устройства со своим способом представления данных на линиях связи, своими типами кабелей и т. п. Эти устройства могли соединять только те типы компьютеров, для которых были разработаны, - например, мини-компьютеры PDP-11 с мэйнфреймом IBM 360 или компьютеры «Наири» с компьютерами «Днепр». Такая ситуация создала большой простор для творчества студентов - названия многих курсовых и дипломных проектов начинались тогда со слов «Устройство сопряжения...».

Рис. 1.3. Автономное использование нескольких мини-компьютеров на одном предприятии

Рис. 1.4. Различные типы связей в первых локальных сетях.
Платформенный подход
При построении систем управления крупными локальными и корпоративными сетями обычно используется платформенный подход, когда индивидуальные программы управления разрабатываются не «с нуля», а используют службы и примитивы, предоставляемые специально разработанным для этих целей программным продуктом - платформой. Примерами платформ для систем управления являются такие известные продукты, как HP OpenView, SunNet Manager и Sun Soltice, Cdbletron Spectrum, IMB/Tivoli TMN10.
Эти платформы создают общую операционную среду для приложений системы управления точно так же, как универсальные операционные системы, такие как Unix или Windows NT, создают операционную среду для приложений любого типа, таких как MS Word, Oracle и т. п. Платформа обычно включает поддержку протоколов взаимодействия менеджера с агентами - SNMP и реже CMIP, набор базовых средств для построения менеджеров и агентов, а также средства графического интерфейса для создания консоли управления. В набор базовых средств обычно входят функции, необходимые для построения карты сети, средства фильтрации сообщений от агентов, средства ведения базы данных. Набор интерфейсных функций платформы образует интерфейс прикладного программирования (API) системы управления. Пользуясь этим API, разработчики из третьих фирм создают законченные системы управления, которые могут управлять специфическим оборудованием в соответствии с пятью основными группами функций.
Обычно платформа управления поставляется с каким-либо универсальным менеджером, который может выполнять некоторые базовые функции управления без программирования. Чаще всего к этим функциям относятся функции построения карты сети (группа Configuration Management), а также функции отображения состояния управляемых устройств и функции фильтрации сообщений об ошибках (группа Fault Management). Например, одна из наиболее популярных платформ HP OpenView поставляется с менеджером Network Node Manager, который выполняет перечисленные функции.
Чем больше функций выполняет платформа, тем лучше. В том числе и таких, которые нужны для разработки любых аспектов работы приложений, прямо не связанных со спецификой управления. В конце концов, приложения системы управления - это прежде всего приложения, а потом уже приложения системы управления. Поэтому полезны любые средства, предоставляемые платформой, которые ускоряют разработку приложений вообще и распределенных приложений в частности.
Компании, которые производят коммуникационное оборудование, разрабатывают дополнительные менеджеры для популярных платформ, которые выполняют функции управления оборудованием данного производителя более полно. Примерами таких менеджеров могут служить менеджеры системы Optivity компании Bay Networks и менеджеры системы Trancsend компании 3Com, которые могут работать в среде платформ HP OpenView и SunNet Manager.
Почта
Почта является еще одним видом удаленного доступа. Почтовые шлюзы, доступные по коммутируемым телефонным линиям, и клиентское почтовое обеспечение удаленного доступа могут быть достаточными для удовлетворения потребностей многих обычных пользователей. Такие почтовые шлюзы позволяют удаленным пользователям или даже удаленным офисам звонить в почтовую систему центрального отделения, обмениваться входящими и исходящими сообщениями и файлами, а затем отключаться.
Продукты, предназначенные для этих целей, варьируются от клиентских программ для одного пользователя, таких как cc:mail Mobile фирмы Lotus, до полномасштабных шлюзов, которые организуют почтовый обмен между удаленными серверами и корпоративной локальной сетью (например, Exchange компании Microsoft).
Почтовые шлюзы могут быть полезны в случае, когда количество данных, которыми обмениваются удаленные пользователи с центральным офисом, не очень большое. Из-за того, что среднее время сессии пользователь - шлюз сравнительно невелико, шлюз центральной сети не должен поддерживать большое количество телефонных линий. Обычно почтовое соединение легко устанавливается, а стоимость программного обеспечения шлюза незначительна.
Шлюзы работают в автоматическом режиме без вмешательства человека. Если в удаленном офисе работают один или два сотрудника и им не нужен доступ к корпоративным данным в реальном масштабе времени, то почтовый шлюз может быть хорошим решением. Некоторые приложения автоматически принимают запросы в виде писем электронной почты, а затем посылают в таком же виде ответы. Так, например, работают многие СУБД.
Не только почта, но и другие приложения, написанные для локальной вычислительной сети, могут иметь специфические программные модули, предназначенные для удаленных соединений. Такие программы устанавливают соединения между собой с помощью нестандартных протоколов и часто увеличивают эффективность соединения за счет специальных приемов, например путем передачи только обновлений между удаленным компьютером и хостом. Примером продуктов этого класса являются программные системы коллективной работы.
Поддержка алгоритма Spanning Tree
Алгоритм покрывающего дерева - Spanning Tree Algorithm (STA) позволяет коммутаторам автоматически определять древовидную конфигурацию связей в сети при произвольном соединения портов между собой. Как уже отмечалось, для нормальной работы коммутатора требуется отсутствие замкнутых маршрутов в сети. Эти маршруты могут создаваться администратором специально для образования резервных связей или же возникать случайным образом, что вполне возможно, если сеть имеет многочисленные связи, а кабельная система плохо структурирована или документирована.
Поддерживающие алгоритм STA коммутаторы автоматически создают активную древовидную конфигурацию связей (то есть связную конфигурацию без петель) на множестве всех связей сети. Такая конфигурация называется покрывающим деревом - Spanning Tree (иногда ее называют основным деревом), и ее название дало имя всему алгоритму. Алгоритм Spanning Tree описан в стандарте IEEE 802.1D, том же стандарте, который определяет принципы работы прозрачных мостов.
Коммутаторы находят покрывающее дерево адаптивно, с помощью обмена служебными пакетами. Реализация в коммутаторе алгоритма STA очень важна для работы в больших сетях - если коммутатор не поддерживает этот алгоритм, то администратор должен самостоятельно определить, какие порты нужно перевести в заблокированное состояние, чтобы исключить петли. К тому же при отказе какого-либо кабеля, порта или коммутатора администратор должен, во-первых, обнаружить факт отказа, а во-вторых, ликвидировать последствия отказа, переведя резервную связь в рабочий режим путем активизации некоторых портов. При поддержке коммутаторами сети протокола Spanning Tree отказы обнаруживаются автоматически, за счет постоянного тестирования связности сети служебными пакетами. После обнаружения потери связности протокол строит новое покрывающее дерево, если это возможно, и сеть автоматически восстанавливает работоспособность.
Алгоритм Spanning Tree определяет активную конфигурацию сети за три этапа.
Сначала в сети определяется корневой коммутатор (root switch), от которого строится дерево.
Корневой коммутатор может быть выбран автоматически или назначен администратором. При автоматическом выборе корневым становится коммутатор с меньшим значением МАС - адреса его блока управления.
Затем, на втором этапе, для каждого коммутатора определяется корневой порт (root port) - это порт, который имеет по сети кратчайшее расстояние до корневого коммутатора (точнее, до любого из портов корневого коммутатора).
И наконец, на третьем этапе для каждого сегмента сети выбирается так называемый назначенный порт (designated port) - это порт, который имеет кратчайшее расстояние от данного сегмента до корневого коммутатора. После определения корневых и назначенных портов каждый коммутатор блокирует остальные порты, которые не попали в эти два класса портов. Можно математически доказать, что при таком выборе активных портов в сети исключаются петли и оставшиеся связи образуют покрывающее дерево (если оно может быть построено при существующих связях в сети).
Понятие расстояния играет важную роль в построении покрывающего дерева. Именно по этому критерию выбирается единственный порт, соединяющий каждый коммутатор с корневым коммутатором, и единственный порт, соединяющий каждый сегмент сети с корневым коммутатором.
На рис. 4.38 показан пример построения конфигурации покрывающего дерева для сети, состоящей из 5 сегментов и 5 коммутаторов. Корневые порты закрашены темным цветом, назначенные порты не закрашены, а заблокированные порты перечеркнуты. В активной конфигурации коммутаторы 2 и 4 не имеют портов, передающих кадры данных, поэтому они закрашены как резервные.

Рис. 4.38. Построение покрывающего дерева сети по алгоритму STA
Расстояние до корня определяется как суммарное условное время на передачу одного бита данных от порта данного коммутатора до порта корневого коммутатора. При этом считается, что время внутренних передач данных (с порта на порт) коммутатором пренебрежимо мало, а учитывается только время на передачу данных по сегментам сети, соединяющим коммутаторы.
Условное время сегмента рассчитывается как время, затрачиваемое на передачу одного бита информации в 10 наносекундных единицах между непосредственно связанными по сегменту сети портами. Так, для сегмента Ethernet это время равно 10 условным единицам, а для сегмента Token Ring 16 Мбит/с - 6,25. (Алгоритм STA не связан с каким-либо определенным стандартом канального уровня, он может применяться к коммутаторам, соединяющим сети различных технологий.)
В приведенном примере предполагается, что все сегменты работают на одной скорости, поэтому они имеют одинаковые условные расстояния, которые поэтому не показаны на рисунке.
Для автоматического определения начальной активной конфигурации дерева все коммутаторы сети после их инициализации начинают периодически обмениваться специальными пакетами, называемыми протокольными блоками данных моста - BPDU (Bridge Protocol Data Unit),
что отражает факт первоначальной разработки алгоритма STA для мостов.
Пакеты BPDU помещаются в поле данных кадров канального уровня, например кадров Ethernet или FDDI. Желательно, чтобы все коммутаторы поддерживали общий групповой адрес, с помощью которого кадры, содержащие пакеты BPDU, могли бы одновременно передаваться всем коммутаторам сети. Иначе пакеты BPDU рассылаются широковещательно.
Поля пакета BPDU перечислены ниже.
Идентификатор версии протокола STA - 2 байта. Коммутаторы должны поддерживать одну и ту же версию протокола STA, иначе может установиться активная конфигурация с петлями.
Тип BPDU - 1 байт. Существуют два типа BPDU - конфигурационный BPDU, то есть заявка на возможность стать корневым коммутатором, на основании которой происходит определение активной конфигурации, и BPDU уведомления о реконфигурации, которое посылается коммутатором, обнаружившим событие, требующее проведения реконфигурации - отказ линии связи, отказ порта, изменение приоритетов коммутатора или портов.
Флаги - 1 байт. Один бит содержит флаг изменения конфигурации, второй -флаг подтверждения изменения конфигурации.
Идентификатор корневого коммутатора - 8 байт.
Расстояние до корня - 2 байта.
Идентификатор коммутатора - 8 байт.
Идентификатор порта - 2 байта.
Время жизни сообщения - 2 байта. Измеряется в единицах по 0, 5 с, служит для выявления устаревших сообщений. Когда пакет BPDU проходит через коммутатор, тот добавляет ко времени жизни пакета время его задержки данным коммутатором.
Максимальное время жизни сообщения - 2 байта. Если пакет BPDU имеет время жизни, превышающее максимальное, то он игнорируется коммутаторами.
Интервал hello, через который посылаются пакеты BPDU.
Задержка смены состояний - 2 байта. Задержка определяет минимальное время перехода портов коммутатора в активное состояние. Такая задержка необходима, чтобы исключить возможность временного возникновения петель при неодновременной смене состояний портов во время реконфигурации. У пакета BPDU уведомления о реконфигурации отсутствуют все поля, кроме двух первых.
Идентификаторы коммутаторов состоят из 8 байт, причем младшие 6 являются МАС - адресом блока управления коммутатора. Старшие 2 байта в исходном состоянии заполнены нулями, но администратор может изменить значение этих байтов, тем самым назначив определенный коммутатор корневым.
После инициализации каждый коммутатор сначала считает себя корневым. Поэтому он начинает через интервал hello генерировать через все свои порты сообщения BPDU конфигурационного типа. В них он указывает свой идентификатор в качестве идентификатора корневого коммутатора (и в качестве идентификатора данного коммутатора также), расстояние до корня устанавливается в 0, а в качестве идентификатора порта указывается идентификатор того порта, через который передается BPDU. Как только коммутатор получает BPDU, в котором имеется идентификатор корневого коммутатора, со значением, меньшим его собственного, он перестает генерировать свои собственные кадры BPDU, а начинает ретранслировать только кадры нового претендента на звание корневого коммутатора. На рис. 4.38 у коммутатора 1 идентификатор имеет наименьшее значение, раз он стал в результате обмена кадрами корневым.
При ретрансляции кадров каждый коммутатор наращивает расстояние до корня, указанное в пришедшем BPDU, на условное время сегмента, по которому принят данный кадр. Тем самым в кадре BPDU, по мере прохождения через коммутаторы, накапливается расстояние до корневого коммутатора. Если считать, что все сегменты рассматриваемого примера являются сегментами Ethernet, то коммутатор 2, приняв от коммутатора BPDU по сегменту 1 с расстоянием, равным 0, наращивает его на 10 единиц.
Ретранслируя кадры, каждый коммутатор для каждого своего порта запоминает минимальное расстояние до корня, встретившееся во всех принятых этим портом кадрах BPDU. При завершении процедуры установления конфигурации покрывающего дерева (по времени) каждый коммутатор находит свой корневой порт - это порт, для которого минимальное расстояние до корня оказалось меньше, чем у других портов. Так, коммутатор 3 выбирает порт А в качестве корневого, поскольку по порту А минимальное расстояние до корня равно 10 (BPDU с таким расстоянием принят от корневого коммутатора через сегмент 1). Порт В коммутатора 3 обнаружил в принимаемых кадрах минимальное расстояние в 20 единиц - это соответствовало случаю прохождения кадра от порта В корневого моста через сегмент 2, затем через мост 4 и сегмент 3.
Кроме корневого порта коммутаторы распределенным образом выбирают для каждого сегмента сети назначенный порт. Для этого они исключают из рассмотрения свой корневой порт (для сегмента, к которому он подключен, всегда существует другой коммутатор, который ближе расположен к корню), а для всех своих оставшихся портов сравнивают принятые по ним минимальные расстояния до корня с расстоянием до корня своего корневого порта. Если у какого-либо своего порта принятые им расстояния до корня больше, чем расстояние маршрута, пролегающего через свой корневой порт, то это значит, что для сегмента, к которому подключен данный порт, кратчайшее расстояние к корневому коммутатору ведет именно через данный порт. Коммутатор делает все свои порты, у которых такое условие выполняется, назначенными.
Если в процессе выбора корневого порта или назначенного порта несколько портов оказываются равными по критерию кратчайшего расстояния до корневого коммутатора, то выбирается порт с наименьшим идентификатором.
В качестве примера рассмотрим выбор корневого порта для коммутатора 2 и назначенного порта для сегмента 2. Мост 2 при выборе корневого порта столкнулся с ситуацией, когда порт А и порт В имеют равное расстояние до корня - по 10 единиц (порт А принимает кадры от порта В корневого коммутатора через один промежуточный сегмент - сегмент 1, а порт В принимает кадры от порта А корневого коммутатора также через один промежуточный сегмент - через сегмент 2). Идентификатор А имеет меньшее числовое значение, чем В (в силу упорядоченности кодов символов), поэтому порт А стал корневым портом коммутатора 2.
При проверке порта В на случай, не является ли он назначенным для сегмента 2, коммутатор 2 обнаружил, что через этот порт он принимал кадры с указанным в них минимальным расстоянием 0 (это были кадры от порта В корневого коммутатора 1). Так как собственный корневой порт у коммутатора 2 имеет расстояние до корня 10, то порт В не является назначенным для сегмента 2.
Затем все порты, кроме корневого и назначенных, переводятся каждым коммутатором в заблокированное состояние. На этом построение покрывающего дерева заканчивается.
В процессе нормальной работы корневой коммутатор продолжает генерировать служебные кадры BPDU, а остальные коммутаторы продолжают их принимать своими корневыми портами и ретранслировать назначенными. Если у коммутатора нет назначенных портов, как у коммутаторов 2 и 4, то они все равно продолжают принимать участие в работе протокола Spanning Tree, принимая служебные кадры корневым портом. Если по истечении тайм-аута корневой порт любого коммутатора сети не получает служебный кадр BPDU, то он инициализирует новую процедуру построения покрывающего дерева, оповещая об этом другие коммутаторы BPDU уведомления о реконфигурации. Получив такой кадр, все коммутаторы начинают снова генерировать BDPU конфигурационного типа, в результате чего устанавливается новая активная конфигурация.
Поддержка качества обслуживания
Технология frame relay благодаря особому подходу гарантированно обеспечивает основные параметры качества транспортного обслуживания, необходимые при объединении локальных сетей.
Вместо приоритезации трафика используется процедура заказа качества обслуживания при установлении соединения, отсутствующая в сетях Х.25 и пробивающая себе дорогу в сетях TCP/IP в форме экспериментального протокола RSVP, который пока не поддерживается поставщиками услуг Internet. В технологии frame relay заказ и поддержание качества обслуживания встроен в технологию.
Для каждого виртуального соединения определяется несколько параметров, влияющих на качество обслуживания.
CIR (Committed Information Rate) - согласованная информационная скорость, с которой сеть будет передавать данные пользователя.
Be (Committed Burst Size) - согласованный объем пульсации, то есть максимальное количество байтов, которое сеть будет передавать от этого пользователя за интервал времени Т.
Be (Excess Burst Size) - дополнительный объем пульсации, то есть максимальное количество байтов, которое сеть будет пытаться передать сверх установленного значения Вс за интервал времени Т.
Если эти величины определены, то время Т определяется формулой: Т =Bc/CIR. Можно задать значения CIR и Т, тогда производной величиной станет величина всплеска трафика Вс.
Соотношение между параметрами CIR, Be, Be и Т иллюстрирует рис. 6.27.
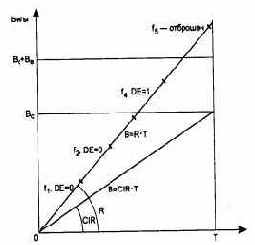
Рис. 6.27. Реакция сети на поведение пользователя: R - скорость канала доступа; f1-f4
кадры
Гарантий по задержкам передачи кадров технология frame relay не дает, оставляя эту услугу сетям АТМ.
Основным параметром, по которому абонент и сеть заключают соглашение при установлении виртуального соединения, является согласованная скорость передачи данных. Для постоянных виртуальных каналов это соглашение является частью контракта на пользование услугами сети. При установлении коммутируемого виртуального канала соглашение о качестве обслуживания заключается автоматически с помощью протокола Q.931/933 — требуемые параметры CIR, Вс и Be передаются в пакете запроса на установление соединения.
Так как скорость передачи данных измеряется на каком-то интервале времени, то интервал Т и является таким контрольным интервалом, на котором проверяются условия соглашения. В общем случае пользователь не должен за этот интервал передать в сеть данные со средней скоростью, превосходящей CIR. Если же он нарушает соглашение, то сеть не только не гарантирует доставку кадра, но помечает этот кадр признаком DE(Discard Eligibility), равным 1, то есть как кадр, подлежащий удалению. Однако кадры, отмеченные таким признаком, удаляются из сети только в том случае, если коммутаторы сети испытывают перегрузки. Если же перегрузок нет, то кадры с признаком DE=1 доставляются адресату.
Такое щадящее поведение сети соответствует случаю, когда общее количество данных, переданных пользователем в сеть за период Т, не превышает объема Вс+Ве. Если же этот порог превышен, то кадр не помечается признаком DE, а немедленно удаляется из сети.
На рис. 6.27 изображен случай, когда за интервал времени Т в сеть по виртуальному каналу поступило 5 кадров. Средняя скорость поступления информации в сеть составила на этом интервале R бит/с, и она оказалась выше CIR. Кадры f1, f2 и f3 доставили в сеть данные, суммарный объем которых не превысил порог Вс, поэтому эти кадры ушли дальше транзитом с признаком DE=0. Данные кадра 4, прибавленные к данным кадров f1, f2 и f3, уже превысили порог Вс, но еще не превысили порога Вс+Ве, поэтому кадр f4 также ушел дальше, но уже с признаком DE=1. Данные кадра f5, прибавленные к данным предыдущих кадров, превысили порог Вс+Ве, поэтому этот кадр был удален из сети.
Для контроля соглашения о параметрах качества обслуживания все коммутаторы сети frame relay выполняют так называемый алгоритм «дырявого ведра» (Leaky Bucket). Алгоритм использует счетчик С поступивших от пользователя байт. Каждые Т секунд этот счетчик уменьшается на величину Вс (или же сбрасывается в 0, если значение счетчика меньше, чем Вс). Все кадры, данные которых не увеличили значение счетчика свыше порога Вс, пропускаются в сеть со значением признака DE=0.
Кадры, данные которых привели к значению счетчика, большему Вс, но меньшему Вс+Ве, также передаются в сеть, но с признаком DE=1. И наконец, кадры, которые привели к значению счетчика, большему Вс+Ве, отбрасываются коммутатором.
Пользователь может договориться о включении не всех параметров качества обслуживания на данном виртуальном канале, а только некоторых.
Например, можно использовать только параметры CIR и Вс. Этот вариант дает более качественное обслуживание, так как кадры никогда не отбрасываются коммутатором сразу. Коммутатор только помечает кадры, которые превышают порог Вс за время Т, признаком DE=1. Если сеть не сталкивается с перегрузками, то кадры такого канала всегда доходят до конечного узла, даже если пользователь постоянно нарушает договор с сетью.
Популярен еще один вид заказа на качество обслуживания, при котором оговаривается только порог Be, а скорость CIR полагается равной нулю. Все кадры такого канала сразу же отмечаются признаком DE=1, но отправляются в сеть, а при превышении порога Be
они отбрасываются. Контрольный интервал времени Т в этом случае вычисляется как Be/R, где R — скорость доступа канала.
На рис. 6.28 приведен пример сети frame relay с пятью удаленными региональными отделениями корпорации. Обычно доступ к сети осуществляется каналами с большей чем CIR пропускной способностью. Но при этом пользователь платит не за пропускную способность канала, а за заказанные величины CIR, Bc и Be. Так, при использовании в качестве канала доступа канала Т1 и заказа службы со скоростью CIR, равной 128 Кбит/с, пользователь будет платить только за скорость 128 Кбит/с, а скорость канала Т1 в 1,544 Мбит/с будет влиять на верхнюю границу возможной пульсации Вс+Ве.

Рис. 6.28.
Пример использования сети frame relay
Параметры качества обслуживания могут быть различными для разных направлений виртуального канала. Так, на рис. 6.28 абонент 1 соединен с абонентом 2виртуальным каналом с DLCI=136. При направлении от абонента 1 к абоненту 2 канал имеет среднюю скорость 128 Кбит/с с пульсациями Вс=256 Кбит (интервал Т составил 1 с) и Ве=64 Кбит.
А при передаче кадров в обратном направлении средняя скорость уже может достигать значения 256 Кбит/с с пульсациями Вс=512 Кбит и Ве=128 Кбит.
Механизм заказа средней пропускной способности и максимальной пульсации является основным механизмом управления потоками кадров в сетях frame relay. Соглашения должны заключаться таким образом, чтобы сумма средних скоростей виртуальных каналов не превосходила возможностей портов коммутаторов. При заказе постоянных каналов за это отвечает администратор, а при установлении коммутируемых виртуальных каналов - программное обеспечение коммутаторов. При правильно взятых на себя обязательствах сеть борется с перегрузками путем удаления кадров с признаком DE=1 и кадров, превысивших порог Вс+Ве.
Тем не менее в технологии frame relay определен еще и дополнительный (необязательный) механизм управления кадрами. Это механизм оповещения конечных пользователей о том, что в коммутаторах сети возникли перегрузки (переполнение необработанными кадрами). Бит FECN (Forward Explicit Congestion Bit) кадра извещает об этом принимающую сторону. На основании значения этого бита принимающая сторона должна с помощью протоколов более высоких уровней (TCP/IP, SPX и т. п.) известить передающую сторону о том, что та должна снизить интенсивность отправки пакетов в сеть.
Бит BECN (Backward Explicit Congestion Bit) извещает о переполнении в сети передающую сторону и является рекомендацией немедленно снизить темп передачи. Бит BECN обычно отрабатывается на уровне устройств доступа к сети frame relay - маршрутизаторов, мультиплексоров и устройств CSU/DSU. Протокол frame relay не требует от устройств, получивших кадры с установленными битами FECN и BECN, немедленного прекращения передачи кадров в данном направлении, как того требуют кадры RNR сетей Х.25. Эти биты должны служить указанием для протоколов более высоких уровней (TCP, SPX, NCP и т. п.) о снижении темпа передачи пакетов. Так как регулирование потока инициируется в разных протоколах по-разному - как принимающей стороной, так и передающей, - то разработчики протоколов frame relay учли оба направления снабжения предупреждающей информацией о переполнении сети.
В общем случае биты FECN и BECN могут игнорироваться. Но обычно устройства доступа к сети frame relay (Frame Relay Access Device, FRAD) отрабатывают по крайней мере признак BECN.
При создании коммутируемого виртуального канала параметры качества обслуживания передаются в сеть с помощью протокола Q.931. Этот протокол устанавливает виртуальное соединение с помощью нескольких служебных пакетов.
Абонент сети frame relay, который хочет установить коммутируемое виртуальное соединение с другим абонентом, должен передать в сеть по каналу D сообщение SETUP, которое имеет несколько параметров, в том числе:
DLCI;
адрес назначения (в формате Е.164, Х.121 или ISO 7498);
максимальный размер кадра в данном виртуальном соединении;
запрашиваемое значение CIR для двух направлений;
запрашиваемое значение Вс для двух направлений;
запрашиваемое значение Be
для двух направлений.
Коммутатор, с которым соединен пользователь, сразу же передает пользователю пакет CALL PROCEEDING - вызов обрабатывается. Затем он анализирует параметры, указанные в пакете, и если коммутатор может их удовлетворить (располагая, естественно, информацией о том, какие виртуальные каналы на каждом порту он уже поддерживает), то пересылает сообщение SETUP следующему коммутатору. Следующий коммутатор выбирается по таблице маршрутизации. Протокол автоматического составления таблиц маршрутизации для технологии frame relay не определен, поэтому может использоваться фирменный протокол производителя оборудования или же ручное составление таблицы. Если все коммутаторы на пути к конечному узлу согласны принять запрос, то пакет SETUP передается в конечном счете вызываемому абоненту. Вызываемый абонент немедленно передает в сеть пакет CALL PROCEEDING и начинает обрабатывать запрос. Если запрос принимается, то вызываемый абонент передает в сеть новый пакет - CONNECT, который проходит в обратном порядке по виртуальному пути. Все коммутаторы должны отметить, что данный виртуальный канал принят вызываемым абонентом.При поступлении сообщения CONNECT вызывающему абоненту он должен передать в сеть пакет CONNECT ACKNOWLEDGE.
Сеть также должна передать вызываемому абоненту пакет CONNECT ACKNOWLEDGE, и на этом соединение считается установленным. По виртуальному каналу могут передаваться данные.
Поддержка разных видов трафика
Компьютерные сети изначально предназначены для совместного доступа пользователя к ресурсам компьютеров: файлам, принтерам и т. п. Трафик, создаваемый этими традиционными службами компьютерных сетей, имеет свои особенности и существенно отличается от трафика сообщений в телефонных сетях или, например, в сетях кабельного телевидения. Однако 90-е годы стали годами проникновения в компьютерные сети трафика мультимедийных данных, представляющих в цифровой форме речь и видеоизображение. Компьютерные сети стали использоваться для организации видеоконференций, обучения и развлечения на основе видеофильмов и т. п. Естественно, что для динамической передачи мультимедийного трафика требуются иные алгоритмы и протоколы и, соответственно, другое оборудование. Хотя доля мультимедийного трафика пока невелика, он уже начал свое проникновение как в глобальные, так и локальные сети, и этот процесс, очевидно, будет продолжаться с возрастающей скоростью.
Главной особенностью трафика, образующегося при динамической передаче голоса или изображения, является наличие жестких требований к синхронности передаваемых сообщений. Для качественного воспроизведения непрерывных процессов, которыми являются звуковые колебания или изменения интенсивности света в видеоизображении, необходимо получение измеренных и закодированных амплитуд сигналов с той же частотой, с которой они были измерены на передающей стороне. При запаздывании сообщений будут наблюдаться искажения.
В то же время трафик компьютерных данных характеризуется крайне неравномерной интенсивностью поступления сообщений в сеть при отсутствии жестких требований к синхронности доставки этих сообщений. Например, доступ пользователя, работающего с текстом на удаленном диске, порождает случайный поток сообщений между удаленным и локальным компьютерами, зависящий от действий пользователя по редактированию текста, причем задержки при доставке в определенных (и достаточно широких с компьютерной точки зрения) пределах мало влияют на качество обслуживания пользователя сети.
Все алгоритмы компьютерной связи, соответствующие протоколы и коммуникационное оборудование были рассчитаны именно на такой «пульсирующий» характер трафика, поэтому необходимость передавать мультимедийный трафик требует внесения принципиальных изменений как в протоколы, так и оборудование. Сегодня практически все новые протоколы в той или иной степени предоставляют поддержку мультимедийного трафика.
Особую сложность представляет совмещение
в одной сети традиционного компьютерного и мультимедийного трафика. Передача исключительно мультимедийного трафика компьютерной сетью хотя и связана с определенными сложностями, но вызывает меньшие трудности. А вот случай сосуществования двух типов трафика с противоположными требованиями к качеству обслуживания является намного более сложной задачей. Обычно протоколы и оборудование компьютерных сетей относят мультимедийный трафик к факультативному, поэтому качество его обслуживания оставляет желать лучшего. Сегодня затрачиваются большие усилия по созданию сетей, которые не ущемляют интересы одного из типов трафика. Наиболее близки к этой цели сети на основе технологии АТМ, разработчики которой изначально учитывали случай сосуществования разных типов трафика в одной сети.
Поддержка резервных связей
Так как использование резервных связей в концентраторах определено только в стандарте FDDI, то для остальных стандартов разработчики концентраторов поддерживают такую функцию с помощью своих частных решений. Например, концентраторы Ethernet/Fast Ethernet могут образовывать только иерархические связи без петель. Поэтому резервные связи всегда должны соединять отключенные порты, чтобы не нарушать логику работы сети. Обычно при конфигурировании концентратора администратор должен определить, какие порты являются основными, а какие по отношению к ним - резервными (рис. 4.7). Если по какой-либо причине порт отключается (срабатывает механизм автосегментации), концентратор делает активным его резервный порт.
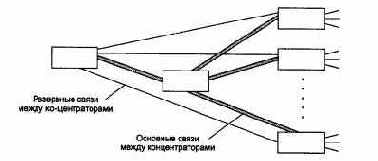
Рис. 4.7.
Резервные связи между концентраторами Ethernet
В некоторых моделях концентраторов разрешается использовать механизм назначения резервных портов только для оптоволоконных портов, считая, что нужно резервировать только наиболее важные связи, которые обычно выполняются на оптическом кабеле. В других же моделях резервным можно сделать любой порт.
Подключение пользовательского оборудования к сети ISDN
Подключение пользовательского оборудования к сети ISDN осуществляется в соответствии со схемой подключения, разработанной CCITT (рис. 6.17). Оборудование делится на функциональные группы, и в зависимости от группы различается несколько справочных точек (reference points) соединения разных групп оборудования между собой.

Рис. 6.17.
Подключение пользовательского оборудования ISDN
Устройства функциональной группы NT1 (Network Termination 1) образуют цифровое абонентское окончание (Digital Suscriber Line, DSL) на кабеле, соединяющем пользовательское оборудование с сетью ISDN. Фактически NT1 представляет собой устройство типа CSU, которое работает на физическом уровне и образует дуплексный канал с соответствующим устройством CSU, установленном на территории оператора сети ISDN. Справочная точка U соответствует точке подключения устройства NT1 к сети. Устройство NT1 может принадлежать оператору сети (хотя всегда устанавливается в помещении пользователя), а может принадлежать и пользователю. В Европе принято считать устройство NT1 частью оборудования сети, поэтому пользовательское оборудование (например, маршрутизатор с интерфейсом ISDN) выпускается без встроенного устройства NT1. В Северной Америке принято считать устройство NT1 принадлежностью пользовательского оборудования, поэтому для этого применения оборудование часто выпускается со встроенным устройством NT1.
Если пользователь подключен через интерфейс BRI, то цифровое абонентское окончание выполнено по 2-проводной схеме (как и обычное окончание аналоговой телефонной сети). Для организации дуплексного режима используется технология одновременной выдачи передатчиками потенциального кода 2B1Q с эхо - подавлением и вычитанием своего сигнала из суммарного. Максимальная длина абонентского окончания в этом случае составляет 5,5 км.
При использовании интерфейса PRI цифровое абонентское окончание выполняется по схеме канала Т1 или Е1, то есть является 4-проводным с максимальной длиной около 1800 м.
Устройства функциональной группы NT2 (Network Termination 2) представляют собой устройства канального или сетевого уровня, которые выполняют функции концентрации пользовательских интерфейсов и их мультиплексирование.
Например, к этому типу оборудования относятся: офисная АТС (РВХ), коммутирующая несколько интерфейсов BRI, маршрутизатор, работающий в режиме коммутации пакетов (например, по каналу D), простой мультиплексор TDM, который мультиплексирует несколько низкоскоростных каналов в один канал типа В. Точка подключения оборудования типа NT2 к устройству NT1 называется справочной точкой типа Т. Наличие этого типа оборудования не является обязательным в отличие от NT1.
Устройства функциональной группы ТЕ1 (Terminal Equipment 1) относятся к устройствам, которые поддерживают интерфейс пользователя BRI или PRI. Справочная точка S соответствует точке подключения отдельного терминального оборудования, поддерживающего один из интерфейсов пользователя ISDN. Таким оборудованием может быть цифровой телефон или факс-аппарат. Так как оборудование типа NT2 может отсутствовать, то справочные точки S и Т объединяются и обозначаются как S/T.
Устройства функциональной группы ТЕ2 (Terminal Equipment 2) представляют собой устройства, которые не поддерживают интерфейс BRI или PRI. Таким устройством может быть компьютер, маршрутизатор с последовательными интерфейсами, не относящимися к ISDN, например RS-232C, Х.21 или V.35. Для подключения такого устройства к сети ISDN необходимо использовать терминальный адаптер (Terminal Adaptor, ТА). Для компьютеров терминальные адаптеры выпускаются в формате сетевых адаптеров - как встраиваемая карта.
Физически интерфейс в точке S/T представляет собой 4-проводную линию. Так как кабель между устройствами ТЕ1 или ТА и сетевым окончанием NT1 или NT2 обычно имеет небольшую длину, то разработчики стандартов ISDN решили не усложнять оборудование, так как организация дуплексного режима на 4-про-водной линии намного легче, чем на 2-проводной. Для интерфейса BRI в качестве метода кодирования выбран биполярный AMI, причем логическая единица кодируется нулевым потенциалом, а логический ноль - чередованием потенциалов противоположной полярности. Для интерфейса PRI используются другие коды, те же, что и для интерфейсов Т1 и Е1, то есть соответственно B8ZS и HDB3.
Физическая длина интерфейса PRI колеблется от 100 до 1000 м в зависимости от схемы подключения устройств (рис. 6.18).

Рис. 6.18.
Многоточечное подключение терминалов к сетевому окончанию
Дело в том, что при небольшом количестве терминалов (ТЕ1 или ТЕ2+ТА) разрешается не использовать местную офисную АТС, а подключать до 8 устройств к одному устройству типа NT1 (или NT2 без коммутационных возможностей) с помощью схемы монтажного ИЛИ (подключение напоминает подключение станций к коаксиальному кабелю Ethernet, но только в 4-проводном варианте). При подключении одного устройства ТЕ (через терминальные резисторы R, согласующие параметры линии) к сетевому окончанию NT (см. рис. 6.18, а) длина кабеля может достигать 1000 м. При подключении нескольких устройств к пассивному кабелю (см. рис. 6.18, б) максимальная длина кабеля сокращается до 100-200 м. Правда, если эти устройства сосредоточены на дальнем конце кабеля (расстояние между ними не превышает 25-50 м), то длина кабеля может быть увеличена до 500 м (см. рис. 6.18, в). И наконец, существуют специальные многопортовые устройства NT1, которые обеспечивают звездообразное подключение до 8 устройств, при этом длина кабеля увеличивается до 1000 м (см. рис. 6.18, г).
Появление глобальных сетей
Тем не менее потребность в соединении компьютеров, находящихся на большом расстоянии друг от друга, к этому времени вполне назрела. Началось все с решения более простой задачи - доступа к компьютеру с терминалов, удаленных от него на многие сотни, а то и тысячи километров. Терминалы соединялись с компьютерами через телефонные сети с помощью модемов. Такие сети позволяли многочисленным пользователям получать удаленный доступ к разделяемым ресурсам нескольких мощных компьютеров класса суперЭВМ. Затем появились системы, в которых наряду с удаленными соединениями типа терминал-компьютер были реализованы и удаленные связи типа компьютер-компьютер. Компьютеры получили возможность обмениваться данными в автоматическом режиме, что, собственно, и является базовым механизмом любой вычислительной сети. Используя этот механизм, в первых сетях были реализованы службы обмена файлами, синхронизации баз данных, электронной почты и другие, ставшие теперь традиционными сетевые службы.
Таким образом, хронологически первыми появились глобальные вычислительные сети. Именно при построении глобальных сетей были впервые предложены и отработаны многие основные идеи и концепции современных вычислительных сетей. Такие, например, как многоуровневое построение коммуникационных протоколов, технология коммутации пакетов, маршрутизация пакетов в составных сетях.
Пользовательские интерфейсы ISDN
Одним из базовых принципов ISDN является предоставление пользователю стандартного интерфейса, с помощью которого пользователь может запрашивать у сети разнообразные услуги. Этот интерфейс образуется между двумя типами оборудования, устанавливаемого в помещении пользователя (Customer Premises Equipment, СРЕ): терминальным оборудованием пользователя ТЕ (компьютер с соответствующим адаптером, маршрутизатор, телефонный аппарат) и сетевым окончанием NT, которое представляет собой устройство, завершающее канал связи с ближайшим коммутатором ISDN.
Пользовательский интерфейс основан на каналах трех типов:
В-со скоростью передачи данных 64 Кбит/с;
D - со скоростью передачи данных 16 или 64 Кбит/с;
Н - со скоростью передачи данных 384 Кбит/с (НО), 1536 Кбит/с (НИ) или 1920 Кбит/с (Н12).
Каналы типа В обеспечивают передачу пользовательских данных (оцифрованного голоса, компьютерных данных или смеси голоса и данных) и с более низкими скоростями, чем 64 Кбит/с. Разделение данных выполняется с помощью техники TDM. Разделением канала В на подканалы в этом случае должно заниматься пользовательское оборудование, сеть ISDN всегда коммутирует целые каналы типа В. Каналы типа В могут соединять пользователей с помощью техники коммутации каналов друг с другом, а также образовывать так называемые полупостоянные (semipermanent) соединения, которые эквиваленты соединениям службы выделенных каналов. Канал типа В может также подключать пользователя к коммутатору сети Х.25.
Канал типа D выполняет две основные функции. Первой и основной является передача адресной информации, на основе которой осуществляется коммутация каналов типа В в коммутаторах сети. Второй функцией является поддержание услуг низкоскоростной сети с коммутацией пакетов для пользовательских данных. Обычно эта услуга выполняется сетью в то время, когда каналы типа D свободны от выполнения основной функции.
Каналы типа Н предоставляют пользователям возможности высокоскоростной передачи данных. На них могут работать службы высокоскоростной передачи факсов, видеоинформации, качественного воспроизведения звука.
Пользовательский интерфейс ISDN представляет собой набор каналов определенного типа и с определенными скоростями.
Сеть ISDN поддерживает два типа пользовательского интерфейса - начальный (Basic Rate Interface, BRI) и основной (Primay Rate Interface, PRI).
Начальный интерфейс BRI
предоставляет пользователю два канала по 64 Кбит/с для передачи данных (каналы типа В) и один канал с пропускной способностью 16 Кбит/с для передачи управляющей информации (канал типа D). Все каналы работают в полнодуплексном режиме. В результете суммарная скорость интерфейса BRI для пользовательских данных составляет 144 Кбит/с по каждому направлению, а с учетом служебной информации - 192 Кбит/с. Различные каналы пользовательского интерфейса разделяют один и тот же физический двухпроводный кабель по технологии TDM, то есть являются логическими каналами, а не физическими. Данные по интерфейсу BRI передаются кадрами, состоящими из 48 бит. Каждый кадр содержит по 2 байта каждого из В каналов, а также 4 бита канала D. Передача кадра длится 250 мс, что обеспечивает скорость данных 64 Кбит/с для каналов В и 16 Кбит/с для канала D. Кроме бит данных кадр содержит служебные биты для обеспечения синхронизации кадров, а также обеспечения нулевой постоянной составляющей электрического сигнала.
Интефейс BRI может поддерживать не только схему 2B+D, но и B+D и просто D (когда пользователь направляет в сеть только пакетизированные данные).
Начальный интерфейс стандартизован в рекомендации 1.430.
Основной интерфейс PRI предназначен для
пользователей с повышенными требованиями к пропускной способности сети. Интерфейс PRI поддерживает либо схему 30B+D, либо схему 23B+D. В обеих схемах канал D обеспечивает скорость 64 Кбит/с. Первый вариант предназначен для Европы, второй - для Северной Америки и Японии. Ввиду большой популярности скорости цифровых каналов 2,048 Мбит/с в Европе и скорости 1,544 Мбит/с в остальных регионах, привести стандарт на интерфейс PRI к общему варианту не удалось.
Возможны варианты интерфейса PRI с меньшим количеством каналов типа В, например 20B+D.Каналы типа В могут объединяться в один логический высокоскоростной канал с общей скоростью до 1920 Кбит/с. При установке у пользователя нескольких интерфейсов PRI все они могут иметь один канал типа D, при этом количество В каналов в том интерфейсе, который не имеет канала D, может увеличиваться до 24 или 31.
Основной интерфейс может быть основан на каналах типа Н. При этом общая пропускная способность интерфейса все равно не должна превышать 2,048 или 1,544 Мбит/с. Для каналов НО возможны интерфейсы 3HO+D для американского варианта и 5HO+D для европейского. Для каналов HI возможен интерфейс, состоящий только из одного канала НИ (1,536 Мбит/с) для американского варианта или одного канала HI 2 (1,920 Мбит/с) и одного канала D для европейского варианта.
Кадры интерфейса PRI имеют структуру кадров DS-1 для каналов Т1 или Е1. Основной интерфейс PRI стандартизован в рекомендации 1.431.
Помехоустойчивость и достоверность
Помехоустойчивость линии определяет ее способность уменьшать уровень помех, создаваемых во внешней среде, на внутренних проводниках. Помехоустойчивость линии зависит от типа используемой физической среды, а также от экранирующих и подавляющих помехи средств самой линии. Наименее помехоустойчивыми являются радиолинии, хорошей устойчивостью обладают кабельные линии и отличной - волоконно-оптические линии, малочувствительные ко внешнему электромагнитному излучению. Обычно для уменьшения помех, появляющихся из-за внешних электромагнитных полей, проводники экранируют и/или скручивают.
Перекрестные наводки на ближнем конце (Near End Cross Talk - NEXT) определяют помехоустойчивость кабеля к внутренним источникам помех, когда электромагнитное поле сигнала, передаваемого выходом передатчика по одной паре проводников, наводит на другую пару проводников сигнал помехи. Если ко второй паре будет подключен приемник, то он может принять наведенную внутреннюю помеху за полезный сигнал. Показатель NEXT, выраженный в децибелах, равен 10 log Рвых/Рнав, где Рвых - мощность выходного сигнала, Рнав - мощность наведенного сигнала.
Чем меньше значение NEXT, тем лучше кабель. Так, для витой пары категории 5 показатель NEXT должен быть меньше -27 дБ на частоте 100 МГц.
Показатель NEXT обычно используется применительно к кабелю, состоящему из нескольких витых пар, так как в этом случае взаимные наводки одной пары на другую могут достигать значительных величин. Для одинарного коаксиального кабеля (то есть состоящего из одной экранированной жилы) этот показатель не имеет смысла, а для двойного коаксиального кабеля он также не применяется вследствие высокой степени защищенности каждой жилы. Оптические волокна также не создают сколь-нибудь заметных помех друг для друга.
В связи с тем, что в некоторых новых технологиях используется передача данных одновременно по нескольким витым парам, в последнее время стал применяться показатель PowerSUM, являющийся модификацией показателя NEXT. Этот показатель отражает суммарную мощность перекрестных наводок от всех передающих пар в кабеле.
Достоверность передачи данных характеризует вероятность искажения для каждого передаваемого бита данных. Иногда этот же показатель называют интенсивностью битовых ошибок (Bit Error Rate, BER). Величина BER для каналов связи без дополнительных средств защиты от ошибок (например, самокорректирующихся кодов или протоколов с повторной передачей искаженных кадров) составляет, как правило,10-4 - 10-6, в оптоволоконных линиях связи - 10-9. Значение достоверности передачи данных, например, в 10-4 говорит о том, что в среднем из 10000 бит искажается значение одного бита.
Искажения бит происходят как из-за наличия помех на линии, так и по причине искажений формы сигнала ограниченной полосой пропускания линии. Поэтому для повышения достоверности передаваемых данных нужно повышать степень помехозащищенности линии, снижать уровень перекрестных наводок в кабеле, а также использовать более широкополосные линии связи.
Понятие internetworking
Основная идея введения сетевого уровня состоит в следующем. Сеть в общем случае рассматривается как совокупность нескольких сетей и называется составной сетью или интерсетью (internetwork или internet).
Сети, входящие в составную сеть, называются подсетями (subnet),
составляющими сетями или просто сетями (рис. 5.1).
Рис. 5.1.
Архитектура составной сети
Подсети соединяются между собой маршрутизаторами. Компонентами составной сети могут являться как локальные, так и глобальные сети. Внутренняя структура каждой сети на рисунке не показана, так как она не имеет значения при рассмотрении сетевого протокола. Все узлы в пределах одной подсети взаимодействуют, используя единую для них технологию. Так, в составную сеть, показанную на рисунке, входит несколько сетей разных технологий: локальные сети Ethernet, Fast Ethernet, Token Ring, FDDI и глобальные сети frame relay, X.25, ISDN. Каждая из этих технологий достаточна для того, чтобы организовать взаимодействие всех узлов в своей подсети, но не способна построить информационную связь между произвольно выбранными узлами, принадлежащими разным подсетям, например между узлом А и узлом В на рис. 5.1. Следовательно, для организации взаимодействия между любой произвольной парой узлов этой «большой» составной сети требуются дополнительные средства. Такие средства и предоставляет сетевой уровень.
Сетевой уровень выступает в качестве координатора, организующего работу всех подсетей, лежащих на пути продвижения пакета по составной сети. Для перемещения данных в пределах подсетей сетевой уровень обращается к используемым в этих подсетях технологиям.
Хотя многие технологии локальных сетей (Ethernet, Token Ring, FDDI, Fast Ethernet и др.) используют одну и ту же систему адресации узлов на основе МАС - адресов, существует немало технологий (X.25, АТМ, frame relay), в которых применяются другие схемы адресации. Адреса, присвоенные узлам в соответствии с технологиями подсетей, называют локальными. Чтобы сетевой уровень мог выполнить свою задачу, ему необходима собственная система адресации, не зависящая от способов адресации узлов в отдельных подсетях, которая позволила бы на сетевом уровне универсальным и однозначным способами идентифицировать любой узел составной сети.
Естественным способом формирования сетевого адреса является уникальная нумерация всех подсетей составной сети и нумерация всех узлов в пределах каждой подсети. Таким образом, сетевой адрес представляет собой пару: номер сети (подсети) и номер узла.
В качестве номера узла может выступать либо локальный адрес этого узла (такая схема принята в стеке IPX/SPX), либо некоторое число, никак не связанное с локальной технологией, которое однозначно идентифицирует узел в пределах данной подсети. В первом случае сетевой адрес становится зависимым от локальных технологий, что ограничивает его применение. Например, сетевые адреса IPX/SPX рассчитаны на работу в составных сетях, объединяющих сети, в которых используются только МАС - адреса или адреса аналогичного формата. Второй подход более универсален, он характерен для стека TCP/IP. И в том и другом случае каждый узел составной сети имеет наряду со своим локальным адресом еще один - универсальный сетевой адрес.
Данные, которые поступают на сетевой уровень и которые необходимо передать через составную сеть, снабжаются заголовком сетевого уровня. Данные вместе с заголовком образуют пакет. Заголовок пакета сетевого уровня имеет унифицированный формат, не зависящий от форматов кадров канального уровня тех сетей, которые могут входить в объединенную сеть, и несет наряду с другой служебной информацией данные о номере сети, которой предназначается этот пакет. Сетевой уровень определяет маршрут и перемещает пакет между подсетями.
При передаче пакета из одной подсети в другую пакет сетевого уровня, инкапсулированный в прибывший канальный кадр первой подсети, освобождается от заголовков этого кадра и окружается заголовками кадра канального уровня следующей подсети. Информацией, на основе которой делается эта замена, являются служебные поля пакета сетевого уровня. В поле адреса назначения нового кадра указывается локальный адрес следующего маршрутизатора.
ПРИМЕЧАНИЕ Если в подсети доставка данных осуществляется средствами канального и физического уровней (как, например, в стандартных локальных сетях), то пакеты сетевого уровня упаковываются в кадры канального уровня.
Если же в какой- либо подсети для транспортировки сообщений используется технология, основанная на стеках с большим числом уровней, то пакеты сетевого уровня упаковываются в блоки передаваемых данных самого высокого уровня подсети.
Если проводить аналогию между взаимодействием разнородных сетей и перепиской людей из разных стран, то сетевая информация - это общепринятый индекс страны, добавленный к адресу письма, написанному на одном из сотни языков земного шара, например на санскрите. И даже если это письмо должно пройти через множество стран, почтовые работники которых не знают санскрита, понятный им индекс страны-адресата подскажет, через какие промежуточные страны лучше передать письмо, чтобы оно кратчайшим путем попало в Индию. А уже там работники местных почтовых отделений смогут прочитать точный адрес, указывающий город, улицу, дом и индивидуума, и доставить письмо адресату, так как адрес написан на языке и в форме, принятой в данной стране.
Основным полем заголовка сетевого уровня является номер сети-адресата. В рассмотренных нами ранее протоколах локальных сетей такого поля в кадрах предусмотрено не было - предполагалось, что все узлы принадлежат одной сети. Явная нумерация сетей позволяет протоколам сетевого уровня составлять точную карту межсетевых связей и выбирать рациональные маршруты при любой их топологии, в том числе альтернативные маршруты, если они имеются, что не умеют делать мосты и коммутаторы.
Кроме номера сети заголовок сетевого уровня должен содержать и другую информацию, необходимую для успешного перехода пакета из сети одного типа в сеть другого типа. К такой информации может относиться, например:
номер фрагмента пакета, необходимый для успешного проведения операций сборки-разборки фрагментов при соединении сетей с разными максимальными размерами пакетов;
время жизни пакета, указывающее, как долго он путешествует по интерсети, это время может использоваться для уничтожения «заблудившихся» пакетов;
качество услуги - критерий выбора маршрута при межсетевых передачах - например, узел-отправитель может потребовать передать пакет с максимальной надежностью, возможно, в ущерб времени доставки.
Когда две или более сети организуют совместную транспортную службу, то такой режим взаимодействия обычно называют межсетевым взаимодействием (internetworking).
Понятие «открытая система»
Модель OSI, как это следует из ее названия (Open System Interconnection), описывает взаимосвязи открытых систем. Что же такое открытая система?
В широком смысле открытой системой может быть названа любая система (компьютер, вычислительная сеть, ОС, программный пакет, другие аппаратные и программные продукты), которая построена в соответствии с открытыми спецификациями.
Напомним, что под термином «спецификация» (в вычислительной технике) понимают формализованное описание аппаратных или программных компонентов, способов их функционирования, взаимодействия с другими компонентами, условий эксплуатации, ограничений и особых характеристик. Понятно, что не всякая спецификация является стандартом. В свою очередь, под открытыми спецификациями понимаются опубликованные, общедоступные спецификации, соответствующие стандартам и принятые в результате достижения согласия после всестороннего обсуждения всеми заинтересованными сторонами.
Использование при разработке систем открытых спецификаций позволяет третьим сторонам разрабатывать для этих систем различные аппаратные или программные средства расширения и модификации, а также создавать программно-аппаратные комплексы из продуктов разных производителей.
Для реальных систем полная открытость является недостижимым идеалом. Как правило, даже в системах, называемых открытыми, этому определению соответствуют лишь некоторые части, поддерживающие внешние интерфейсы. Например, открытость семейства операционных систем Unix заключается, кроме всего прочего, в наличии стандартизованного программного интерфейса между ядром и приложениями, что позволяет легко переносить приложения из среды одной версии Unix в среду другой версии. Еще одним примером частичной открытости является применение в достаточно закрытой операционной системе Novell NetWare открытого интерфейса Open Driver Interface (ODI) для включения в систему драйверов сетевых адаптеров независимых производителей. Чем больше открытых спецификаций использовано при разработке системы, тем более открытой она является.
Модель OSI касается только одного аспекта открытости, а именно открытости средств взаимодействия устройств, связанных в вычислительную сеть. Здесь под открытой системой понимается сетевое устройство, готовое взаимодействовать с другими сетевыми устройствами с использованием стандартных правил, определяющих формат, содержание и значение принимаемых и отправляемых сообщений.
Если две сети построены с соблюдением принципов открытости, то это дает следующие преимущества:
возможность построения сети из аппаратных и программных средств различных производителей, придерживающихся одного и того же стандарта;
возможность безболезненной замены отдельных компонентов сети другими, более совершенными, что позволяет сети развиваться с минимальными затратами;
возможность легкого сопряжения одной сети с другой;
простота освоения и обслуживания сети.
Ярким примером открытой системы является международная сеть Internet. Эта сеть развивалась в полном соответствии с требованиями, предъявляемыми к открытым системам. В разработке ее стандартов принимали участие тысячи специалистов-пользователей этой сети из различных университетов, научных организаций и фирм-производителей вычислительной аппаратуры и программного обеспечения, работающих в разных странах. Само название стандартов, определяющих работу сети Internet - Request For Comments (RFC), что можно перевести как «запрос на комментарии», - показывает гласный и открытый характер принимаемых стандартов. В результате сеть Internet сумела объединить в себе самое разнообразное оборудование и программное обеспечение огромного числа сетей, разбросанных по всему миру.
Понятие «открытая система» и проблемы стандартизации
Универсальный тезис о пользе стандартизации, справедливый для всех отраслей, в компьютерных сетях приобретает особое значение. Суть сети - это соединение разного оборудования, а значит, проблема совместимости является одной из наиболее острых. Без принятия всеми производителями общепринятых правил построения оборудования прогресс в деле «строительства» сетей был бы невозможен. Поэтому все развитие компьютерной отрасли в конечном счете отражено в стандартах - любая новая технология только тогда приобретает «законный» статус, когда ее содержание закрепляется в соответствующем стандарте.
В компьютерных сетях идеологической основой стандартизации является многоуровневый подход к разработке средств сетевого взаимодействия. Именно на основе этого подхода была разработана стандартная семиуровневая модель взаимодействия открытых систем, ставшая своего рода универсальным языком сетевых специалистов.
Порядок распределения IP-адресов
Номера сетей назначаются либо централизованно, если сеть является частью Internet, либо произвольно, если сеть работает автономно. Номера узлов и в том и в другом случае администратор волен назначать по своему усмотрению, не выходя, разумеется, из разрешенного для этого класса сети диапазона.
Координирующую роль в централизованном распределении IP-адресов до некоторого времени играла организация InterNIC, однако с ростом сети задача распределения адресов стала слишком сложной, и InterNIC делегировала часть своих функций другим организациям и крупным поставщикам услуг Internet.
Уже сравнительно давно наблюдается дефицит IP-адресов. Очень трудно получить адрес класса В и практически невозможно стать обладателем адреса класса А. При этом надо отметить, что дефицит обусловлен не только ростом сетей, но и тем, что имеющееся множество IP-адресов используется нерационально. Очень часто владельцы сети класса С расходуют лишь небольшую часть из имеющихся у них 254 адресов. Рассмотрим пример, когда две сети необходимо соединить глобальной связью. В таких случаях в качестве канала связи используют два маршрутизатора, соединенных по схеме «точка-точка» (рис. 5.10). Для вырожденной сети, образованной каналом, связывающим порты двух смежных маршрутизаторов, приходится выделять отдельный номер сети, хотя в этой сети имеются всего 2 узла.

Рис. 5.10. Нерациональное использование пространства IP-адресов
Если же некоторая IP-сеть создана для работы в «автономном режиме», без связи с Internet, тогда администратор этой сети волен назначить ей произвольно выбранный номер. Но и в этой ситуации для того, чтобы избежать каких-либо коллизий, в стандартах Internet определено несколько диапазонов адресов, рекомендуемых для локального использования. Эти адреса не обрабатываются маршрутизаторами Internet ни при каких условиях. Адреса, зарезервированные для локальных целей, выбраны из разных классов; в классе А - это сеть 10.0.0.0, в классе В - это диапазон из 16 номеров сетей 172.16.0.0-172.31.0.0, в классе С - это диапазон из 255 сетей - 192.168.0.0-192.168.255.0.
Для смягчения проблемы дефицита адресов разработчики стека TCP/IP предлагают разные подходы. Принципиальным решением является переход на новую версию IPv6, в которой резко расширяется адресное пространство за счет использования 16-байтных адресов. Однако и текущая версия IPv4 поддерживает некоторые технологии, направленные на более экономное расходование IP-адресов. Одной из таких технологий является технология масок и ее развитие - технология бесклассовой междоменной маршрутизации (Classless Inker-Domain Routing, CIDR). Технология CIDR отказывается от традиционной концепции разделения адресов протокола IP на классы, что позволяет получать в пользование столько адресов, сколько реально необходимо. Благодаря CIDR поставщик услуг получает возможность «нарезать» блоки из выделенного ему адресного пространства в точном соответствии с требованиями каждого клиента, при этом у него остается пространство для маневра на случай его будущего роста.
Другая технология, которая может быть использована для снятия дефицита адресов, это трансляция адресов (Network Address Translator, NAT). Узлам внутренней сети адреса назначаются произвольно (естественно, в соответствии с общими правилами, определенными в стандарте), так, как будто эта сеть работает автономно. Внутренняя сеть соединяется с Internet через некоторое промежуточное устройство (маршрутизатор, межсетевой экран). Это промежуточное устройство получает в свое распоряжение некоторое количество внешних «нормальных» IP-адресов, согласованных с поставщиком услуг или другой организацией, распределяющей IP-адреса. Промежуточное устройство способно преобразовывать внутренние адреса во внешние, используя для этого некие таблицы соответствия. Для внешних пользователей все многочисленные узлы внутренней сети выступают под несколькими внешними IP-адресами. При получении внешнего запроса это устройство анализирует его содержимое и при необходимости пересылает его во внутреннюю сеть, заменяя IP-адрес на внутренний адрес этого узла.Процедура трансляции адресов определена в RFC 1631.
Порты
Протокол TCP взаимодействует через межуровневые интерфейсы с ниже лежащим протоколом IP и с выше лежащими протоколами прикладного уровня или приложениями.
В то время как задачей сетевого уровня, к которому относится протокол IP, является передача данных между произвольными узлами сети, задача транспортного уровня, которую решает протокол TCP, заключается в передаче данных между любыми прикладными процессами, выполняющимися на любых узлах сети. Действительно, после того как пакет средствами протокола IP доставлен в компьютер-получатель, данные необходимо направить конкретному процессу-получателю. Каждый компьютер может выполнять несколько процессов, более того, прикладной процесс тоже может иметь несколько точек входа, выступающих в качестве адреса назначения для пакетов данных.
Пакеты, поступающие на транспортный уровень, организуются операционной системой в виде множества очередей к точкам входа различных прикладных процессов. В терминологии TCP/IP такие системные очереди называются портами. Таким образом, адресом назначения, который используется протоколом TCP, является идентификатор (номер) порта прикладной службы. Номер порта в совокупности с номером сети и номером конечного узла однозначно определяют прикладной процесс в сети. Этот набор идентифицирующих параметров имеет название сокет (socket).
Назначение номеров портов прикладным процессам осуществляется либо централизованно, если эти процессы представляют собой популярные общедоступные службы (например, номер 21 закреплен за службой удаленного доступа к файлам FTP, a 23 - за службой удаленного управления telnet), либо локально для тех служб, которые еще не стали столь распространенными, чтобы закреплять за ними стандартные (зарезервированные) номера. Централизованное присвоение службам номеров портов выполняется организацией Internet Assigned Numbers Authority (IANA). Эти номера затем закрепляются и опубликовываются в стандартах Internet (RFC 1700).
Локальное присвоение номера порта заключается в том, что разработчик некоторого приложения просто связывает с ним любой доступный, произвольно выбранный числовой идентификатор, обращая внимание на то, чтобы он не входил в число зарезервированных номеров портов. В дальнейшем все удаленные запросы к данному приложению от других приложений должны адресоваться с указанием назначенного ему номера порта.
Протокол TCP ведет для каждого порта две очереди: очередь пакетов, поступающих в данный порт из сети, и очередь пакетов, отправляемых данным портом в сеть. Процедура обслуживания протоколом TCP запросов, поступающих от нескольких различных прикладных служб, называется мультиплексированием. Обратная процедура распределения протоколом TCP поступающих от сетевого уровня пакетов между набором высокоуровневых служб, идентифицированных номерами портов, называется демультиплексированием
(рис. 5.23).

Рис. 5.23. Функции протокола TCP no мультиплексированию и демультиплексированию потоков
Построение локальных сетей по стандартам физического и канального уровней
В данной главе рассматриваются вопросы, связанные с реализацией рассмотренных выше протоколов физического и канального уровней в сетевом коммуникационном оборудовании. Хотя на основе оборудования только этого уровня трудно построить достаточно крупную корпоративную сеть, именно кабельные системы, сетевые адаптеры, концентраторы, мосты и коммутаторы представляют наиболее массовый тип сетевых устройств.
За исключением кабельной системы, которая является протокольно независимой, устройство и функции коммуникационного оборудования остальных типов существенно зависят от того, какой конкретно протокол в них реализован. Концентратор Ethernet устроен не так, как концентратор Token Ring, а сетевой адаптер FDDI не сможет работать в сети Fast Ethernet. С другой стороны, даже в рамках одной технологии оборудование разных производителей может заметно отличаться друг от друга. В этой главе будут рассмотрены наиболее типичные варианты реализации основных и дополнительных устройств физического и канального уровней.
Построение таблицы маршрутизации
Протокол RIP (Routing Information Protocol) является внутренним протоколом маршрутизации дистанционно-векторного типа, он представляет собой один из наиболее ранних протоколов обмена маршрутной информацией и до сих пор чрезвычайно распространен в вычислительных сетях ввиду простоты реализации. Кроме версии RIP для сетей TCP/IP существует также версия RIP для сетей IPX/SPX компании Novell.
Для IP имеются две версии протокола RIP: первая и вторая. Протокол RIPvl не поддерживает масок, то есть он распространяет между маршрутизаторами только информацию о номерах сетей и расстояниях до них, а информацию о масках этих сетей не распространяет, считая, что все адреса принадлежат к стандартными классам А, В или С. Протокол RIPv2 передает информацию о масках сетей, поэтому он в большей степени соответствует требованиям сегодняшнего дня. Так как при построении таблиц маршрутизации работа версии 2 принципиально не отличается от версии 1, то в дальнейшем для упрощения записей будет описываться работа первой версии.
В качестве расстояния до сети стандарты протокола RIP допускают различные виды метрик: хопы, метрики, учитывающие пропускную способность, вносимые задержки и надежность сетей (то есть соответствующие признакам D, Т и R в поле «Качество сервиса» IP-пакета), а также любые комбинации этих метрик. Метрика должна обладать свойством аддитивности - метрика составного пути должна быть равна сумме метрик составляющих этого пути. В большинстве реализации RIP используется простейшая метрика - количество хопов, то есть количество промежуточных маршрутизаторов, которые нужно преодолеть пакету до сети назначения.
Рассмотрим процесс построения таблицы маршрутизации с помощью протокола RIP на примере составной сети, изображенной на рис. 5.26.

Рис. 5.26. Сеть, объединенная RIP-маршрутизаторами
Потенциальный код
На рис. 2.16, д показан потенциальный код с четырьмя уровнями сигнала для кодирования данных. Это код 2B1Q, название которого отражает его суть - каждые два бита (2В) передаются за один такт сигналом, имеющим четыре состояния (1Q), Паре бит 00 соответствует потенциал -2,5 В, паре бит 01 соответствует потенциал -0,833 В, паре 11 - потенциал +0,833 В, а паре 10 - потенциал +2,5 В. При этом способе кодирования требуются дополнительные меры по борьбе с длинными последовательностями одинаковых пар бит, так как при этом сигнал превращается в постоянную составляющую. При случайном чередовании бит спектр сигнала в два раза уже, чем у кода NRZ, так как при той же битовой скорости длительность такта увеличивается в два раза. Таким образом, с помощью кода 2B1Q можно по одной и той же линии передавать данные в два раза быстрее, чем с помощью кода AMI или NRZI. Однако для его реализации мощность передатчика должна быть выше, чтобы четыре уровня четко различались приемником на фоне помех.
Потенциальный код без возвращения к нулю
На рис. 2.16, а показан уже упомянутый ранее метод потенциального кодирования, называемый также кодированием без возвращения к нулю (Non Return to Zero, NRZ). Последнее название отражает то обстоятельство, что при передаче последовательности единиц сигнал не возвращается к нулю в течение такта (как мы увидим ниже, в других методах кодирования возврат к нулю в этом случае происходит). Метод NRZ прост в реализации, обладает хорошей распознаваемостью ошибок (из-за двух резко отличающихся потенциалов), но не обладает свойством самосинхронизации. При передаче длинной последовательности единиц или нулей сигнал на линии не изменяется, поэтому приемник лишен возможности определять по входному сигналу моменты времени, когда нужно в очередной раз считывать данные. Даже при наличии высокоточного тактового генератора приемник может ошибиться с моментом съема данных, так как частоты двух генераторов никогда не бывают полностью идентичными. Поэтому при высоких скоростях обмена данными и длинных последовательностях единиц или нулей небольшое рассогласование тактовых частот может привести к ошибке в целый такт и, соответственно, считыванию некорректного значения бита.

Рис. 2.16. Способы дискретного кодирования данных
Другим серьезным недостатком метода NRZ является наличие низкочастотной составляющей, которая приближается к нулю при передаче длинных последовательностей единиц или нулей. Из-за этого многие каналы связи, не обеспечивающие прямого гальванического соединения между приемником и источником, этот вид кодирования не поддерживают. В результате в чистом виде код NRZ в сетях не используется. Тем не менее используются его различные модификации, в которых устраняют как плохую самосинхронизацию кода NRZ, так и наличие постоянной составляющей. Привлекательность кода NRZ, из-за которой имеет смысл заняться его улучшением, состоит в достаточно низкой частоте основной гармоники f0, которая равна N/2 Гц, как это было показано в предыдущем разделе. У других методов кодирования, например манчестерского, основная гармоника имеет более высокую частоту.
Потенциальный код с инверсией при единице
Существует код, похожий на AMI, но только с двумя уровнями сигнала. При передаче нуля он передает потенциал, который был установлен в предыдущем такте (то есть не меняет его), а при передаче единицы потенциал инвертируется на противоположный. Этот код называется потенциальным кодом с инверсией при единице (Non Return to Zero with ones Inverted, NRZI). Этот код удобен в тех случаях, когда использование третьего уровня сигнала весьма нежелательно, например в оптических кабелях, где устойчиво распознаются два состояния сигнала - свет и темнота.
Для улучшения потенциальных кодов, подобных AMI и NRZI, используются два метода. Первый метод основан на добавлении в исходный код избыточных бит, содержащих логические единицы. Очевидно, что в этом случае длинные последовательности нулей прерываются и код становится самосинхронизирующимся для любых передаваемых данных. Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии, так как избыточные единицы пользовательской информации не несут. Другой метод основан на предварительном «перемешивании» исходной информации таким образом, чтобы вероятность появления единиц и нулей на линии становилась близкой. Устройства, или блоки, выполняющие такую операцию, называются трамблерами (scramble - свалка, беспорядочная сборка). При скремб-лировании используется известный алгоритм, поэтому приемник, получив двоичные данные, передает их на дескрэмблер, который восстанавливает исходную последовательность бит. Избыточные биты при этом по линии не передаются. Оба метода относятся к логическому, а не физическому кодированию, так как форму сигналов на линии они не определяют. Более детально они изучаются в следующем разделе.
Правила определения управляемых объектов
Классы управляемых объектов OSI должны определяться в соответствии со стандартом GDMO (Guidelines for the Definition of Managed Objects - Правила определения управляемых объектов), являющимся стандартом ISO 10165-4.
В GDMO определяется несколько шаблонов (templates) - пустых форм, которые заполняются для описания определенного класса управляемых объектов. В шаблоне класса перечисляются комплекты свойств (PACKAGES
), которые составляют класс. Шаблон комплекта свойств PACKAGE
перечисляет Атрибуты, Группы атрибутов, Действия, Поведение
и Уведомления
, то есть свойства, сгруппированные для удобства описания класса объектов. Отношения наследования между классами описываются с помощью шаблона Связывание имен
.
Атрибуты и Группы атрибутов
определяют параметры объекта, которые можно читать и узнавать из них о состоянии объекта. СвойстваДействия
описывают возможные управляющие воздействия, которые допускается применять к данному объекту - например, мультиплексировать несколько входных потоков в один выходной. Свойство Поведение
описывает реакцию объекта на примененное к нему действие. Уведомления
составляют набор сообщений, которые генерирует объект по своей инициативе.
Заполненные шаблоны GDMO определяют представление класса и его свойств.
Заполнение шаблонов выполняется в соответствии с нотацией ASN.1. В отличие от стандартов SNMP, использующих только подмножество типов данных ASN.1, в GDMO и CMIP применяется полная версия ASN.1.
На основании правил GDMO определено несколько международных стандартов на классы управляемых объектов. Документы Definition of Management Information (DMI, ISO/IEC 10165-2:1991) и Generic Management Information (GMI, ISO/IEC CD 10165-5:1992) являются первыми определениями М1В на основе окончательной версии GDMO. Эти MIB могут рассматриваться как ISO-эквивалент для Internet MIB II, так как они создают основу для построения более специфических MIB. Например, DMI определяет класс объектов, называемый Тор, который является верхним суперклассом, - он содержит атрибуты, которые наследуются всеми другими классами управляемых объектов.
Определены также классы объектов System и Network, занимающие верхние позиции в дереве наследования, так что любой агент должен понимать их атрибуты.
В 1992 году была завершена работа и над более специфическими классами объектов - объектами сетевого и транспортного уровней (ISO/IEC 10737-1 и ISO/ IEC 10733).
Сегодня многие организации работают над созданием классов объектов на основе GDMO. Это и международные организации по стандартизации - ISO, ITU-T, ANSI, ETSI, X/Open, и организации, разрабатывающие платформы и инструментальные средства для систем управления, такие как SunSoft, Hewlett-Packard, Vertel, ISR Global. Для телекоммуникационных сетей в рамках архитектуры TMN разработан стандарт М.3100, который описывает ряд специфических для телекоммуникационных сетей классов объектов.
Описания классов управляемых объектов OSI регистрируются как в частных ветвях дерева ISO - ветвях компаний Sun, Hewlett-Packard, IBM и т. п., так и в публичных ветвях, контролируемых ISO или другими международными органами стандартизации.
В отсутствие одной регистрирующей организации, такой как IETF Internet, использование классов объектов OSI представляет собой непростую задачу.
Правила построения сегментов Fast Ethernet при использовании повторителей
Технология Fast Ethernet, как и все некоаксиальные варианты Ethernet, рассчитана на использование концентраторов-повторителей для образования связей в сети. Правила корректного построения сегментов сетей Fast Ethernet включают:
ограничения на максимальные длины сегментов, соединяющих DTE с DTE;
ограничения на максимальные длины сегментов, соединяющих DTE с портом повторителя;
ограничения на максимальный диаметр сети;
ограничения на максимальное число повторителей и максимальную длину сегмента, соединяющего повторители.
Представительный уровень
Представительный уровень (Presentation layer) имеет дело с формой представления передаваемой по сети информации, не меняя при этом ее содержания. За счет уровня представления информация, передаваемая прикладным уровнем одной системы, всегда понятна прикладному уровню другой системы. С помощью средств данного уровня протоколы прикладных уровней могут преодолеть синтаксические различия в представлении данных или же различия в кодах символов, например кодов ASCII и EBCDIC. На этом уровне может выполняться шифрование и дешифрование данных, благодаря которому секретность обмена данными обеспечивается сразу для всех прикладных служб. Примером такого протокола является протокол Secure Socket Layer (SSL), который обеспечивает секретный обмен сообщениями для протоколов прикладного уровня стека TCP/IP.
Преимущества логической структуризации сети
Ограничения, возникающие из-за использования общей разделяемой среды, можно преодолеть, разделив сеть на несколько разделяемых сред и соединив отдельные сегменты сети такими устройствами, как мосты, коммутаторы или маршрутизаторы (рис. 4.16).

Рис. 4.16.
Логическая структуризация сети
Перечисленные устройства передают кадры с одного своего порта на другой, анализируя адрес назначения, помещенный в этих кадрах. (В отличие от концентраторов, которые повторяют кадры на всех своих портах, передавая их во все подсоединенные к ним сегменты, независимо от того, в каком из них находится станция назначения.) Мосты и коммутаторы выполняют операцию передачи кадров на основе плоских адресов канального уровня, то есть МАС - адресов, а маршрутизаторы - на основе номера сети. При этом единая разделяемая среда, созданная концентраторами (или в предельном случае - одним сегментом кабеля), делится на несколько частей, каждая из которых присоединена к порту моста, коммутатора или маршрутизатора.
Говорят, что при этом сеть делится на логические сегменты или сеть подвергается логической структуризации.
Логический сегмент представляет собой единую разделяемую среду. Деление сети на логические сегменты приводит к тому, что нагрузка, приходящаяся на каждый из вновь образованных сегментов, почти всегда оказывается меньше, чем нагрузка, которую испытывала исходная сеть. Следовательно, уменьшаются вредные эффекты от разделения среды: снижается время ожидания доступа, а в сетях Ethernet - и интенсивность коллизий.
Для иллюстрации этого эффекта рассмотрим рис. 4.17. На нем изображены два сегмента, соединенные мостом. Внутри сегментов имеются повторители. До деления сети на сегменты весь трафик, генерируемый узлами сети, был общим (представим, что место межсетевого устройства также занимал повторитель) и учитывался при определении коэффициента использования сети. Если обозначить среднюю интенсивность трафика, идущего от узла i к yзлу j через Сij, то суммарный трафик, который должна была передавать сеть до деления на сегменты, равен C? = Cij (считаем, что суммирование проводится по всем узлам).

Рис. 4.17.
Изменение нагрузки при делении сети на сегменты
После разделения сети на сегменты нагрузка каждого сегмента изменилась. При ее вычислении теперь нужно учитывать только внутрисегментный трафик, то есть трафик кадров, которые циркулируют между узлами одного сегмента, а также межсегментный трафик, который либо направляется от узла данного сегмента узлу другого сегмента, либо приходит от узла другого сегмента в узел данного сегмента. Внутренний трафик другого сегмента теперь нагрузку на данный сегмент не создает.
Поэтому нагрузка, например, сегмента S1 стала равна CS1 + CS1-S2 , где CS1
- внутренний трафик сегмента S1, а CS1-S2 - межсегментный трафик. Чтобы показать, что нагрузка сегмента S1 уменьшилась, заметим, что общую нагрузку сети до разделения на сегменты можно записать в такой форме: C?
= CS1 + CS1-S2 +CS2, a значит, нагрузка сегмента S1 после разделения стала равной C?
- CS2 , то есть уменьшилась на величину внутреннего трафика сегмента S2. А раз нагрузка на сегмент уменьшилась, то в соответствии с графиками, приведенными на рис. 4.14 и 4.15, задержки в сегментах также уменьшились, а полезная пропускная способность сегмента в целом и полезная пропускная способность, приходящаяся на один узел, увеличились.
Выше было сказано, что деление сети на логические сегменты почти
всегда уменьшает нагрузку в новых сегментах. Слово «почти» учитывает очень редкий случай, когда сеть разбита на сегменты так, что внутренний трафик каждого сегмента равен нулю, то есть весь трафик является межсегментным. Для примера из рис. 4.17 это означало бы, что все компьютеры сегмента S1 обмениваются данными только с компьютерами сегмента S2, и наоборот.
Такой случай является, естественно, экзотическим. На практике на предприятии всегда можно выделить группу компьютеров, которые принадлежат сотрудникам, выполняющим общую задачу. Это могут быть сотрудники одной рабочей группы, отдела, другого структурного подразделения предприятия. В большинстве случаев им нужен доступ к ресурсам сети их отдела и только изредка - доступ к удаленным ресурсам.
И хотя уже упомянутое эмпирическое правило, говорящее о том, что можно разделить сеть на сегменты так, что 80 % трафика составляет обращение к локальным ресурсам и только 20 % - к удаленным, сегодня трансформируется в правило 50 на 50 % и даже 20 на 80 %, все равно внутрисегментный трафик существует. Если его нет, значит, сеть разбита на логические подсети неверно.
Большинство крупных сетей разрабатывается на основе структуры с общей магистралью, к которой через мосты и маршрутизаторы присоединяются подсети. Эти подсети обслуживают различные отделы. Подсети могут делиться и далее на сегменты, предназначенные для обслуживания рабочих групп.
В общем случае деление сети на логические сегменты повышает производительность сети (за счет разгрузки сегментов), а также гибкость построения сети, увеличивая степень защиты данных, и облегчает управление сетью.
Сегментация увеличивает гибкость сети. При построении сети как совокупности подсетей каждая подсеть может быть адаптирована к специфическим потребностям рабочей группы или отдела. Например, в одной подсети может использоваться технология Ethernet и ОС NetWare, а в другой Token Ring и OS-400, в соответствии с традициями того или иного отдела или потребностями имеющихся приложений. Вместе с тем, у пользователей обеих подсетей есть возможность обмениваться данными через межсетевые устройства, такие как мосты, коммутаторы, маршрутизаторы. Процесс разбиения сети на логические сегменты можно рассматривать и в обратном направлении, как процесс создания большой сети из модулей - уже имеющихся подсетей.
Подсети повышают безопасность данных. При подключении пользователей к различным физическим сегментам сети можно запретить доступ определенных пользователей к ресурсам других сегментов. Устанавливая различные логические фильтры на мостах, коммутаторах и маршрутизаторах, можно контролировать доступ к ресурсам, чего не позволяют сделать повторители.
Подсети упрощают управление сетью. Побочным эффектом уменьшения трафика и повышения безопасности данных является упрощение управления сетью.Проблемы очень часто локализуются внутри сегмента. Как и в случае структурированной кабельной системы, проблемы одной подсети не оказывают влияния на другие подсети. Подсети образуют логические домены управления сетью.
Сети должны проектироваться на двух уровнях: физическом и логическом. Логическое проектирование определяет места расположения ресурсов, приложений и способы группировки этих ресурсов в логические сегменты.
Прикладной уровень
Прикладной уровень (Application layer) - это в действительности просто набор разнообразных протоколов, с помощью которых пользователи сети получают доступ к разделяемым ресурсам, таким как файлы, принтеры или гипертекстовые Web-страницы, а также организуют свою совместную работу, например, с помощью протокола электронной почты. Единица данных, которой оперирует прикладной уровень, обычно называется сообщением (message).
Существует очень большое разнообразие служб прикладного уровня. Приведем в качестве примера хотя бы несколько наиболее распространенных реализации файловых служб: NCP в операционной системе Novell NetWare, SMB в Microsoft Windows NT, NFS, FTP и TFTP, входящие в стек TCP/IP.
Прикладной уровень
объединяет все службы, предоставляемые системой пользовательским приложениям. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое количество протоколов и служб прикладного уровня. Прикладной уровень реализуется программными системами, построенными в архитектуре клиент-сервер, базирующимися на протоколах нижних уровней. В отличие от протоколов остальных трех уровней, протоколы прикладного уровня занимаются деталями конкретного приложения и «не интересуются» способами передачи данных по сети. Этот уровень постоянно расширяется за счет присоединения к старым, прошедшим многолетнюю эксплуатацию сетевым службам типа Telnet, FTP, TFTP, DNS, SNMP сравнительно новых служб таких, например, как протокол передачи гипертекстовой информации HTTP.
Применение цифровых первичных сетей
Сети SDH и сети плезиохронной цифровой иерархии очень широко используются для построения как публичных, так и корпоративных сетей. Особенно популярны их услуги в США, где большинство крупных корпоративных сетей построено на базе выделенных цифровых каналов. Эти каналы непосредственно соединяют маршрутизаторы, размещаемые на границе локальных сетей отделений корпорации.
При аренде выделенного канала сетевой интегратор всегда уверен, что между локальными сетями существует канал вполне определенной пропускной способности. Это положительная черта аренды выделенных каналов. Однако при относительно небольшом количестве объединяемых локальных сетей пропускная способность выделенных каналов никогда не используется на 100 %, и это недостаток монопольного владения каналом - предприятие всегда платит не за реальную пропускную способность. В связи с этим обстоятельством в последнее время все большую популярность приобретает служба сетей frame relay, в которых каналы разделяют несколько предприятий.
На основе первичной сети SDH можно строить сети с коммутацией пакетов, например frame или АТМ, или же сети с коммутацией каналов, например ISDN. Технология АТМ облегчила эту задачу, приняв стандарты SDH в качестве основных стандартов физического уровня. Поэтому при существовании инфраструктуры SDH для образования сети АТМ достаточно соединить АТМ-коммутаторы жестко сконфигурированными в сети SDH-каналами.
Телефонные коммутаторы также могут использовать технологию цифровой иерархии, поэтому построение телефонной сети с помощью каналов PDH или SONET/SDH не представляет труда. На рис. 6.11. показан пример сосуществования двух сетей - компьютерной и телефонной - на основе выделенных каналов одной и той же первичной цифровой сети.

Рис. 6.11.
Использование цифровой первичной сети для организации двух наложенных сетей - вычислительной и телефонной
Технология SONET/SDH очень экономично решает задачу мультиплексирования и коммутации потоков различной скорости, поэтому сегодня она, несмотря на невозможность динамического перераспределения пропускной способности между абонентскими каналами, является наиболее распространенной технологией создания первичных сетей.
Технология АТМ, которая хотя и позволяет динамически перераспределять пропускную способность каналов, получилась значительно сложнее, и уровень накладных расходов у нее гораздо выше.
Примером российских сетей SDH могут служить сети «Макомнет», «Метро-ком» и «Раском», построенные совместными предприятиями с участием американской компании Andrew Corporation.
Начало создания сети «Макомнет» относится к 1991 году, когда было образовано совместное предприятие, учредителями которого выступили Московский метрополитен и компания Andrew Corporation.
Транспортной средой сети стали одномодовые 32-, 16-и 8-жильные волоконно-оптические кабели фирмы Pirelli, проложенные в туннелях метрополитена. В метро было уложено более 350 км кабеля. Постоянно расширяясь, сегодня кабельная система «Макомнет» с учетом соединений «последней мили» имеет длину уже более 1000 километров.
Изначально в сети «Макомнет» использовалось оборудование SDH только 1 уровня (155 Мбит/с) - мультиплексоры TN-1X фирмы Northern Telecom (Nortel), обладающие функциями коммутации 63 каналов Е1 по 2 Мбит/с каждый. Из данных мультиплексоров были организованы две кольцевые топологии «Восточная» и «Западная» (они разделили кольцевую линию метрополитена на два полукольца вдоль Сокольнической линии) и несколько отрезков «точка-точка», протянувшихся к ряду клиентов, абонировавших сравнительно большие емкости сети. Эти кольца образовали магистраль сети, от которой ответвлялись связи с абонентами.
Растущие день ото дня потребности заказчиков заставляли создавать новые топологии и переконфигурировать старые. В течение двух лет в сети «Макомнет» задача увеличения пропускной способности решалась за счет прокладки новых кабелей и установки нового оборудования, что позволило утроить количество топологий по кольцевой линии. Число узлов коммутации возросло до семидесяти. Но настал момент, когда остро встал вопрос о количестве резервных оптических волокон на некоторых участках сети, и с учетом прогнозов на развитие было принято решение о построении нового, 4-го уровня SDH (622 Мбит/с).
Подготовительные работы по переконфигурированию и введению действующих потоков в сеть нового уровня происходили без прекращения работы сети в целом. В качестве оборудования 4 уровня (622 Мбит/с) были установлены мультиплексоры TN-4X фирмы Nortel. Вместе с новым оборудованием была приобретена принципиально новая высокоинтеллектуальная система управления NRM (Network Resource Manager). Эта система является надстройкой над системами управления оборудования 1 и 4 уровней. Она обладает не только всеми функциями контроля оборудования, присущими каждой из систем, но и рядом дополнительных возможностей: автоматической прокладки канала по сети, когда оператору требуется лишь указать начальную и конечную точки; функциями инвентаризации каналов, обеспечивающих их быстрый поиск в системе, и рядом других.
Ввод всего шести узлов TN-4X значительно увеличил транспортную емкость сети, а высвободившиеся волокна сделали возможным ее дальнейшее наращивание.
На первых порах клиентами «Макомнет» стали телекоммуникационные компании, использующие каналы «Макомнет» для строительства собственных сетей. Однако со временем круг клиентов значительно расширился: банки, различные коммерческие и государственные структуры. Оборудование компании расположено на территории многих городских, а также основных международных и междугородных телефонных станций.
Примеры таблиц различных типов маршрутизаторов
Структура таблицы маршрутизации стека TCP/IP соответствует общим принципам построения таблиц маршрутизации, рассмотренным выше. Однако важно отметить, что вид таблицы IP-маршрутизации зависит от конкретной реализации стека TCP/IP. Приведем пример трех вариантов таблицы маршрутизации, с которыми мог бы работать маршрутизатор Ml в сети, представленной на рис. 5.13.

Рис. 5.13. Пример маршрутизируемой сети
Если представить, что в качестве маршрутизатора Ml в данной сети работает штатный программный маршрутизатор MPR операционной системы Microsoft Windows NT, то его таблица маршрутизации могла бы иметь следующий вид (табл. 5.9).
Таблица 5.9. Таблица программного маршрутизатора MPR Windows NT

Если на месте маршрутизатора М1 установить аппаратный маршрутизатор NetBuilder II компании 3 Com, то его таблица маршрутизации для этой же сети может выглядеть так, как показано в табл. 5.10.
Таблица 5.10. Таблица маршрутизации аппаратного маршрутизатора NetBuilder II компании 3 Com

Таблица 5.11 представляет собой таблицу маршрутизации для маршрутизатора Ml, реализованного в виде программного маршрутизатора одной из версий операционной системы Unix.
Таблица 5.11. Таблица маршрутизации Unix-маршрутизатора

ПРИМЕЧАНИЕ Заметим, что поскольку между структурой сети и таблицей маршрутизации в принципе нет однозначного соответствия, то и для каждого из приведенных вариантов таблицы можно предложить свои «подварианты», отличающиеся выбранным маршрутом к той или иной сети. В данном случае внимание концентрируется на существенных различиях в форме представления маршрутной информации разными реализациями маршрутизаторов.
Примитивы протокола SNMP
SNMP - это протокол типа «запрос-ответ», то есть на каждый запрос, поступивший от менеджера, агент должен передать ответ. Особенностью протокола является его чрезвычайная простота - он включает в себя всего несколько команд.
Команда Get-request используется менеджером для получения от агента значения какого-либо объекта по его имени.
Команда GetNext-request используется менеджером для извлечения значения следующего объекта (без указания его имени) при последовательном просмотре таблицы объектов.
С помощью команды Get-response агент SNMP передает менеджеру ответ на команды Get-request или GetNext-request.
Команда Set
используется менеджером для изменения значения какого-либо объекта. С помощью команды Set
происходит собственно управление устройством. Агент должен понимать смысл значений объекта, который используется для управления устройством, и на основании этих значений выполнять реальное управляющее воздействие - отключить порт, приписать порт определенной VLAN и т. п. Команда Set
пригодна также для установки условия, при выполнении которого агент SNMP должен послать менеджеру соответствующее сообщение. Может быть определена реакция на такие события, как инициализация агента, рестарт агента, обрыв связи, восстановление связи, неверная аутентификация и потеря ближайшего маршрутизатора. Если происходит любое из этих событий, то агент инициализирует прерывание.
Команда Trap
используется агентом для сообщения менеджеру о возникновении особой ситуации.
Версия SNMP v.2 добавляет к этому набору команду GetBulk, которая позволяет менеджеру получить несколько значений переменных за один запрос.
Принцип коммутации пакетов с использованием техники виртуальных каналов
Техника виртуальных каналов, используемая во всех территориальных сетях с коммутацией пакетов, кроме TCP/IP, состоит в следующем.
Прежде чем пакет будет передан через сеть, необходимо установить виртуальное соединение между абонентами сети - терминалами, маршрутизаторами или компьютерами. Существуют два типа виртуальных соединений - коммутируемый виртуальный канал (Switched Virtual Circuit, SVC) и постоянный виртуальный канал (Permanent Virtual Circuit, PVC). При создании коммутируемого виртуального канала коммутаторы сети настраиваются на передачу пакетов динамически, по запросу абонента, а создание постоянного виртуального канала происходит заранее, причем коммутаторы настраиваются вручную администратором сети, возможно, с привлечением централизованной системы управления сетью.
Смысл создания виртуального канала состоит в том, что маршрутизация пакетов между коммутаторами сети на основании таблиц маршрутизации происходит только один раз - при создании виртуального канала (имеется в виду создание коммутируемого виртуального канала, поскольку создание постоянного виртуального канала осуществляется вручную и не требует передачи пакетов по сети). После создания виртуального канала передача пакетов коммутаторами происходит на основании так называемых номеров или идентификаторов виртуальных каналов (Virtual Channel Identifier, VCI). Каждому виртуальному каналу присваивается значение VCI на этапе создания виртуального канала, причем это значение имеет не глобальный характер, как адрес абонента, а локальный - каждый коммутатор самостоятельно нумерует новый виртуальный канал. Кроме нумерации виртуального канала, каждый коммутатор при создании этого канала автоматически настраивает так называемые таблицы коммутации портов - эти таблицы описывают, на какой порт нужно передать пришедший пакет, если он имеет определенный номер VCI. Так что после прокладки виртуального канала через сеть коммутаторы больше не используют для пакетов этого соединения таблицу маршрутизации, а продвигают пакеты на основании номеров VCI небольшой разрядности.
Сами таблицы коммутации портов также включают обычно меньше записей, чем таблицы маршрутизации, так как хранят данные только о действующих на данный момент соединениях, проходящих через данный порт.
Работа сети по маршрутизации пакетов ускоряется за счет двух факторов. Первый состоит в том, что решение о продвижении пакета принимается быстрее из-за меньшего размера таблицы коммутации. Вторым фактором является уменьшение доли служебной информации в пакетах. Адреса конечных узлов в глобальных сетях обычно имеют достаточно большую длину - 14-15 десятичных цифр, которые занимают до 8 байт (в технологии АТМ - 20 байт) в служебном поле пакета. Номер же виртуального канала обычно занимает 10-12 бит, так что накладные расходы на адресную часть существенно сокращаются, а значит, полезная скорость передачи данных возрастает.
Режим PVC является особенностью технологии маршрутизации пакетов в глобальных сетях, в сетях TCP/IP такого режима работы нет. Работа в режиме PVC является наиболее эффективной по критерию производительности сети. Половину работы по маршрутизации пакетов администратор сети уже выполнил, поэтому коммутаторы быстро занимаются продвижением кадров на основе готовых таблиц коммутации портов. Постоянный виртуальный канал подобен выделенному каналу в том, что не требуется устанавливать соединение или разъединение. Обмен пакетами по PVC может происходить в любой момент времени. Отличие PVC в сетях Х.25 от выделенной линии типа 64 Кбит/с состоит в том, что пользователь не имеет никаких гарантий относительно действительной пропускной способности PVC. Использование PVC обычно намного дешевле, чем аренда выделенной линии, так как пользователь делит пропускную способность сети с другими пользователями.
Режим продвижения пакетов на основе готовой таблицы коммутации портов обычно называют не маршрутизацией, а коммутацией и относят не к третьему, а ко второму (канальному) уровню стека протоколов.
Принцип маршрутизации пакетов на основе виртуальных каналов поясняется на рис. 6.21.
При установлении соединения между конечными узлами используется специальный тип пакета - запрос на установление соединения (обычно называемый Call Request), который содержит многоразрядный (в примере семиразрядный) адрес узла назначения.

Рис. 6.21.
Коммутация в сетях с виртуальными соединениями
Пусть конечный узел с адресом 1581120 начинает устанавливать виртуальное соединение с узлом с адресом 1581130. Одновременно с адресом назначения в пакете Call Request указывается и номер виртуального соединения VCI. Этот номер имеет локальное значение для порта компьютера, через который устанавливается соединение. Через один порт можно установить достаточно большое количество виртуальных соединений, поэтому программное обеспечение протокола глобальной сети в компьютере просто выбирает свободный в данный момент для данного порта номер. Если через порт уже проложено 3 виртуальных соединения, то для нового соединения будет выбран номер 4, по которому всегда можно будет отличить пакеты данного соединения от пакетов других соединений, приходящих на этот порт.
Далее пакет типа Call Request с адресом назначения 1581130, номером VCI 4 и адресом источника 1581120 отправляется в порт 1 коммутатора К1 сети. Адрес назначения используется для маршрутизации пакета на основании таблиц маршрутизации, аналогичных таблицам маршрутизации протокола IP, но с более простой структурой каждой записи. Запись состоит из адреса назначения и номера порта, на который нужно переслать пакет. Адрес следующего коммутатора не нужен, так как все связи между коммутаторами являются связями типа «точка-точка», множественных соединений между портами нет. Стандарты глобальных сетей обычно не описывают какой-либо протокол обмена маршрутной информацией, подобный RIP или OSPF, позволяющий коммутаторам сети автоматически строить таблицы маршрутизации. Поэтому в таких сетях администратор обычно вручную составляет подобную таблицу, указывая для обеспечения отказоустойчивости основной и резервный пути для каждого адреса назначения.
Исключением являются сети АТМ, для которых разработан протокол маршрутизации PNNI, основанный на алгоритме состояния связей.
В приведенном примере в соответствии с таблицей маршрутизации оказалось необходимым передать пакет Call Request с порта 1 на порт 3. Одновременно с передачей пакета маршрутизатор изменяет номер виртуального соединения пакета - он присваивает пакету первый свободный номер виртуального канала для выходного порта данного коммутатора. Каждый конечный узел и каждый коммутатор ведет свой список занятых и свободных номеров виртуальных соединений для всех своих портов. Изменение номера виртуального канала делается для того, чтобы при продвижении пакетов в обратном направлении (а виртуальные каналы обычно работают в дуплексном режиме), можно было отличить пакеты данного виртуального канала от пакетов других виртуальных каналов, уже проложенных через порт 3. В примере через порт 3 уже проходит несколько виртуальных каналов, причем самый старший занятый номер - это номер 9. Поэтому коммутатор меняет номер прокладываемого виртуального канала с 4 на 10.
Кроме таблицы маршрутизации для каждого порта составляется таблица коммутации. В таблице коммутации входного порта 1 маршрутизатор отмечает, что в дальнейшем пакеты, прибывшие на этот порт с номером VCI равным 4 должны передаваться на порт 3, причем номер виртуального канала должен быть изменен на 10. Одновременно делается и соответствующая запись в таблице коммутации порта 3 - пакеты, пришедшие по виртуальному каналу 10 в обратном направлении нужно передавать на порт с номером 1, меняя номер виртуального канала на 4. Таким образом, при получении пакетов в обратном направлении компьютер-отправитель получает пакеты с тем же номером VCI, с которым он отправлял их в сеть.
В результате действия такой схемы пакеты данных уже не несут длинные адреса конечных узлов, а имеют в служебном поле только номер виртуального канала, на основании которого и производится маршрутизация всех пакетов, кроме пакета запроса на установление соединения.
В сети прокладывается виртуальный канал, который не изменяется в течение всего времени существования соединения. Его номер меняется от коммутатора к коммутатору, но для конечных узлов он остается постоянным.
За уменьшение служебного заголовка приходится платить невозможностью баланса трафика внутри виртуального соединения. При отказе какого-либо канала соединение приходится также устанавливать заново.
По существу, техника виртуальных каналов позволяет реализовать два режима продвижения пакетов - стандартный режим маршрутизации пакета на основании адреса назначения и режим коммутации пакетов на основании номера виртуального канала. Эти режимы применяются поэтапно, причем первый этап состоит в маршрутизации всего одного пакета - запроса на установление соединения.
Техника виртуальных каналов имеет свои достоинства и недостатки по сравнению с техникой IP- или IPX-маршрутизации. Маршрутизация каждого пакета без предварительного установления соединения (ни IP, ни IPX не работают с установлением соединения) эффективна для кратковременных потоков данных. Кроме того, возможно распараллеливание трафика для повышения производительности сети при наличии параллельных путей в сети. Быстрее отрабатывается отказ маршрутизатора или канала связи, так как последующие пакеты просто пойдут по новому пути (здесь, правда, нужно учесть время установления новой конфигурации в таблицах маршрутизации). При использовании виртуальных каналов очень эффективно передаются через сеть долговременные потоки, но для кратковременных этот режим не очень подходит, так как на установление соединения обычно уходит много времени - даже коммутаторы технологии АТМ, работающие на очень высоких скоростях, тратят на установление соединения по 5-10 мс каждый. Из-за этого обстоятельства компания Ipsilon разработала несколько лет назад технологию IP-switching, которая вводила в сети АТМ, работающие по описанному принципу виртуальных каналов, режим передачи ячеек без предварительного установления соединения. Эта технология действительно ускоряла передачу через сеть кратковременных потоков IP-пакетов, поэтому она стала достаточно популярной, хотя и не приобрела статус стандарта.В главе 5 были рассмотрены методы ускорения маршрутизации трафика IP в локальных сетях. Особенностью всех подобных методов является ускорение передачи долговременных потоков пакетов. Технология IP-switching делает то же самое, но для кратковременных потоков, что хорошо отражает рассмотренные особенности каждого метода маршрутизации - маршрутизации на индивидуальной основе или на основе потоков пакетов, для которых прокладывается виртуальный канал.
Принципы коммутации пакетов
Коммутация пакетов - это техника коммутации абонентов, которая была специально разработана для эффективной передачи компьютерного трафика. Эксперименты по созданию первых компьютерных сетей на основе техники коммутации каналов показали, что этот вид коммутации не позволяет достичь высокой общей пропускной способности сети. Суть проблемы заключается в пульсирующем характере трафика, который генерируют типичные сетевые приложения. Например, при обращении к удаленному файловому серверу пользователь сначала просматривает содержимое каталога этого сервера, что порождает передачу небольшого объема данных. Затем он открывает требуемый файл в текстовом редакторе, и эта операция может создать достаточно интенсивный обмен данными, особенно если файл содержит объемные графические включения. После отображения нескольких страниц файла пользователь некоторое время работает с ними локально, что вообще не требует передачи данных по сети, а затем возвращает модифицированные копии страниц на сервер - и это снова порождает интенсивную передачу данных по сети.
Коэффициент пульсации трафика отдельного пользователя сети, равный отношению средней интенсивности обмена данными к максимально возможной, может составлять 1:50 или 1:100. Если для описанной сессии организовать коммутацию канала между компьютером пользователя и сервером, то большую часть времени канал будет простаивать. В то же время коммутационные возможности сети будут использоваться - часть тайм-слотов или частотных полос коммутаторов будет занята и недоступна другим пользователям сети.
При коммутации пакетов все передаваемые пользователем сети сообщения разбиваются в исходном узле на сравнительно небольшие части, называемые пакетами. Напомним, что сообщением называется логически завершенная порция данных - запрос на передачу файла, ответ на этот запрос, содержащий весь файл, и т. п. Сообщения могут иметь произвольную длину, от нескольких байт до многих мегабайт. Напротив, пакеты обычно тоже могут иметь переменную длину, но в узких пределах, например от 46 до 1500 байт.
Каждый пакет снабжается заголовком, в котором указывается адресная информация, необходимая для доставки пакета узлу назначения, а также номер пакета, который будет использоваться узлом назначения для сборки сообщения (рис. 2.29). Пакеты транспортируются в сети как независимые информационные блоки. Коммутаторы сети принимают пакеты от конечных узлов и на основании адресной информации передают их друг другу, а в конечном итоге - узлу назначения.

Рис. 2.29. Разбиение сообщения на пакеты
Коммутаторы пакетной сети отличаются от коммутаторов каналов тем, что они имеют внутреннюю буферную память для временного хранения пакетов, если выходной порт коммутатора в момент принятия пакета занят передачей другого пакета (рис. 2.30). В этом случае пакет находится некоторое время в очереди пакетов в буферной памяти выходного порта, а когда до него дойдет очередь, то он передается следующему коммутатору. Такая схема передачи данных позволяет сглаживать пульсации трафика на магистральных связях между коммутаторами и тем самым использовать их наиболее эффективным образом для повышения пропускной способности сети в целом.

Рис. 2.30. Сглаживание пульсаций трафика в сети с коммутацией пакетов
Действительно, для пары абонентов наиболее эффективным было бы предоставление им в единоличное пользование скоммутированного канала связи, как это делается в сетях с коммутацией каналов. При этом способе время взаимодействия этой пары абонентов было бы минимальным, так как данные без задержек передавались бы от одного абонента другому. Простои канала во время пауз передачи абонентов не интересуют, для них важно быстрее решить свою собственную задачу. Сеть с коммутацией пакетов замедляет процесс взаимодействия конкретной пары абонентов, так как их пакеты могут ожидать в коммутаторах, пока по магистральным связям передаются другие пакеты, пришедшие в коммутатор ранее.
Тем не менее общий объем передаваемых сетью компьютерных данных в единицу времени при технике коммутации пакетов будет выше, чем при технике коммутации каналов.
Это происходит потому, что пульсации отдельных абонентов в соответствии с законом больших чисел распределяются во времени. Поэтому коммутаторы постоянно и достаточно равномерно загружены работой, если число обслуживаемых ими абонентов действительно велико. На рис. 2.30 показано, что трафик, поступающий от конечных узлов на коммутаторы, очень неравномерно распределен во времени. Однако коммутаторы более высокого уровня иерархии, которые обслуживают соединения между коммутаторами нижнего уровня, загружены более равномерно, и поток пакетов в магистральных каналах, соединяющих коммутаторы верхнего уровня, имеет почти максимальный коэффициент использования.
Более высокая эффективность сетей с коммутацией пакетов по сравнению с сетями с коммутацией каналов (при равной пропускной способности каналов связи) была доказана в 60-е годы как экспериментально, так и с помощью имитационного моделирования. Здесь уместна аналогия с мультипрограммными операционными системами. Каждая отдельная программа в такой системе выполняется дольше, чем в однопрограммной системе, когда программе выделяется все процессорное время, пока она не завершит свое выполнение. Однако общее число программ, выполняемых за единицу времени, в мультипрограммной системе больше, чем в однопрограммной.
Принципы маршрутизации
Важнейшей задачей сетевого уровня является маршрутизация - передача пакетов между двумя конечными узлами в составной сети.
Рассмотрим принципы маршрутизации на примере составной сети, изображенной на рис. 5.2. В этой сети 20 маршрутизаторов объединяют 18 сетей в общую сеть; S1, S2, ... , S20 - это номера сетей. Маршрутизаторы имеют по нескольку портов (по крайней мере, по два), к которым присоединяются сети. Каждый порт маршрутизатора можно рассматривать как отдельный узел сети: он имеет собственный сетевой адрес и собственный локальный адрес в той подсети, которая к нему подключена. Например, маршрутизатор под номером 1 имеет три порта, к которым подключены сети S1, S2, S3. На рисунке сетевые адреса этих портов обозначены как М1(1), Ml (2) и М1(3). Порт М1(1) имеет локальный адрес в сети с номером S1, порт Ml (2) - в сети S2, а порт М1(3) - в сети S3. Таким образом, маршрутизатор можно рассматривать как совокупность нескольких узлов, каждый из которых входит в свою сеть. Как единое устройство маршрутизатор не имеет ни отдельного сетевого адреса, ни какого-либо локального адреса.

Рис. 5.2.
Принципы маршрутизации в составной сети
ПРИМЕЧАНИЕ Если маршрутизатор имеет блок управления (например, SNMP-управления), то этот блок имеет собственные локальный и сетевой адреса, по которым к нему обращается центральная станция управления, находящаяся где-то в составной сети.
В сложных составных сетях почти всегда существует несколько альтернативных маршрутов для передачи пакетов между двумя конечными узлами. Маршрут - это последовательность маршрутизаторов, которые должен пройти пакет от отправителя до пункта назначения. Так, пакет, отправленный из узла А в узел В, может пройти через маршрутизаторы 17, 12, 5, 4 и 1 или маршрутизаторы 17,13, 7, 6 и З. Нетрудно найти еще несколько маршрутов между узлами А и В.
Задачу выбора маршрута из нескольких возможных решают маршрутизаторы, а также конечные узлы. Маршрут выбирается на основании имеющейся у этих устройств информации о текущей конфигурации сети, а также на основании указанного критерия выбора маршрута.
Обычно в качестве критерия выступает задержка прохождения маршрута отдельным пакетом или средняя пропускная способность маршрута для последовательности пакетов. Часто также используется весьма простой критерий, учитывающий только количество пройденных в маршруте промежуточных маршрутизаторов (хопов).
Чтобы по адресу сети назначения можно было бы выбрать рациональный маршрут дальнейшего следования пакета, каждый конечный узел и маршрутизатор анализируют специальную информационную структуру, которая называется таблицей маршрутизации. Используя условные обозначения для сетевых адресов маршрутизаторов и номеров сетей в том виде, как они приведены на рис. 5.2, посмотрим, как могла бы выглядеть таблица маршрутизации, например, в маршрутизаторе 4 (табл. 5.1).
Таблица 5.1. Таблица маршрутизации маршрутизатора 4

ПРИМЕЧАНИЕ Таблица 5.1 значительно упрощена по сравнению с реальными таблицами, например, отсутствуют столбцы с масками, признаками состояния маршрута, временем, в течение которого действительны записи данной таблицы (их применение будет рассмотрено позже). Кроме того, как уже было сказано, здесь указаны адреса сетей условного формата, не соответствующие какому-либо определенному сетевому протоколу. Тем не менее эта таблица содержит основные поля, имеющиеся в реальных таблицах при использовании конкретных сетевых протоколов, таких как IP, IPX или Х.25.
В первом столбце таблицы перечисляются номера сетей, входящих в интерсеть. В каждой строке таблицы следом за номером сети указывается сетевой адрес следующего маршрутизатора (более точно, сетевой адрес соответствующего порта следующего маршрутизатора), на который надо направить пакет, чтобы тот передвигался по направлению к сети с данным номером по рациональному маршруту.
Когда на маршрутизатор поступает новый пакет, номер сети назначения, извлеченный из поступившего кадра, последовательно сравнивается с номерами сетей из каждой строки таблицы. Строка с совпавшим номером сети указывает, на какой ближайший маршрутизатор следует направить пакет.
Например, если на какой-либо порт маршрутизатора 4 поступает пакет, адресованный в сеть S6, то из таблицы маршрутизации следует, что адрес следующего маршрутизатора - М2(1), то есть очередным этапом движения данного пакета будет движение к порту 1 маршрутизатора 2.
Поскольку пакет может быть адресован в любую сеть составной сети, может показаться, что каждая таблица маршрутизации должна иметь записи обо всех сетях, входящих в составную сеть. Но при таком подходе в случае крупной сети объем таблиц маршрутизации может оказаться очень большим, что повлияет на время ее просмотра, потребует много места для хранения и т. п. Поэтому на практике число записей в таблице маршрутизации стараются уменьшить за счет использования специальной записи - «маршрутизатор по умолчанию» (default). Действительно, если принять во внимание топологию составной сети, то в таблицах маршрутизаторов, находящихся на периферии составной сети, достаточно записать номера сетей, непосредственно подсоединенных к данному маршрутизатору или расположенных поблизости, на тупиковых маршрутах. Обо всех же остальных сетях можно сделать в таблице единственную запись, указывающую на маршрутизатор, через который пролегает путь ко всем этим сетям. Такой маршрутизатор называется маршрутизатором по умолчанию, а вместо номера сети в соответствующей строке помещается особая запись, например default. В нашем примере таким маршрутизатором по умолчанию для сети S5 является маршрутизатор 5, точнее его порт М5(1). Это означает, что путь из сети S5 почти ко всем сетям большой составной сети пролегает через этот порт маршрутизатора.
Перед тем как передать пакет следующему маршрутизатору, текущий маршрутизатор должен определить, на какой из нескольких собственных портов он должен поместить данный пакет. Для этого служит третий столбец таблицы маршрутизации. Еще раз подчеркнем, что каждый порт идентифицируется собственным сетевым адресом.
Некоторые реализации сетевых протоколов допускают наличие в таблице маршрутизации сразу нескольких строк, соответствующих одному и тому же адресу сети назначения.
В этом случае при выборе маршрута принимается во внимание столбец «Расстояние до сети назначения». При этом под расстоянием понимается любая метрика, используемая в соответствии с заданным в сетевом пакете критерием (часто называемым классом сервиса). Расстояние может измеряться хопами, временем прохождения пакета по линиям связи, какой-либо характеристикой надежности линий связи на данном маршруте или другой величиной, отражающей качество данного маршрута по отношению к заданному критерию. Если маршрутизатор поддерживает несколько классов сервиса пакетов, то таблица маршрутов составляется и применяется отдельно для каждого вида сервиса (критерия выбора маршрута).
В табл. 5.1 расстояние между сетями измерялось хопами. Расстояние для сетей, непосредственно подключенных к портам маршрутизатора, здесь принимается равным 0, однако в некоторых реализациях отсчет расстояний начинается с 1.
Наличие нескольких маршрутов к одному узлу делают возможным передачу трафика к этому узлу параллельно по нескольким каналам связи, это повышает пропускную способность и надежность сети.
Задачу маршрутизации решают не только промежуточные узлы - маршрутизаторы, но и конечные узлы - компьютеры. Средства сетевого уровня, установленные на конечном узле, при обработке пакета должны, прежде всего, определить, направляется ли он в другую сеть или адресован какому-нибудь узлу данной сети. Если номер сети назначения совпадает с номером данной сети, то для данного пакета не требуется решать задачу маршрутизации. Если же номера сетей отправления и назначения не совпадают, то маршрутизация нужна. Таблицы маршрутизации конечных узлов полностью аналогичны таблицам маршрутизации, хранящимся на маршрутизаторах.
Обратимся снова к сети, изображенной на рис. 5.2. Таблица маршрутизации для конечного узла В могла бы выглядеть следующим образом (табл. 5.2). Здесь MB - сетевой адрес порта компьютера В. На основании этой таблицы конечный узел В выбирает, на какой из двух имеющихся в локальной сети S3 маршрутизаторов следует посылать тот или иной пакет.
Таблица 5.2.
Таблица маршрутизации конечного узла В

Конечные узлы в еще большей степени, чем маршрутизаторы, пользуются приемом маршрутизации по умолчанию. Хотя они также в общем случае имеют в своем распоряжении таблицу маршрутизации, ее объем обычно незначителен, что объясняется периферийным расположением всех конечных узлов. Конечный узел часто вообще работает без таблицы маршрутизации, имея только сведения об адресе маршрутизатора по умолчанию. При наличии одного маршрутизатора в локальной сети этот вариант - единственно возможный для всех конечных узлов. Но даже при наличии нескольких маршрутизаторов в локальной сети, когда перед конечным узлом стоит проблема их выбора, задание маршрута по умолчанию часто используется в компьютерах для сокращения объема их таблицы маршрутизации.
Ниже помещена таблица маршрутизации другого конечного узла составной сети - узла А (табл. 5.3). Компактный вид таблицы маршрутизации отражает тот факт, что все пакеты, направляемые из узла А, либо не выходят за пределы сети S12, либо непременно проходят через порт 1 маршрутизатора 17. Этот маршрутизатор и определен в таблице маршрутизации в качестве маршрутизатора по умолчанию.
Таблица 5.3. Таблица маршрутизации конечного узла А

Еще одним отличием работы маршрутизатора и конечного узла при выборе маршрута является способ построения таблицы маршрутизации. Если маршрутизаторы обычно автоматически создают таблицы маршрутизации, обмениваясь служебной информацией, то для конечных узлов таблицы маршрутизации часто создаются вручную администраторами и хранятся в виде постоянных файлов на дисках.
Принципы объединения сетей на основе протоколов сетевого уровня
В стандартной модели взаимодействия открытых систем в функции сетевого уровня входит решение следующих задач:
передача пакетов между конечными узлами в составных сетях;
выбор маршрута передачи пакетов, наилучшего по некоторому критерию;
согласование разных протоколов канального уровня, использующихся в отдельных подсетях одной составной сети.
Протоколы сетевого уровня реализуются, как правило, в виде программных модулей и выполняются на конечных узлах-компьютерах, называемых хостами, а также на промежуточных узлах - маршрутизаторах, называемых шлюзами. Функции маршрутизаторов могут выполнять как специализированные устройства, так и универсальные компьютеры с соответствующим программным обеспечением.
Приоритетная обработка кадров
Построение сетей на основе коммутаторов позволяет использовать приоритезацию трафика, причем делать это независимо от технологии сети. Эта новая возможность (по сравнению с сетями, построенными целиком на концентраторах) является следствием того, что коммутаторы буферизуют кадры перед их отправкой на другой порт. Коммутатор обычно ведет для каждого входного и выходного порта не одну, а несколько очередей, причем каждая очередь имеет свой приоритет обработки. При этом коммутатор может быть сконфигурирован, например, так, чтобы передавать один низкоприоритетный пакет на каждые 10 высокоприоритетных пакетов.
Поддержка приоритетной обработки может особенно пригодиться для приложений, предъявляющих различные требования к допустимым задержкам кадров и к пропускной способности сети для потока кадров.
Приоритезация трафика коммутаторами сегодня является одним из основных механизмов обеспечения качества транспортного обслуживания в локальных сетях. Это, естественно, не гарантированное качество обслуживания, а только механизм best effort - «с максимальными усилиями». К каким уровням задержек приводит приписывание того или иного уровня приоритета кадру, какую пропускную способность обеспечивает приоритет потоку кадров - схема приоритезации не говорит. Выяснить последствия ее применения можно только путем проведения натурных экспериментов или же с помощью имитационного моделирования. Ясно только одно - более приоритетные кадры будут обрабатываться раньше менее приоритетных, поэтому все показатели качества обслуживания у них будут выше, чем у менее приоритетных. Остается вопрос - насколько? Гарантии качества обслуживания дают другие схемы, которые основаны на предварительном резервировании качества обслуживания. Например, такие схемы используются в технологиях глобальных сетей frame relay и АТМ или в протоколе RSVP для сетей TCP/IP. Однако для коммутаторов такого рода протоколов нет, так что гарантий качества обслуживания они пока дать не могут.
Основным вопросом при приоритетной обработке кадров коммутаторами является вопрос назначения кадру приоритета.
Так как не все протоколы канального уровня поддерживают поле приоритета кадра, например у кадров Ethernet оно отсутствует, то коммутатор должен использовать какой-либо дополнительный механизм для связывания кадра с его приоритетом. Наиболее распространенный способ - приписывание приоритета портам коммутатора. При этом способе коммутатор помещает кадр в очередь кадров соответствующего приоритета в зависимости от того, через какой порт поступил кадр в коммутатор. Способ несложный, но недостаточно гибкий - если к порту коммутатора подключен не отдельный узел, а сегмент, то все узлы сегмента получают одинаковый приоритет.
Многие компании, выпускающие коммутаторы, реализовали в них ту или иную схему приоритетной обработки кадров. Примером фирменного подхода к назначению приоритетов на основе портов является технология РАСЕ компании 3Com.
Более гибким является назначение приоритетов кадрам в соответствии с достаточно новым стандартом IEEE 802.1р. Этот стандарт разрабатывался совместно со стандартом 802.10, который рассматривается в следующем разделе, посвященном виртуальным локальным сетям. В обоих стандартах предусмотрен общий дополнительный заголовок для кадров Ethernet, состоящий из двух байт. В этом дополнительном заголовке, который вставляется перед полем данных кадра, 3 бита используются для указания приоритета кадра. Существует протокол, по которому конечный узел может запросить у коммутатора один из восьми уровней приоритета кадра. Если сетевой адаптер не поддерживает стандарт 802.1р, то коммутатор может назначать приоритеты кадрам на основе порта поступления кадра. Такие помеченные кадры будут обслуживаться в соответствии с их приоритетом всеми коммутаторами сети, а не только тем коммутатором, который непосредственно принял кадр от конечного узла. При передаче кадра сетевому адаптеру, не поддерживающему стандарт 802.1р, дополнительный заголовок должен быть удален.
Приоритетный доступ к кольцу
Каждый кадр данных или маркер имеет приоритет, устанавливаемый битами приоритета (значение от 0 до 7, причем 7 - наивысший приоритет). Станция может воспользоваться маркером, если только у нее есть кадры для передачи с приоритетом равным или большим, чем приоритет маркера. Сетевой адаптер станции с кадрами, у которых приоритет ниже, чем приоритет маркера, не может захватить маркер, но может поместить наибольший приоритет своих ожидающих передачи кадров в резервные биты маркера, но только в том случае, если записанный в резервных битах приоритет ниже его собственного. В результате в резервных битах приоритета устанавливается наивысший приоритет станции, которая пытается получить доступ к кольцу, но не может этого сделать из-за высокого приоритета маркера.
Станция, сумевшая захватить маркер, передает свои кадры с приоритетом маркера, а затем передает маркер следующему соседу. При этом она переписывает значение резервного приоритета в поле приоритета маркера, а резервный приоритет обнуляется. Поэтому при следующем проходе маркера по кольцу его захватит станция, имеющая наивысший приоритет.
При инициализации кольца основной и резервный приоритет маркера устанавливаются в 0.
Хотя механизм приоритетов в технологии Token Ring имеется, но он начинает работать только в том случае, когда приложение или прикладной протокол решают его использовать. Иначе все станции будут иметь равные права доступа к кольцу, что в основном и происходит на практике, так как большая часть приложений этим механизмом не пользуется. Это связано с тем, что приоритеты кадров поддерживаются не во всех технологиях, например в сетях Ethernet они отсутствуют, поэтому приложение будет вести себя по-разному, в зависимости от технологии нижнего уровня, что нежелательно. В современных сетях приоритетность обработки кадров обычно обеспечивается коммутаторами или маршрутизаторами, которые поддерживают их независимо от используемых протоколов канального уровня.
Проблема управления потоком данных при полнодуплексной работе
Простой отказ от поддержки алгоритма доступа к разделяемой среде без какой-либо модификации протокола ведет к повышению вероятности потерь кадров коммутаторами, так как при этом теряется контроль за потоками кадров, направляемых конечными узлами в сеть. Раньше поток кадров регулировался методом доступа к разделяемой среде, так что слишком часто генерирующий кадры узел вынужден был ждать своей очереди к среде и фактическая интенсивность потока данных, который направлял в сеть этот узел, была заметно меньше той интенсивности, которую узел хотел бы отправить в сеть. При переходе на полнодуплексный режим узлу разрешается отправлять кадры в коммутатор всегда, когда это ему нужно, поэтому коммутаторы сети могут в этом режиме сталкиваться с перегрузками, не имея при этом никаких средств регулирования («притормаживания») потока кадров.
Причина перегрузок обычно кроется не в том, что коммутатор является блокирующим, то есть ему не хватает производительности процессоров для обслуживания потоков кадров, а в ограниченной пропускной способности отдельного порта, которая определяется временными параметрами протокола. Например, порт Ethernet не может передавать больше 14 880 кадров в секунду, если он не нарушает временных соотношений, установленных стандартом.
Поэтому, если входной трафик неравномерно распределяется между выходными портами, легко представить ситуацию, когда в какой-либо выходной порт коммутатора будет направляться трафик с суммарной средней интенсивностью большей, чем протокольный максимум. На рис. 4.28 изображена как раз такая ситуация, когда в порт 3 коммутатора направляется трафик от портов 1,2,4 и 6, с суммарной интенсивностью в 22 100 кадров в секунду. Порт 3
оказывается загружен на 150 %, Естественно, что когда кадры поступают в буфер порта со скоростью 20 100 кадров в секунду, а уходят со скоростью 14 880 кадров в секунду, то внутренний буфер выходного порта начинает неуклонно заполняться необработанными кадрами.
Рис. 4.28. Переполнение буфера порта из-за несбалансированности трафика
Какой бы ни был объем буфера порта, он в какой-то момент времени обязательно переполнится. Нетрудно подсчитать, что при размере буфера в 100 Кбайт в приведенном примере полное заполнение буфера произойдет через 0,22 секунды после начала его работы (буфер такого размера может хранить до 1600 кадров размером в 64 байт). Увеличение буфера до 1 Мбайт даст увеличение времени заполнения буфера до 2,2 секунд, что также неприемлемо. А потери кадров всегда очень нежелательны, так как снижают полезную производительность сети, и коммутатор, теряющий кадры, может значительно ухудшить производительность сети вместо ее улучшения.
Коммутаторы локальных сетей - не первые устройства, которые сталкиваются с такой проблемой. Мосты также могут испытывать перегрузки, однако такие ситуации при использовании мостов встречались редко из-за небольшой интенсивности межсегментного трафика, поэтому разработчики мостов не стали встраивать в протоколы локальных сетей или в сами мосты механизмы регулирования потока. В глобальных сетях коммутаторы технологии Х.25 поддерживают протокол канального уровня LAP-В, который имеет специальные кадры управления потоком «Приемник готов» (RR) и «Приемник не готов» (RNR), аналогичные по назначению кадрам протокола LLC2 (это не удивительно, так как оба протокола принадлежат семейству протоколов HDLC. Протокол LAP-B работает между соседними коммутаторами сети Х.25 и в том случае, когда очередь коммутатора доходит до опасной границы, запрещает своим ближайшим соседям с помощью кадра «Приемник не готов» передавать ему кадры, пока очередь не уменьшится до нормального уровня. В сетях Х.25 такой протокол необходим, так как эти сети никогда не использовали разделяемые среды передачи данных, а работали по индивидуальным каналам связи в полнодуплексном режиме.
При разработке коммутаторов локальных сетей ситуация коренным образом отличалась от ситуации, при которой создавались коммутаторы территориальных сетей. Основной задачей было сохранение конечных узлов в неизменном виде, что исключало корректировку протоколов локальных сетей.
А в этих протоколах процедур управления потоком не было - общая среда передачи данных в режиме разделения времени исключала возникновение ситуаций, когда сеть переполнялась бы необработанными кадрами. Сеть не накапливала данных в каких-либо промежуточных буферах при использовании только повторителей или концентраторов.
ПРИМЕЧАНИЕ Здесь речь идет о протоколах МАС - уровня (Ethernet, Token Ring и т. п.), так как мосты и коммутаторы имеют дело только с ними. Протокол LLC2, который умеет управлять потоком данных, для целей управления потоком кадров в коммутаторах использовать нельзя. Для коммутаторов протокол LLC (все его процедуры: 1,2 и 3) прозрачен, как и все остальные протоколы верхних уровней, - коммутатор не анализирует заголовок LLC, считая его просто полем данных кадра МАС - уровня.
Применение коммутаторов без изменения протокола работы оборудования всегда порождает опасность потери кадров. Если порты коммутатора работают в обычном, то есть в полудуплексном режиме, то у коммутатора имеется возможность оказать некоторое воздействие на конечный узел и заставить его приостановить передачу кадров, пока у коммутатора не разгрузятся внутренние буферы. Нестандартные методы управления потоком в коммутаторах при сохранении протокола доступа в неизменном виде будут рассмотрены ниже.
Если же коммутатор работает в полнодуплексном режиме, то протокол работы конечных узлов, да и его портов все равно меняется. Поэтому имело смысл для поддержки полнодуплексного режима работы коммутаторов несколько модифицировать протокол взаимодействия узлов, встроив в него явный механизм управления потоком кадров.
Работа над выработкой стандарта для управления потоком кадров в полнодуплексных версиях Ethernet и Fast Ethernet продолжалась несколько лет. Такой длительный период объясняется разногласиями членов соответствующих комитетов по стандартизации, отстаивающих подходы фирм, которые реализовали в своих коммутаторах собственные методы управления потоком.
В марте 1997 года принят стандарт IEEE 802.3x на управление потоком в полнодуплексных версиях протокола Ethernet.
Он определяет весьма простую процедуру управления потоком, подобную той, которая используется в протоколах LLC2 и LAP-B. Эта процедура подразумевает две команды - «Приостановить передачу» и «Возобновить передачу», которые направляются соседнему узлу. Отличие от протоколов типа LLC2 в том, что эти команды реализуются на уровне символов кодов физического уровня, таких как 4В/5В, а не на уровне команд, оформленных в специальные управляющие кадры. Сетевой адаптер или порт коммутатора, поддерживающий стандарт 802.3x и получивший команду «Приостановить передачу», должен прекратить передавать кадры впредь до получения команды «Возобновить передачу».
Некоторые специалисты высказывают опасение, что такая простая процедура управления потоком окажется непригодной в сетях Gigabit Ethernet. Полная приостановка приема кадров от соседа при такой большой скорости передачи кадров (1 488 090 кадр/с) может быстро вызвать переполнение внутреннего буфера теперь у этого соседа, который в свою очередь полностью заблокирует прием кадров у своих ближайших соседей. Таким образом, перегрузка просто распространится по сети, вместо того чтобы постепенно исчезнуть. Для работы с такими скоростными протоколами необходим более тонкий механизм регулирования потока, который бы указывал, на какую величину нужно уменьшить интенсивность потока входящих кадров в перегруженный коммутатор, а не приостанавливал этот поток до нуля. Подобный плавный механизм регулирования потока появился у коммутаторов АТМ через несколько лет после их появления. Поэтому существует мнение, что стандарт 802.3х - это временное решение, которое просто закрепило существующие фирменные простые механизмы управления потоком ведущих производителей коммутаторов. Пройдет некоторое время, и этот стандарт сменит другой стандарт - более сложный и более приспособленный для высокоскоростных технологий, таких как Gigabit Ethernet.
Проблемы физической передачи данных по линиям связи
Даже при рассмотрении простейшей сети, состоящей всего из двух машин, можно увидеть многие проблемы, присущие любой вычислительной сети, в том числе проблемы, связанные с физической передачей сигналов по линиям связи, без решения которой невозможен любой вид связи.
В вычислительной технике для представления данных используется двоичный код. Внутри компьютера единицам и нулям данных соответствуют дискретные электрические сигналы. Представление данных в виде электрических или оптических сигналов называется кодированием. Существуют различные способы кодирования двоичных цифр 1 и 0, например, потенциальный способ, при котором единице соответствует один уровень напряжения, а нулю - другой, или импульсный способ, когда для представления цифр используются импульсы различной или одной полярности.
Аналогичные подходы могут быть использованы для кодирования данных и при передаче их между двумя компьютерами по линиям связи. Однако эти линии связи отличаются по своим электрическим характеристикам от тех, которые существуют внутри компьютера. Главное отличие внешних линий связи от внутренних состоит в их гораздо большей протяженности, а также в том, что они проходят вне экранированного корпуса по пространствам, зачастую подверженным воздействию сильных электромагнитных помех. Все это приводит к значительно большим искажениям прямоугольных импульсов (например, «заваливанию» фронтов), чем внутри компьютера. Поэтому для надежного распознавания импульсов на приемном конце линии связи при передаче данных внутри и вне компьютера не всегда можно использовать одни и те же скорости и способы кодирования. Например, медленное нарастание фронта импульса из-за высокой емкостной нагрузки линии требует передачи импульсов с меньшей скоростью (чтобы передний и задний фронты соседних импульсов не перекрывались и импульс успел дорасти до требуемого уровня).
В вычислительных сетях применяют как потенциальное, так и импульсное кодирование дискретных данных, а также специфический способ представления данных, который никогда не используется внутри компьютера, - модуляцию
(рис. 1.9). При модуляции дискретная информация представляется синусоидальным сигналом той частоты, которую хорошо передает имеющаяся линия связи.

Рис. 1.9. Примеры представления дискретной информации
Потенциальное или импульсное кодирование применяется на каналах высокого качества, а модуляция на основе синусоидальных сигналов предпочтительнее в том случае, когда канал вносит сильные искажения в передаваемые сигналы. Обычно модуляция используется в глобальных сетях при передаче данных через аналоговые телефонные каналы связи, которые были разработаны для передачи голоса в аналоговой форме и поэтому плохо подходят для непосредственной передачи импульсов.
На способ передачи сигналов влияет и количество проводов в линиях связи между компьютерами. Для сокращения стоимости линий связи в сетях обычно стремятся к сокращению количества проводов и из-за этого используют не параллельную передачу всех бит одного байта или даже нескольких байт, как это делается внутри компьютера, а последовательную, побитную передачу, требующую всего одной пары проводов.
Еще одной проблемой, которую нужно решать при передаче сигналов, является проблема взаимной синхронизации
передатчика одного компьютера с приемником другого. При организации взаимодействия модулей внутри компьютера эта проблема решается очень просто, так как в этом случае все модули синхронизируются от общего тактового генератора. Проблема синхронизации при связи компьютеров может решаться разными способами, как с помощью обмена специальными тактовыми синхроимпульсами по отдельной линии, так и с помощью периодической синхронизации заранее обусловленными кодами или импульсами характерной формы, отличающейся от формы импульсов данных.
Несмотря на предпринимаемые меры - выбор соответствующей скорости обмена данными, линий связи с определенными характеристиками, способа синхронизации приемника и передатчика, - существует вероятность искажения некоторых бит передаваемых данных. Для повышения надежности передачи данных между компьютерами часто используется стандартный прием - подсчет контрольной суммы и передача ее по линиям связи после каждого байта или после некоторого блока байтов.
Часто в протокол обмена данными включается как обязательный элемент сигнал-квитанция, который подтверждает правильность приема данных и посылается от получателя отправителю.
Задачи надежного обмена двоичными сигналами, представленными соответствующими электромагнитными сигналами, в вычислительных сетях решает определенный класс оборудования. В локальных сетях это сетевые адаптеры, а в глобальных сетях - аппаратура передачи данных, к которой относятся, например, устройства, выполняющие модуляцию и демодуляцию дискретных сигналов, - модемы. Это оборудование кодирует и декодирует каждый информационный бит, синхронизирует передачу электромагнитных сигналов по линиям связи, проверяет правильность передачи по контрольной сумме и может выполнять некоторые другие операции. Сетевые адаптеры рассчитаны, как правило, на работу с определенной передающей средой - коаксиальным кабелем, витой парой, оптоволокном и т. п. Каждый тип передающей среды обладает определенными электрическими характеристиками, влияющими на способ использования данной среды, и определяет скорость передачи сигналов, способ их кодирования и некоторые другие параметры.
Проблемы объединения нескольких компьютеров
До сих пор мы рассматривали вырожденную сеть, состоящую всего из двух машин. При объединении в сеть большего числа компьютеров возникает целый комплекс новых проблем.
Производительность
Потенциально высокая производительность - это одно из основных свойств распределенных систем, к которым относятся компьютерные сети. Это свойство обеспечивается возможностью распараллеливания работ между несколькими компьютерами сети. К сожалению, эту возможность не всегда удается реализовать. Существует несколько основных характеристик производительности сети:
время реакции;
пропускная способность;
задержка передачи и вариация задержки передачи.
Время реакции сети является интегральной характеристикой производительности сети с точки зрения пользователя. Именно эту характеристику имеет в виду пользователь, когда говорит: «Сегодня сеть работает медленно».
В общем случае время реакции определяется как интервал времени между возникновением запроса пользователя к какой-либо сетевой службе и получением ответа на этот запрос.
Очевидно, что значение этого показателя зависит от типа службы, к которой обращается пользователь, от того, какой пользователь и к какому серверу обращается, а также от текущего состояния элементов сети - загруженности сегментов, коммутаторов и маршрутизаторов, через которые проходит запрос, загруженности сервера и т. п.
Поэтому имеет смысл использовать также и средневзвешенную оценку времени реакции сети, усредняя этот показатель по пользователям, серверам и времени дня (от которого в значительной степени зависит загрузка сети).
Время реакции сети обычно складывается из нескольких составляющих. В общем случае в него входит время подготовки запросов на клиентском компьютере, время передачи запросов между клиентом и сервером через сегменты сети и промежуточное коммуникационное оборудование, время обработки запросов на сервере, время передачи ответов от сервера клиенту и время обработки получаемых от сервера ответов на клиентском компьютере.
Ясно, что пользователя разложение времени реакции на составляющие не интересует - ему важен конечный результат, однако для сетевого специалиста очень важно выделить из общего времени реакции составляющие, соответствующие этапам собственно сетевой обработки данных, - передачу данных от клиента к серверу через сегменты сети и коммуникационное оборудование.
Знание сетевых составляющих времени реакции дает возможность оценить производительность отдельных элементов сети, выявить узкие места и в случае необходимости выполнить модернизацию сети для повышения ее общей производительности.
Пропускная способность отражает объем данных, переданных сетью или ее частью в единицу времени. Пропускная способность уже не является пользовательской характеристикой, так как она говорит о скорости выполнения внутренних операций сети - передачи пакетов данных между узлами сети через различные коммуникационные устройства. Зато она непосредственно характеризует качество выполнения основной функции сети - транспортировки сообщений - и поэтому чаще используется при анализе производительности сети, чем время реакции. Пропускная способность измеряется либо в битах в секунду, либо в пакетах в секунду. Пропускная способность может быть мгновенной, максимальной и средней.
Средняя пропускная способность
вычисляется путем деления общего объема переданных данных на время их передачи, причем выбирается достаточно длительный промежуток времени - час, день или неделя.
Мгновенная пропускная способность
отличается от средней тем, что для усреднения выбирается очень маленький промежуток времени - например, 10 мс или 1 с.
Максимальная пропускная способность - это наибольшая мгновенная пропускная способность, зафиксированная в течение периода наблюдения.
Чаще всего при проектировании, настройке и оптимизации сети используются такие показатели, как средняя и максимальная пропускные способности. Средняя пропускная способность отдельного элемента или всей сети позволяет оценить работу сети на большом промежутке времени, в течение которого в силу закона больших чисел пики и спады интенсивности трафика компенсируют друг друга. Максимальная пропускная способность позволяет оценить возможности сети справляться с пиковыми нагрузками, характерными для особых периодов работы сети, например утренних часов, когда сотрудники предприятия почти одновременно регистрируются в сети и обращаются к разделяемым файлам и базам данных.
Пропускную способность можно измерять между любыми двумя узлами или точками сети, например между клиентским компьютером и сервером, между входным и выходным портами маршрутизатора. Для анализа и настройки сети очень полезно знать данные о пропускной способности отдельных элементов сети.
Важно отметить, что из-за последовательного характера передачи пакетов различными элементами сети общая пропускная способность сети любого составного пути в сети будет равна минимальной
из пропускных способностей составляющих элементов маршрута. Для повышения пропускной способности составного пути необходимо в первую очередь обратить внимание на самые медленные элементы - в данном случае таким элементом, скорее всего, будет маршрутизатор. Следует подчеркнуть, что если передаваемый по составному пути трафик будет иметь среднюю интенсивность, превосходящую среднюю пропускную способность самого медленного элемента пути, то очередь пакетов к этому элементу будет расти теоретически до бесконечности, а практически - до тех пор, пока не заполниться его буферная память, а затем пакеты просто начнут отбрасываться и теряться.
Иногда полезно оперировать с общей пропускной способностью сети, которая определяется как среднее количество информации, переданной между всеми узлами сети в единицу времени. Этот показатель характеризует качество сети в целом, не дифференцируя его по отдельным сегментам или устройствам.
Обычно при определении пропускной способности сегмента или устройства в передаваемых данных не выделяются пакеты какого-то определенного пользователя, приложения или компьютера - подсчитывается общий объем передаваемой информации. Тем не менее для более точной оценки качества обслуживания такая детализации желательна, и в последнее время системы управления сетями все чаще позволяют ее выполнять.
Задержка передачи определяется как задержка между моментом поступления пакета на вход какого-либо сетевого устройства или части сети и моментом появления его на выходе этого устройства. Этот параметр производительности по смыслу близок ко времени реакции сети, но отличается тем, что всегда характеризует только сетевые этапы обработки данных, без задержек обработки компьютерами сети.
Обычно качество сети характеризуют величинами максимальной задержки передачи и вариацией задержки. Не все типы трафика чувствительны к задержкам передачи, во всяком случае, к тем величинам задержек, которые характерны для компьютерных сетей, - обычно задержки не превышают сотен миллисекунд, реже - нескольких секунд. Такого порядка задержки пакетов, порождаемых файловой службой, службой электронной почты или службой печати, мало влияют на качество этих служб с точки зрения пользователя сети. С другой стороны, такие же задержки пакетов, переносящих голосовые данные или видеоизображение, могут приводить к значительному снижению качества предоставляемой пользователю информации - возникновению эффекта «эха», невозможности разобрать некоторые слова, дрожание изображения и т. п.
Пропускная способность и задержки передачи являются независимыми параметрами, так что сеть может обладать, например, высокой пропускной способностью, но вносить значительные задержки при передаче каждого пакета. Пример такой ситуации дает канал связи, образованный геостационарным спутником. Пропускная способность этого канала может быть весьма высокой, например 2 Мбит/с, в то время как задержка передачи всегда составляет не менее 0,24 с, что определяется скоростью распространения сигнала (около 300 000 км/с) и длиной канала (72 000 км).
Пропускная способность линии
Пропускная способность (throughput) линии характеризует максимально возможную скорость передачи данных по линии связи. Пропускная способность измеряется в битах в секунду - бит/с, а также в производных единицах, таких как килобит в секунду (Кбит/с), мегабит в секунду (Мбит/с), гигабит в секунду (Гбит/с) и т. д.
ПРИМЕЧАНИЕ Пропускная способность линий связи и коммуникационного сетевого оборудования традиционно измеряется в битах в секунду, а не в байтах в секунду. Это связано с тем, что данные в сетях передаются последовательно, то есть побитно, а не параллельно, байтами, как это происходит между устройствами внутри компьютера. Такие единицы измерения, как килобит, мегабит или гигабит, в сетевых технологиях строго соответствуют степеням ) 0 (то есть килобит - это 1000 бит, а мегабит - это 1 000 000 бит), как это принято во всех отраслях науки и техники, а не близким к этим числам степеням 2, как это принято в программировании, где приставка «кило» равна 210 =1024, а «мега» - 220 = 1 048576.
Пропускная способность линии связи зависит не только от ее характеристик, таких как амплитудно-частотная характеристика, но и от спектра передаваемых сигналов. Если значимые гармоники сигнала (то есть те гармоники, амплитуды которых вносят основной вклад в результирующий сигнал) попадают в полосу пропускания линии, то такой сигнал будет хорошо передаваться данной линией связи и приемник сможет правильно распознать информацию, отправленную по линии передатчиком (рис. 2.9, а). Если же значимые гармоники выходят за границы полосы пропускания линии связи, то сигнал будет значительно искажаться, приемник будет ошибаться при распознавании информации, а значит, информация не сможет передаваться с заданной пропускной способностью (рис. 2.9, б).

Рис. 2.9. Соответствие между полосой пропускания линии связи и спектром сигнала
Выбор способа представления дискретной информации в виде сигналов, подаваемых на линию связи, называется физическим или линейным кодированием. От выбранного способа кодирования зависит спектр сигналов и, соответственно, пропускная способность линии.
Таким образом, для одного способа кодирования линия может обладать одной пропускной способностью, а для другого - другой. Например, витая пара категории 3 может передавать данные с пропускной способностью 10 Мбит/с при способе кодирования стандарта физического уровня l0Base-T и 33 Мбит/с при способе кодирования стандарта 100Base-T4. В примере, приведенном на рис. 2.9, принят следующий способ кодирования - логическая 1 представлена на линии положительным потенциалом, а логический 0 - отрицательным.
Теория информации говорит, что любое различимое и непредсказуемое изменение принимаемого сигнала несет в себе информацию. В соответствии с этим прием синусоиды, у которой амплитуда, фаза и частота остаются неизменными, информации не несет, так как изменение сигнала хотя и происходит, но является хорошо предсказуемым. Аналогично, не несут в себе информации импульсы на тактовой шине компьютера, так как их изменения также постоянны во времени. А вот импульсы на шине данных предсказать заранее нельзя, поэтому они переносят информацию между отдельными блоками или устройствами.
Большинство способов кодирования используют изменение какого-либо параметра периодического сигнала - частоты, амплитуды и фазы синусоиды или же знак потенциала последовательности импульсов. Периодический сигнал, параметры которого изменяются, называют несущим сигналом или несущей частотой, если в качестве такого сигнала используется синусоида.
Если сигнал изменяется так, что можно различить только два его состояния, то любое его изменение будет соответствовать наименьшей единице информации - биту. Если же сигнал может иметь более двух различимых состояний, то любое его изменение будет нести несколько бит информации.
Количество изменений информационного параметра несущего периодического сигнала в секунду измеряется в бодах (baud). Период времени между соседними изменениями информационного сигнала называется тактом работы передатчика.
Пропускная способность линии в битах в секунду в общем случае не совпадает с числом бод.
Она может быть как выше, так и ниже числа бод, и это соотношение зависит от способа кодирования.
Если сигнал имеет более двух различимых состояний, то пропускная способность в битах в секунду будет выше, чем число бод. Например, если информационными параметрами являются фаза и амплитуда синусоиды, причем различаются 4 состояния фазы в 0,90,180 и 270 градусов и два значения амплитуды сигнала, то информационный сигнал может иметь 8 различимых состояний. В этом случае модем, работающий со скоростью 2400 бод (с тактовой частотой 2400 Гц) передает информацию со скоростью 7200 бит/с, так как при одном изменении сигнала передается 3 бита информации.
При использовании сигналов с двумя различимыми состояниями может наблюдаться обратная картина. Это часто происходит потому, что для надежного распознавания приемником пользовательской информации каждый бит в последовательности кодируется с помощью нескольких изменений информационного параметра несущего сигнала. Например, при кодировании единичного значения бита импульсом положительной полярности, а нулевого значения бита - импульсом отрицательной полярности физический сигнал дважды изменяет свое состояние при передаче каждого бита. При таком кодировании пропускная способность линии в два раза ниже, чем число бод, передаваемое по линии.
На пропускную способность линии оказывает влияние не только физическое, но и логическое кодирование. Логическое кодирование выполняется до физического кодирования и подразумевает замену бит исходной информации новой последовательностью бит, несущей ту же информацию, но обладающей, кроме этого, дополнительными свойствами, например возможностью для приемной стороны обнаруживать ошибки в принятых данных. Сопровождение каждого байта исходной информации одним битом четности - это пример очень часто применяемого способа логического кодирования при передаче данных с помощью модемов. Другим примером логического кодирования может служить шифрация данных, обеспечивающая их конфиденциальность при передаче через общественные каналы связи.При логическом кодировании чаще всего исходная последовательность бит заменяется более длинной последовательностью, поэтому пропускная способность канала по отношению к полезной информации при этом уменьшается.
Пропускная способность сетей с коммутацией пакетов
Одним из отличий метода коммутации пакетов от метода коммутации каналов является неопределенность пропускной способности соединения между двумя абонентами. В методе коммутации каналов после образования составного канала пропускная способность сети при передаче данных между конечными узлами известна - это пропускная способность канала. Данные после задержки, связанной с установлением канала, начинают передаваться на максимальной для канала скорости (рис. 2.31, а). Время передачи сообщения в сети с коммутацией каналов Тц.к. равно сумме задержки распространения сигнала по линии связи ta.p. и задержки передачи сообщения 1з.п.. Задержка распространения сигнала зависит от скорости распространения электромагнитных волн в конкретной физической среде, которая колеблется от 0,6 до 0,9 скорости света в вакууме. Время передачи сообщения равно V/C, где V - объем сообщения в битах, а С - пропускная способность канала в битах в секунду.

Рис. 2.31. Задержки передачи данных в сетях с коммутацией каналов и пакетов
В сети с коммутацией пакетов наблюдается принципиально другая картина.
Процедура установления соединения в этих сетях, если она используется, занимает примерно такое же время, как и в сетях с коммутацией каналов, поэтому будем сравнивать только время передачи данных.
На рис. 2.31, б показан пример передачи в сети с коммутацией пакетов. Предполагается, что в сеть передается сообщение того же объема, что и сообщение, иллюстрируемое рис. 2.31, а, однако оно разделено на пакеты, каждый из которых снабжен заголовком. Время передачи сообщения в сети с коммутацией пакетов обозначено на рисунке Тк.п.. При передаче этого сообщения, разбитого на пакеты, по сети с коммутацией пакетов возникают дополнительные временные задержки. Во-первых, это задержки в источнике передачи, который, помимо передачи собственно сообщения, тратит дополнительное время на передачу заголовков tп.з., плюс к этому добавляются задержки tинт, вызванные интервалами между передачей каждого следующего пакета (это время уходит на формирование очередного пакета стеком протоколов).
Во-вторых, дополнительное время тратится в каждом коммутаторе. Здесь задержки складываются из времени буферизации пакета tб.п. (коммутатор не может начать передачу пакета, не приняв его полностью в свой буфер) и времени коммутации tк. Время буферизации равно времени приема пакета с битовой скоростью протокола. Время коммутации складывается из времени ожидания пакета в очереди и времени перемещения пакета в выходной порт. Если время перемещения пакета фиксировано и обычно невелико (от нескольких микросекунд до нескольких десятков микросекунд), то время ожидания пакета в очереди колеблется в очень широких пределах и заранее неизвестно, так как зависит от текущей загрузки сети пакетами.
Проведем грубую оценку задержки в передаче данных в сетях с коммутацией пакетов по сравнению с сетями с коммутацией каналов на простейшем примере. Пусть тестовое сообщение, которое нужно передать в обоих видах сетей, составляет 200 Кбайт. Отправитель находится от получателя на расстоянии 5000 км. Пропускная способность линий связи составляет 2 Мбит/с.
Время передачи данных по сети с коммутацией каналов складывается из времени распространения сигнала, которое для расстояния 5000 км можно оценить примерно в 25 мс, и времени передачи сообщения, которое при пропускной способности 2 Мбит/с и длине сообщения 200 Кбайт равно примерно 800 мс, то есть всего передача данных заняла 825 мс.
Оценим дополнительное время, которое потребуется для передачи этого сообщения по сети с коммутацией пакетов. Будем считать, что путь от отправителя до получателя пролегает через 10 коммутаторов. Исходное сообщение разбивается на пакеты в 1 Кбайт, всего 200 пакетов. Вначале оценим задержку, которая возникает в исходном узле. Предположим, что доля служебной информации, размещенной в заголовках пакетов, по отношению к общему объему сообщения составляет 10 %. Следовательно, дополнительная задержка, связанная с передачей заголовков пакетов, составляет 10 % от времени передачи целого сообщения, то есть 80 мс. Если принять интервал между отправкой пакетов равным 1 мс, тогда дополнительные потери за счет интервалов составят 200 мс.
Итого, в исходном узле из- за пакетирования сообщения при передаче возникла дополнительная задержка в 280 мс.
Каждый из 10 коммутаторов вносит задержку коммутации, которая может иметь большой разброс, от долей до тысяч миллисекунд. В данном примере примем, что на коммутацию в среднем тратится 20 мс. Кроме того, при прохождении сообщений через коммутатор возникает задержка буферизации пакета. Эта задержка при величине пакета 1 Кбайт и пропускной способности линии 2 Мбит/с равна 4 мс. Общая задержка, вносимая 10 коммутаторами, составит примерно 240 мс. В результате дополнительная задержка, созданная сетью с коммутацией пакетов, составила 520 мс. Учитывая, что вся передача данных в сети с коммутацией каналов заняла 825 мс, эту дополнительную задержку можно считать существенной.
Хотя приведенный расчет носит очень приблизительный характер, но он делает более понятными те причины, которые приводят к тому, что процесс передачи для определенной пары абонентов в сети с коммутацией пакетов является более медленным, чем в сети с коммутацией каналов.
Неопределенная пропускная способность сети с коммутацией пакетов - это плата за ее общую эффективность при некотором ущемлении интересов отдельных абонентов. Аналогично, в мультипрограммной операционной системе время выполнения приложения предсказать заранее невозможно, так как оно зависит от количества других приложений, с которыми делит процессор данное приложение.
На эффективность работы сети существенно влияют размеры пакетов, которые передает сеть. Слишком большие размеры пакетов приближают сеть с коммутацией пакетов к сети с коммутацией каналов, поэтому эффективность сети при этом падает. Слишком маленькие пакеты заметно увеличивают долю служебной информации, так как каждый пакет несет с собой заголовок фиксированной длины, а количество пакетов, на которые разбиваются сообщения, будет резко расти при уменьшении размера пакета. Существует некоторая золотая середина, которая обеспечивает максимальную эффективность работы сети, однако ее трудно определить точно, так как она зависит от многих факторов, некоторые из них к тому же постоянно меняются в процессе работы сети.Поэтому разработчики протоколов для сетей с коммутацией пакетов выбирают пределы, в которых может находиться длина пакета, а точнее его поле данных, так как заголовок, как правило, имеет фиксированную длину. Обычно нижний предел поля данных выбирается равным нулю, что разрешает передавать служебные пакеты без пользовательских данных, а верхний предел не превышает 4-х килобайт. Приложения при передаче данных пытаются занять максимальный размер поля данных, чтобы быстрее выполнить обмен данными, а небольшие пакеты обычно используются для квитанций о доставке пакета.
При выборе размера пакета необходимо учитывать также и интенсивность битовых ошибок канала. На ненадежных каналах необходимо уменьшать размеры пакетов, так как это уменьшает объем повторно передаваемых данных при искажениях пакетов.
