Автоматизация процессизвлечения знаний в системе OPAL
Проект COMPASS можно считать одним из наиболее ярких примеров использования традиционной методики приобретения знаний, базирующейся на соответствующим образом организованном опросе экспертов. Такая методология "выросла" из предложенной Ньюэллом и Саймоном методики анализа протокола (protocol analysis), которую мы рассматривали в главе 2. В этом разделе мы остановимся на проекте OPAL, в котором использована другая методика, отличающаяся от традиционной в двух важных аспектах.
Эта методика ориентирована на частичную автоматизацию процесса извлечения знаний в ходе активного диалога интервьюируемого эксперта с программой.
Методика приобретения знаний предполагает использование стратегии, направляемой знаниями о предметной области.
Мы уже рассматривали программу TEIRESIAS, в которой использовалось множество средств поиска ошибок в существующем наборе правил, редактирования и тестирования откорректированного набора правил. Но для построения начального набора правил или отслеживания изменений в них программа TEIRESIAS не использовала какие-либо знания о предметной области. Программа OPAL, напротив, пытается "вытянуть" из пользователя как можно больше деталей, касающихся представления знаний и их использования. OPAL не является программой общего назначения. Она разработана специально для диагностики онкологических заболеваний и предназначена для формирования правил принятия решений на основе полученных от эксперта знаний о планах лечения в том или ином случае.
Графический интерфейс модели предметной области
Программа OPAL упрощает процесс извлечения знаний, предназначенных для использования в экспертной системе ONCOCIN [Shortliffe et at, 1981]. Последняя формирует план лечения больных онкозаболеваниями и заинтересована в использовании модели предметной области для получения знаний непосредственно от эксперта с помощью средств графического интерфейса. Понятие модель предметной области можно трактовать в терминах знаний различного вида, которыми обладает эксперт.
Независимо от того, о какой конкретной предметной области идет речь, игре в шахматы или медицинской диагностике, всегда существуют некоторые предварительные условия или предварительный опыт, которыми должен обладать субъект или техническая система, чтобы воспринимать знания об этой предметной области. Если речь идет об игре в шахматы, то по крайней мере нужно знать правила этой игры: как ходят фигуры, в чем цель игры и т.п. Применительно к медицинской диагностике нужно иметь представление о пациентах, заболеваниях, клинических тестах и т.п. Этот вид фоновых, или фундаментальных, знаний иногда в литературе по экспертным системам называют глубокими знаниями {deep knowledge), противопоставляя их поверхностным знаниям (shallow knowledge), которые представляют собой хаотичный набор сведений о связях "стимул — реакция".
Так, программа игры в шахматы, которая просто выбирает дозволенные ходы, не обладает глубокими знаниями об этой игре, в отличие от программы, которая учитывает "ценность" фигур и "качество" позиции на доске. Аналогично и программа диагностики, которая не делает ничего иного, кроме того, что пытается спроектировать имеющийся набор симптомов на список заболеваний, является поверхностной по сравнению с программой, которая пытается найти согласованное объяснение всем представленным симптомам в терминах небольшого числа совместно проявляющихся патологий. Человек, который разбирается в основных принципах игры в шахматы или клинического диагноза, может затем на основе этих знаний повышать свое мастерство, а без таких фундаментальных знаний дальнейшее совершенствование практически невозможно.
OPAL представляет собой программу извлечения знаний, которая обладает некоторыми фундаментальными знаниями в области терапии онкологических заболеваний. Программа использует эти базовые знания в процессе диалога с экспертом для извлечения дополнительных, более детальных знаний. Знания о предметной области нужны программе и для того, чтобы преобразовать информацию, полученную с терминала в процессе диалога, в исполняемый код — порождающие правила или таблицу состояний. Такая комбинация процесса наращивания знаний и их компиляции является одной из наиболее привлекательных возможностей той методологии построения экспертных систем, которая положена в основу системы OPAL. Графически основная идея представлена на рис. 10.3, где на человека-эксперта возлагается задача расширения и уточнения модели предметной области. Эта модель затем компилируется в программу, состоящую из процедур и порождающих правил. Поведение программы снова анализируется экспертом, который при необходимости вносит коррективы в модель и замыкает таким образом цикл итеративного процесса.
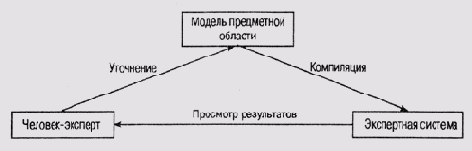
Рис. 10.3. Процесс приобретения знаний с использованием модели предметной области
Чтобы лучше понять, как работает программа OPAL, нужно сказать несколько слов о той предметной области, в которой она используется. Курсы лечения онкологических заболеваний называются протоколами, и в них специфицируются медикаменты, которые назначаются пациенту на определенный период времени, необходимые лабораторные анализы и иногда курсы радиационной терапии. Система ONCOCIN формирует рекомендации относительно курса лечения, используя базу знаний протоколов, которые представляют собой шаблоны планов лечения. Программа сначала выбирает подходящий протокол, а затем конкретизирует его — назначает конкретные медикаменты, сроки и т.п. Такой метод решения подобных задач иногда называют уточнением плана.
В экспертной системе ONCOCIN используются три разных метода представления знаний:
иерархия объектов, представляющая протоколы и их компоненты, в частности медикаменты;
порождающие правила, которые связаны с фреймами и формируют заключения о значениях медицинских параметров в процессе уточнения плана;
таблицы конечных состояний представляют собой последовательности терапевтических курсов (назначение и использование этих таблиц будет описано ниже).
Включение в систему ONCOCIN нового протокола влечет за собой формирование иерархии, которая представляет его компоненты, связывание подходящих порождающих правил с новыми объектами и заполнение таблицы конечных состояний, которая определяет порядок назначения определенных компонентов курса лечения. Программа OPAL формирует элементы нового протокола в процессе "собеседования" с экспертом с помощью средств графического интерфейса. При этом полученные знания преобразуются сначала в промежуточную форму представления, а затем транслируются в формат, используемый в системе ONCOCIN. На последней стадии формируются соответствующие порождающие правила. Для упрощения реализации промежуточных стадий, трансляции и формирования порождающих правил в программе OPAL используется модель предметной области лечения онкологических заболеваний, о которой и пойдет речь ниже.
В модели предметной области можно выделить четыре основных аспекта, которые явились следствием применения онтологического анализа, как отмечалось в разделе 10.1.3.
Сущности и отношения. Сущностями в этой предметной области являются элементы (компоненты) курса лечения — назначаемые медикаменты. Эти сущности образуют часть статической онтологии предметной области. Большая часть знаний о предметной области касается атрибутов альтернативных медикаментов, например доз и их приема. Отношения между элементами курса лечения довольно запутаны в том смысле, что они связывают различные уровни спецификации в плане лечения. Так, медикаменты могут быть частью химиотерапии, а химиотерапия может быть частью протокола.
Действия в предметной области. При заданных отношениях между элементами для уточнения плана приема медикаментов потребуется обращение к перечню планов.
Другими словами, уточнение плана является неявным в иерархической организации сущностей предметной области. Таким образом, модель предметной области в OPAL позволяет сконцентрировать основное внимание на задачах, а не на используемых методах поиска. Однако может потребоваться изменить планы для отдельных пациентов, например изменить дозировку или заменить один препарат другим. Такие концепции, как изменение дозировки или замена препаратов в курсе лечения, образуют часть динамической онтологии предметной области.
Предикаты предметной области. Этот аспект модели касается условий, при которых обращаются к модификации назначенного плана лечения. Сюда могут входить результаты лабораторных анализов и проявления у пациента определенных симптомов (например, токсикоз на определенные препараты). Такие знания образуют часть эпи-стемической онтологии предметной области, т.е. эти знания направляют и ограничивают возможные действия. На уровне реализации правила, изменяющие курс лечения, основываются на этих условиях. Такие предикаты появляются в левой части порождающих правил ONCOCIN. Подобное правило подключается к объекту в иерархии планирования таким образом, что оно применяется только в контексте определенного препарата или определенного курса химиотерапии в конкретном протоколе.
Процедурные знания. Поскольку планы курса лечения предполагают определенное расписание приема назначенных пациенту препаратов, знания о способе реализации протокола составляют существенную часть модели предметной области. Эти знания позволяют программе OPAL извлекать информацию, которая потом направляется в таблицы конечных состояний, описывающие возможные последовательности этапов курса терапии, и таким образом образуют другую часть эпистемической онтологии предметной области. На уровне реализации программа OPAL использует для описания таких процедур специальный язык программирования, который позволяет эксперту представлять достаточно сложные алгоритмы, манипулируя пиктограммами на экране дисплея.
Используя эту модель, программа OPAL может извлекать и отображать в разной форме знания о планах лечения — в виде пиктограмм, представляющих отдельные элементы плана, формуляра, заполненного информацией об отдельных препаратах, в виде предложений специального языка, представляющих процедуры, связанные с реализацией плана лечения.
Сущности и отношения между ними вводятся с помощью экранных формуляров, в которых пользователь выбирает элементы из меню. Затем заполненный формуляр преобразуется в фрейм, причем отдельные поля формуляра образуют слоты фрейма, а введенные в них значения — значения слотов (заполнители слотов). Эти новые объекты затем автоматически связываются с другими объектами в иерархии. Например, медикаменты связываются с объектами курсов химиотерапии, компонентами которых они являются.
Операции предметной области также вводятся с помощью заполнения экранных формуляров. В этом случае формуляр представляет собой пустой шаблон плана, в котором представлены поля для назначения расписания приема препаратов, а меню возможных действий включает такие операции, как изменение дозировки, временное прекращение приема и т.д. Поскольку список возможных действий довольно короткий, эта методика позволяет эксперту достаточно легко ввести нужную последовательность операций. В отличие от программы TEIRESIAS, OPAL позволяет пользователю не вдаваться в подробности реализации. Например, не нужно думать о том, на какие медицинские параметры ссылается та или иная операция в процессе реализации ее системой ONCOCIN. Вся информация, касающаяся медицинских параметров, такая как число белых кровяных телец, уже связана с формулярами. Количество предикатов предметной области, так же, как и количество возможных действий, ограничено. Поэтому при вводе экспертом информации о том, как изменять протокол в процессе выполнения курса лечения, программа OPAL тоже использует метод выбора из заранее сформированных списков видов лабораторных анализов. Процесс перевода введенной информации в выражения, которые могут обрабатываться системой ONCOCIN, скрыт от пользователя.
Процесс приобретения знаний в значительной мере облегчается при использовании языков визуального программирования. Графический интерфейс позволяет пользователю создавать пиктограммы, представляющие элементы плана, и формировать из них графические структуры. Расставляя такие элементы на экране и вычерчивая связи между ними, пользователь формирует мнемоническую схему управления потоками, которая обычно представляется в виде программы на каком-нибудь языке программирования.
На последующих этапах такие программы преобразуются в таблицы конечных состояний, хорошо известные специалистам в области теории вычислительных машин. Для любого текущего состояния системы такая таблица позволяет определить, в какое новое состояние перейдет система, получив определенный набор входных сигналов, и какой набор выходных сигналов при этом будет сформирован. В контексте той системы, которую мы рассматриваем, состояния — это планы лечения, а входные и выходные сигналы — это медицинские данные.
Использование опросэкспертов для извлечения знаний в системе COMPASS
Для переключения номеров в телефонной сети используется довольно сложная система, которая может занимать большую часть здания телефонной станции. Основная задача при обслуживании системы переключений — минимизировать число вызовов, которые необходимо перебросить на запасные маршруты из-за неисправности основных линий подключений, и быстро восстановить работу всей системы. Неисправность линий подключения может быть вызвана отказом каких-либо электронных схем, обеспечивающих связь между парой абонентов.
В процессе работы в системе переключения непрерывно выполняется самотестирование. При этом проверяется, нет ли разрыва в цепях, короткого замыкания, замедления срабатывания переключающих схем и т.д. При возникновении каких-либо нестандартных ситуаций система самотестирования формирует соответствующее сообщение. Причина появления неисправности в системе переключения может быть выявлена только на основании множества таких сообщений, причем на помощь приходит опыт специалистов-экспертов. Эти сообщения поступают в экспертную систему COMPASS, которая может предложить провести какой-либо специальный дополнительный тест или заменить определенный узел в системе (реле или плату). Система разработана компанией GTE и эксплуатируется во множестве ее филиалов [Рrеrаи, 1990].
Ранее для поддержания работоспособности телефонной сети компании требовался многочисленный штат опытных наладчиков, которые должны были за ограниченное время проанализировать большое количество зарегистрированных сообщений об отклонениях, обнаруженных в процессе самотестирования, отыскать и устранить неисправность. Радикально решить проблему обслуживания такой сложной структуры могло только создание системы, способной аккумулировать в виде программы опыт специалистов высокого касса и помочь обеспечить таким образом нужный уровень обслуживания. Накопление в системе знаний экспертов осуществлялось в процессе опроса. Эксперты описывали применяемые ими эвристические способы поиска неисправности, а инженеры по знаниям формулировали их в виде правил "если ...
то". Затем эксперты повторно анализировали результаты формализации и проверяли, насколько эти правила согласуются с их опытом и интуицией. При обнаружении разночтений инженеры по знаниям изменяли формулировку правил и совместными усилиями с экспертами добивались, чтобы правила были приемлемыми. Пример одного правила, построенного таким способом, представлен ниже.
ЕСЛИ
существует проблема "ВС Dual Expansion One PGA" и количество сообщений пять или более,
ТО
отказ в узле PGA, в котором горит индикатор расширения (.5), и отказ в резервном узле PGA (.3), и отказ в узле IGA (.1), и отказ в плате переключателей D2 (.1).
Обычно такие правила вводились в систему в виде одного или нескольких производящих правил на языке КЕЕ (подробнее речь о нем пойдет в главе 17), хотя в некоторых случаях более целесообразным кажется использование механизма представления фреймов или языка LISP. Сформулированные на английском языке правила накапливались в библиотеке "документированных знаний", которая являлась одним из компонентов комплекта документации экспертной системы. Эта библиотека помогала сохранить "первоисточник знаний", что очень помогло в процессе настройки и опытной эксплуатации системы.
В процессе приобретения знаний большое внимание, по крайней мере на первых порах, уделялось моделированию применения правил при поиске неисправностей "вручную", т.е. с помощью карандаша и бумаги. Цикл приобретения знаний при разработке системы COMPASS включал следующие этапы.
(1) В процессе собеседования с экспертом извлечь определенные знания.
(2) Задокументировать извлеченные знания.
(3) Проверить новые знания:
попробовать применить их на разных наборах данных;
смоделировать вручную, к каким результатам приведет использование этих знаний;
сравнить результаты моделирования с теми, которые должны получиться по мнению эксперта;
если результаты отличаются, то определить, какие именно правила и процедуры внесли "наибольший вклад" в это отличие; вернуться к п. (1) и выяснить у эксперта, как следует скорректировать подозрительное правило или процедуру.
Графически циклическая процедура приобретения знаний представлена на рис. 10.2.
После того как объем накопленных знаний превысит некоторый минимум, можно проверять работу системы на практике. При этом между этапами документирования и проверки знаний появляется еще один — внедрение знаний в систему. После этого можно проверять адекватность новых знаний не только моделированием вручную, но и выполнением программы на разных наборах входных данных. Конечно, анализ и сравнение результатов при этом усложняются, поскольку на ошибки в процессе формализации могут накладываться и ошибки реализации правил в работающей программе.
Преро (Prerau), ведущий разработчик системы, отметил, что по мере накопления опыта в процессе извлечения знаний инженеру по знаниям легче было общаться с экспертами. Последние постепенно освоились с методикой формализации знаний в виде правил, а инженер по знаниям достаточно глубоко ознакомился со спецификой предметной области. Такое сближение "стилей мышления" можно было рассматривать как признак успешного хода работы над проектом. Определенную помощь в этом, по наблюдению
Преро, сыграло совместное участие инженера по знаниям и эксперта в ручном моделировании процесса принятия решений на основе полученных знаний и последующей проверке результатов.
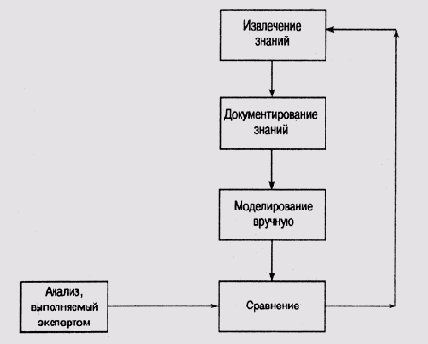
Рис. 10.2. Циклическая процедура приобретения знаний в системе COMPASS
В 1990 году система COMPASS была внедрена на ряде дочерних предприятий фирмы GTE и поначалу эксплуатировалась как вспомогательное средство обслуживания систем, обеспечивавших телефонной связью до полумиллиона абонентов. Успех внедрения системы был во многом обеспечен тем, что при ее разработке использовалась описанная выше методика накопления и формализации знаний. Кроме того, структура системы была задумана таким образом, что не препятствовала дальнейшему накоплению и обновлению знаний даже в процессе эксплуатации.
Эффективность программы OPAL
При разработке прототипа системы ONCOCIN одной из наиболее сложных оказалась именно проблема приобретения знаний. Ввод информации, необходимой для создания протоколов лечения рака лимфатических узлов, занял около двух лет и отнял у экспертов около 800 часов рабочего времени. Формирование последующих наборов протоколов в процессе развития системы занимало, как правило, несколько месяцев. При этом было отмечено, что эффективность процесса приобретения знаний системой в решающей степени зависит от того, насколько успешно инженер по знаниям справляется с ролью переводчика в процессе передачи знаний от экспертов программе. Желание избавиться от этой зависимости и вдохновило разработчиков на создание программы OPAL, которая помогла бы автоматизировать процесс приобретения знаний.
Используя эту программу, эксперт может сформировать новый протокол в течение нескольких дней. За первый год эксплуатации программы OPAL в систему ONCOCIN было добавлено свыше трех дюжин новых протоколов. Эффективность использованного в этой программе метода заполнения формуляров при вводе новых знаний во многом объясняется тем, что в программу включены базовые знания о той предметной области, в которой она используется. Конечно, включение этих знаний потребовало значительных усилий от инженеров по знаниям, которые ранее занимались общением с экспертами, но эти затраты затем с лихвой окупились. Успешное применение программы OPAL показало преимущество представления знаний о предметной области на нескольких уровнях абстракции по сравнению с подходом, предполагающим переключение основного внимания на детали реализации.
Технология извлечения знаний о предметной области у эксперта посредством опроса через терминал в последнее время стала использоваться во множестве экспертных систем. В большинстве из них эксперту предлагается заполнить экранные формуляры, информация из которых затем считывается в структурированные объекты, аналогичные фреймам. Примерами таких систем могут служить ETS [Boose, 1986] и Student [Gale, 1986]. Но далеко не во всех системах такого рода имеется столь развитый графический интерфейс, как в программе OPAL, и существует возможность компилировать полученные знания непосредственно в правила принятия решений. Реализация этих возможностей в OPAL существенно облегчается особенностями структурирования планов лечения онкобольных, на что обращали внимание и авторы этой разработки.
Опыт, приобретенный в ходе разработки программы OPAL, был затем использован при создании PROTEGE — системы более общего назначения [Musen et al., 1995]. Последняя версия этой системы, PROTEGE-II, представляет собой комплект инструментальных средств, облегчающих создание онтологии предметной области и формирование программ приобретения знаний, подобных OPAL, для различных приложений. Вместо того чтобы разрабатывать инструментальные средства общего назначения с нуля, авторы этой разработки пошли по пути повышения уровня абстракции ранее разработанного и успешно используемого приложения, как это было сделано при разработке системы EMYCIN на основе MYCIN.
Методы приобретения знаний
Познакомив читателей с теоретическими вопросами, на которых базируется методика приобретения знаний, и некоторыми ранними разработками в этой области, мы рассмотрим в этом разделе две сравнительно новые системы, которые демонстрируют разные подходы к решению аналогичных задач. Первая из рассматриваемых ниже систем предназначена для поиска неисправностей в переключающей системе телефонной сети, а другая используется при планировании курсов лечения онкобольных. В обоих проектах большое внимание уделено методике приобретения и представления знаний, причем для решения этих задач используются совершенно отличные подходы,
Оболочки экспертных систем
На раннем этапе становления экспертных систем проектирование каждой очередной системы начиналось практически с нуля, в том смысле, что проектировщики для представления знаний и управления их применением использовали самые примитивные структуры данных и средства управления, которые содержались в обычных языках программирования. В редких случаях в существующие языки программирования включались специальные языки представлений правил или фреймов.
Такие специальные языки, как правило, обладали двумя видами специфических средств:
модулями представления знаний (в виде правил или фреймов);
интерпретатором, который управлял активизацией этих модулей.
Совокупность модулей образует базу знаний экспертной системы, а интерпретатор является базовым элементом машины логического вывода. Невольно напрашивается мысль, что эти компоненты могут быть повторно используемыми, т.е. служить основой для создания экспертных систем в разных предметных областях. Использование этих программ в качестве базовых компонентов множества конкретных экспертных систем позволило называть их оболочкой системы.
Онтологический анализ
Александер и его коллеги предложили еще один уровень анализа знаний, который получил название онтологического анализа [Alexander et al., 1986]. В основе этого подхода лежит описание системы в терминах сущностей, отношений между ними и преобразования сущностей, которое выполняется в процессе решения некоторой задачи. Авторы указанной работы используют для структурирования знаний о предметной области три основные категории:
статическая онтология — в нее входят сущности предметной области, их свойства и отношения;
динамическая онтология — определяет состояния, возникающие в процессе решения проблемы, и способ преобразования одних состояний в другие;
эпистемическая онтология — описывает знания, управляющие процессом перехода из одного состояния в другое.
В этой схеме просматривается совершенно очевидное соответствие с уровнями концептуализации знаний и эпистемологического анализа в структуре, предложенной в уже упоминавшейся работе [Wielinga and Breaker, 1986]. Но на нижних уровнях — логического анализа и анализа внедрения — такое соответствие уже не просматривается. Онтологический анализ предполагает, что решаемая проблема может быть сведена к проблеме поиска, но при этом не рассматривается, каким именно способом нужно выполнять поиск. Примером практического применения такого подхода является система OPAL, описанная ниже в разделе 10.3.2.
Рассматриваемая схема онтологического анализа выглядит довольно абстрактной, но ее ценность в том, что она упрощает анализ плохо структурированных задач. Каждый, кто сталкивался с выявлением знаний в процессе опроса человека-эксперта, знает, как трудно найти подходящую схему организации таких знаний. Чаще всего в таких случаях говорят: "Давайте воспользуемся фреймами или системой правил", откладывая таким образом выбор подходящего метода реализации на будущее, когда природа знаний эксперта станет более понятна.
СистемEMYCIN
Примером такой оболочки может служить система EMYCIN, которая является предметно-независимой версией системы MYCIN, т.е. это система MYCIN, но без специфической медицинской базы знаний [van Melle, 1981]. (Само название EMYCIN толкуется авторами системы как "Empty MYCIN" , т.е. пустая MYCIN.) По мнению разработчиков, EMYCIN вполне может служить "скелетом" для создания консультационных программ во многих предметных областях, поскольку располагает множеством инструментальных программных средств, облегчающих задачу проектировщика конкретной экспертной консультационной системы. Она особенно удобна для решения дедуктивных задач, таких как диагностика заболеваний или неисправностей, для которых характерно большое количество ненадежных входных измерений (симптомов, результатов лабораторных тестов и т.п.), а пространство решений, содержащее возможные диагнозы, может быть достаточно четко очерчено.
Некоторые программные средства, впервые разработанные для EMYCIN, в дальнейшем стали типовыми для большинства оболочек экспертных систем. Среди таких средств следует отметить следующие.
Язык представления правил. В системе EMYCIN такой язык использует систему обозначений, аналогичную языку ALGOL. Этот язык, с одной стороны, более понятен, чем LISP, а с другой— более строг и структурирован, чем тот диалект обычного английского, который использовался в MYCIN.
Индексированная схема применения правил, которая позволяет сгруппировать правила, используя в качестве критерия группировки параметры, на которые ссылаются эти правила. Так, правила, применяемые в MYCIN, разбиваются на группы: CULRULES — правила, относящиеся к культурам бактерий, ORGRULES — правила, касающиеся организмов, и т.д.
Использование обратной цепочки рассуждений в качестве основной стратегии управления. Эта стратегия оперирует с И/ИЛИ-деревом, чьи листья представляют собой данные, которые могут быть найдены в таблицах или запрошены пользователем.
Интерфейс между консультационной программой, созданной на основе EMYCIN, и конечным пользователем.
Этот компонент оболочки обрабатывает все сообщения, которыми обмениваются пользователь и программа (например, запросы программы на получение данных, варианты решения, которые формирует программа в ответ на запросы пользователя, и т.п.).
Интерфейс между разработчиком и программой, обеспечивающий ввод и редактирование правил, редактирование знаний, представленных в форме таблиц, тестирование правил и выполнение репрезентативных задач.
Значительная часть интерфейса реализуется отдельным компонентом EMYCIN — программой TEIRESIAS [Davis, 1980,b]. Эта программа представляет собой "редактор знаний", который упрощает редактирование и сопровождение больших баз знаний. Редактор проверяет синтаксическую корректность правил, анализирует взаимную непротиворечивость правил в базе знаний и следит за тем, чтобы новое правило не являлось частным случаем существующих. Противоречие возникает, когда два правила с одинаковыми антецедентами имеют противоречивые консеквенты. Одно правило является частью другого в том случае, когда совокупность условий антецедента одного правила представляет собой подмножество совокупности условий другого правила, а их консеквенты одинаковы. Но в состав TEIRESIAS не включены знания о какой-либо конкретной предметной области или о стратегии решения проблем, которая может быть использована в проектируемой экспертной системе.
Такая организация программы TEIRESIAS является, с одной стороны, ее достоинством, а с другой — недостатком. Общность интерфейса, его независимость от назначения проектируемой экспертной системы — достоинства TEIRESIAS. Используемые в ней методы синтаксического анализа могут быть применены к правилам, относящимся к любой предметной области. А тот факт, что эта программа привносит существенные сложности в процесс общения инженера по знаниям с экспертом, является ее недостатком. Зачастую знания, которыми располагает эксперт, не укладываются в жесткие рамки синтаксических правил, на соблюдении которых "настаивает" TEIRESIAS.Тем не менее эта программа включает множество новшеств, которые имеет смысл рассмотреть подробнее, что мы и сделаем в следующем разделе. Другие аналогичные программные средства, предназначенные для облегчения процесса извлечения знаний, детально описаны в разделе 10.3 с учетом семантики предметной области.
Сопровождение и редактирование баз знаний с помощью программы TEIRESIAS
Как правило, человек-эксперт знает о той предметной области, в которой он является специалистом, гораздо больше, чем может выразить на словах. Вряд ли можно добиться от него многого, задавая вопросы в общем виде, например: "Что вам известно об инфекционных заболеваниях крови?" Гораздо продуктивнее подход, реализованный в программе TEIRESIAS, который предполагает вовлечение эксперта в решение несложных репрезентативных задач из определенной предметной области и извлечение необходимых знаний в процессе такого решения.
Задавшись определенным набором базовых правил, представляющих прототип экспертной системы, TEIRESIAS решает в соответствии с этими правилами какую-нибудь из сформулированных репрезентативных проблем и предлагает эксперту критиковать результаты. В ответ эксперт должен сформулировать новые правила и откорректировать введенные ранее, а программа отслеживает внесенные изменения, анализирует их на предмет сохранения целостности и непротиворечивости всего набора правил, используя при этом модели правил. В процессе анализа используется обобщение правил различного вида.
Например, правила системы MYCIN, предназначенные для идентификации организмов, содержат в предпосылках сведения о параметрах анализируемой культуры организмов и типе инфекции. Таким образом, если эксперт собирается добавить новое правило такого типа, то вполне резонно предположить, что в нем должны упоминаться аналогичные параметры. Если же это не так, то, как минимум, нужно обратить на это внимание пользователя и предоставить в его распоряжение средства, помогающие что-либо сделать с этими параметрами.
Другая модель правил может учитывать тот факт, что правила, касающиеся образцов культур и типов инфекции, среди прочих, должны в антецедентной части включать и способы проникновения инфекции в организм пациента. Опять же, система может запросить эту информацию у пользователя, если при формулировке нового правила этого типа она была опущена. Более того, можно догадаться, какой именно способ проникновения обычно бывает связан с теми клиническими показаниями, которые содержатся в данном правиле, и обратить внимание пользователя на возможное несоответствие.
Модели правил являются, по существу, метаправилами, уже рассмотренными в главе 5, поскольку они предназначены для выработки суждений о правилах, а не об объектах предметной области приложения. В частности, в программе TEIRESIAS имеются метаправила, относящиеся к атрибутам правил объектного уровня. Такие правила обращают внимание пользователя на то, что в данных обстоятельствах целесообразно сначала исследовать определенные параметры, а уж затем в процессе отладки набора правил пытаться отслеживать влияние других параметров.
Существуют также средства, помогающие эксперту добавить новые варианты типов данных. Ошибки, которые обычно возникают при решении подобных задач, состоят в том, что новые типы данных имеют структуру, не согласующуюся с типами, уже существующими в системе. Например, если предпринимается попытка включить в систему MYCIN новый клинический параметр, то он должен унаследовать структуру атрибутов, связанную с другими аналогичными параметрами, а значения атрибутов должны иметь согласованные диапазоны представления.
Абстрактные данные, которые используются для формирования новых экземпляров структур данных, называются схемами. Эти схемы представляют собой обобщенные описания типов данных, точно так же, как структуры данных являются обобщениями конкретных данных. Следовательно, схемы также могут быть организованы в виде иерархической структуры, в которой каждая схема, во-первых, наследует атрибуты, ассоциированные с ее предшественницей в иерархии, а во-вторых, имеет еще и собственные дополнительные атрибуты.
В таком случае процесс создания нового типа данных включает прослеживание пути от корня иерархии схем к той схеме, которая представляет интересующий нас тип данных. На каждом уровне имеются атрибуты, которые нужно конкретизировать, причем процесс продолжается до тех пор, пока не будет конкретизирована вся структура. Отношения между схемами в иерархии определяют последовательность выполнения задач обновления структур данных в системе.
Таким образом, в программе TEIRESIAS можно выделить три уровня обобщения:
знания об объектах данных, специфические для предметной области;
знания о типах данных, специфические для метода представления знаний;
знания, независимые от метода представления.
Из сказанного выше следует, что эксперт может использовать программу TEIRESIAS для взаимодействия с экспертной системой, подобной MYCIN, и следить с ее помощью за тем, что делает экспертная система и почему. Поскольку на этапе разработки экспертной системы мы всегда имеем дело с неполным набором правил, в котором к тому же содержится множество ошибок, можно задать вопрос эксперту: "Что вы знаете такого, что еще не знает программа?" Решая конкретную проблему, эксперт может сосредоточить внимание на корректности правил, вовлеченных в этот процесс, из числа тех, что ранее введены в систему, их редактировании при необходимости или включении в систему новых правил.
В составе TEIRESIAS имеются и средства, которые помогают оболочке EMYCIN следить за поведением экспертной системы в процессе применения набора имеющихся правил.
Режим объяснения (EXPLAIN). После выполнения каждого очередного задания — консультации — система дает объяснение, как она пришла к такому заключению. Распечатываются каждое правило, к которому система обращалась в процессе выполнения задания, и количественные параметры, связанные с применением этого правила, в том числе и коэффициенты уверенности.
Режим тестирования (TEST). В этом режиме эксперт может сравнить результаты, полученные при прогоне отлаживаемой программы, с правильными результатами решения этой же задачи, хранящимися в специальной базе данных, и проанализировать имеющиеся отличия. Оболочка EMYCIN позволяет эксперту задавать системе вопросы, почему она пришла к тому или иному заключению и почему при этом не были получены известные правильные результаты.
Режим просмотра (REVIEW). В этом режиме эксперт может просмотреть выводы, к которым приходила система при выполнении одних и тех же запросов из библиотеки типовых задач. Это помогает просмотреть эффект, который дают изменения, вносимые в набор правил в процессе наладки системы.
В этом же режиме можно проанализировать, как отражаются изменения в наборе правил на производительности системы.
Нужно отметить, что не существует общепринятой методологии использования режима REVIEW, но в литературе имеются сообщения об исследовании процесса настройки отдельных правил (см., например, [Langlotz et al., 1986]) и оптимизации набора правил с помощью этого режима (например, [Wilkins and Buchanan, 1986]). Об этих работах мы поговорим в главе 20.
Система EMYCIN была одной из первых попыток создать программный инструмент, позволяющий перенести архитектуру экспертной системы, уже эксплуатируемой в одной предметной области, на другие предметные области. Опыт, полученный в процессе работы с EMYCIN, показал, что те инструментальные средства, которые были включены в состав EMYCIN, пригодны для решения одних проблем и мало что дают при решении других. В результате многих исследователей заинтересовали вопросы: "Какие именно характеристики проблемы делают ее более или менее пригодной для решения с помощью системы, подобной EMYCIN? Связано ли это с какими-то характеристиками предметной области, с.о стилем логического вывода или с размерностью решаемых задач?"
Мы вернемся к обсуждению этого вопроса в главах 11 и 12, но уже сейчас можно отметить, что разработка системы EMYCIN и других, ей подобных, заставила задуматься над этими вопросами. В частности, исследователи заинтересовались классификацией проблем, таких как медицинская диагностика, планирование маршрутов движения, интерпретация сигналов в системах ультразвуковой локации и т.п. Такая классификация стала рассматриваться в качестве этапа, предваряющего поиск методов решения задач указанных классов. Другими словами, исследователи начали изобретать различные методы описания проблем, отталкиваясь от предписываемых для их решения методов. Это, в свою очередь, привело к попытке установить связь между типами проблем и методами приобретения знаний, подходящих для их решения. Организация и методы восприятия знаний, необходимых для решения задач медицинской диагностики и поиска неисправностей в электронных схемах, весьма отличаются от тех, которые нужны для построения планов производства или выбора конфигурации вычислительной системы.
Стадии приобретения знаний
В работе [Buchanan et al, 1983] предлагается выполнить анализ процесса приобретения знаний в терминах модели процесса проектирования экспертной системы (рис. 10.1).

Рис. 10.1. Стадии приобретения знаний
(1) Идентификация. Анализируется класс проблем, которые предполагается решать с помощью проектируемой системы, включая данные, которыми нужно оперировать, и критерии оценки качества решений. Определяются ресурсы, доступные при разработке проекта, — источники экспертных знаний, трудоемкость, ограничения по времени, стоимости и вычислительным ресурсам.
(2) Концептуализация. Формулируются базовые концепции и отношения между ними. Сюда же входят и характеристика различных видов используемых данных, анализ информационных потоков и лежащих в их основе структур в предметной области в терминах причинно-следственных связей, отношений частное/целое, постоянное/временное и т.п.
(3) Формализация. Предпринимается попытка представить структуру пространства состояний и характер методов поиска в нем. Выполняется оценка полноты и степени достоверности (неопределенности) информации и других ограничений, накладываемых на логическую интерпретацию данных, таких как зависимость от времени, надежность и полнота различных источников информации.
(4) Реализация. Преобразование формализованных знаний в работающую программу, причем на первый план выходит спецификация методов организации управления процессом и уточнение деталей организации информационных потоков. Правила преобразуются в форму, пригодную для выполнения программой в выбранном режиме управления. Принимаются решения об используемых структурах данных и разбиении программы на ряд более или менее независимых модулей.
(5) Тестирование. Проверка работы созданного варианта системы на большом числе репрезентативных задач. В процессе тестирования анализируются возможные источники ошибок в поведении системы. Чаще всего таким источником является имеющийся в системе набор правил. Оказывается, что в нем не хватает каких-то правил, другие не совсем корректны, а между некоторыми обнаруживается противоречие.
Как видно из рис. 10.1, проектирование экспертной системы начинается с анализа класса проблем, которые предполагается решать с помощью этой системы. Было бы ошибкой приступать к проектированию системы, заранее задавшись определенной концепцией или определенной структурной организацией знаний. Весьма сомнительно, чтобы тот вариант концепции или тот способ организации идей, которым мы задались априори, взяв за основу предыдущие разработки, был приложим и к новой предметной области.
Теоретический анализ процессприобретения знаний
В главе 1 отмечалось, что при извлечении знаний в ходе опроса экспертов за рабочий день удается сформулировать от двух до пяти "эквивалентов порождающих правил". Причин такой низкой производительности несколько:
прежде чем приступить к опросу экспертов, инженер по знаниям, который не является специалистом в данной предметной области, должен потратить довольно много времени на ознакомление с ее спецификой и терминологией; только после этого процесс опроса может стать продуктивным;
эксперты склонны думать о знакомой им области не столько в терминах общих принципов, сколько в терминах отдельных типических объектов, событий и их свойств;
для представления специфических знаний о предметной области нужно подобрать подходящую систему обозначений и структурную оболочку, что само по себе является непростой задачей.
Как известно, любую сложную задачу лучше всего разбить на подзадачи, и именно так мы поступим с задачей приобретения знаний.
В состав документации, которая прилагается
1. В состав документации, которая прилагается к большинству приборов и технических изделий, как правило, входят и руководства по поиску неисправностей. При отсутствии эксперта такие руководства можно с успехом использовать в качестве учебного материала для выполнения упражнений по извлечению знаний.
Например, руководство к пистолету "Кольт .45" включает шесть страниц советов, большинство из которых представлено в форме подобных таблиц.
|
Где? |
Что? |
Проверить |
Примечание |
||
|
Боек |
Зажимается |
Прямизну |
При необходимости заменить |
||
|
Эжектор |
Неустойчивое выбрасывание |
Зажимается ли возвратная пружина |
Установить длинную направляющую |
||
|
Экстрактор |
Неправильно направляет гильзу |
Угол установки дна |
При необходимости выровнять |
||
Для того чтобы разобраться в такой таблице, требуется обладать некоторыми знаниями о принципах работы описываемого устройства. В частности, нужно иметь представление о том, что
искривленный боек часто застревает в направляющей канавке, что приводит к осечке; такой боек нужно заменить;
возвратная пружина, которая зажимается внутри канавки, вероятнее всего, погнута; предотвратить такую поломку поможет замена стандартного короткого направляющего стержня полноразмерным;
неправильный угол установки экстрактора приводит к тому, что он выбрасывает гильзы обратно на стреляющего, а не вправо; эту неисправность можно устранить подгонкой и шлифовкой дна экстрактора.
Применение онтологического анализа позволяет систематизировать такое ознакомление. Самый верный путь к неудаче — приступить к записи диагностических правил до того, как будет понятен принцип работы устройства.
I) Выберите ту предметную область, которая вам более всего знакома, и разработайте для нее примерную онтологию в терминах:
ключевые сущности и отношения, такие как компоненты и отношения часть-целое;
предикаты предметной области, такие как неустойчивые, прямые, связывающие;
операции в предметной области, такие как замена, очистка, установка и т.п.
;; изделия,
(defrule part-no
(model ?mod£Tnil)
?rep <- (repair (part ?part)
(action replace) (check part-no)) =>
(bind ?no (send (symbol-to-instance-name ?mod)
part-no ?part))
(printout t crlf
" The part number of the " ?mod " " ?part "
is " ?no crlf) ;; "Номер узла " ?mod " " ?part ?no
(modify ?rep (check done)) )
;; Правила BARREL (ствол)
;; Правило BARREL-SYMPTOM
;; ЕСЛИ: Неисправность не имеет признаков
;; ТО: Выяснить признак (симптом),
(defrule barrel-symptom
?prob <- (problem (part barrel)
(symptom nil) (subpart nil))
=>
(printout t crlf
"Is there a problem inside barrel? " crlf)
;; "Есть ли повреждения внутри ствола?"
(prompt)
(bind ?answer(read))
(if (eq ?answer yes)
then (modify ?prob (subpart bore))
) )
;; Правило BARREL-INSIDE
;; ЕСЛИ: Имеется повреждение канала ствола
;; ТО: Выяснить у пользователя,
;; какое (и предложить помощь).
(defrule barrel-inside
?prob <- (problem (part barrel) (symptom nil) (subpart bore))
=>
(printout t crlf
"What is the problem inside the barrel? " crlf)
;; "Характер повреждения канала ствола?"
(choose-list) (printout t crlf "
leading rust jam" crlf)
;; " наличие ржавчины"
(prompt)
(bind ?answer (read))
(modify ?prob (symptom ?answer)) )
;; Правило BARREL-RUST
;; ЕСЛИ: Имеется ржавчина в канапе ствола
;; ТО: Проверить наличие раковин.
(defrule barrel-rust
?prob <- (problem (part barrel) (symptom rust) =>
(printout t crlf
"Are there pits inside the barrel? " crlf)
;; "Нет ли раковин в канале ствола?" (prompt)
(bind ?answer (read))
(if (eq ?answer yes) then (assert (repair
(action replace) (part barrel) (subpart bore))
(remark "Please consult your local dealer")))
;; Проконсультируйтесь с местным дилером
else (assert (repair
(action clean) (part barrel) (subpart bore))
(remark " Gun should be kept clean and dry"))
;; Оружие нужно содержать в чистоте и
;; предохранять от сырости
) )
;; Правило BARREL-LEADING
;; ЕСЛИ: Имеется налет свинца в канале ствола
;; ТО: Проверить качество патронов,
(defrule barrel-leading
?prob .<- (problem (part barrel) (symptom
leading) (check nil))
=>
(modify ?prob (check ammo))
(printout t crlf
"You may be using the wrong ammunition " crlf)
;; "Возможно, вы пользуетесь некачественными
;; патронами" )
;; Правило BARREL-LEADING-CHECK
;; ЕСЛИ: Имеется налет свинца в канале ствола
;; ТО: Проверить качество патронов,
(defrule barrel-leading-check
Pprob <- (problem (part barrel) (symptom
leading) (check ammo))
=>
(assert (repair (part barrel)
(action clean) (subpart bore)
(remark "Use Lewis Lead Remover"))
;; Воспользуйтесь средством для удаления свинца
;; фирмы Lewis )
Если посчитаете нужным, скопируйте из этой программы вспомогательные функции и структуры определения правил, но используйте знания из другой предметной области, которые были приобретены при выполнении предыдущего упражнения.
3. Рассмотрите ситуацию, которая возникает при планировании покупки какой-нибудь дорогостоящей вещи. Пусть, например, у вас появилась идея приобрести новый автомобиль. Эту проблему можно будет считать хорошо определенной только после того, как вы решите, какую сумму можно потратить на эту покупку, для каких поездок будет в основном использоваться новый автомобиль, какой изготовитель и какая модель для вас предпочтительны, и т.п. Для подобных упражнений можно использовать не только пример с автомобилем, но и с другими видами дорогостоящих покупок, — загородный дом, высококачественная электронная аппаратура и т.д. Далее уточните спецификацию покупки следующим образом.
I) Составьте список ключевых концепций и отношений между ними, которые нужно учитывать при решении проблемы. В случае с автомобилем такой список, очевидно, будет включать атрибуты фирмы-изготовителя и модели автомобиля, разнообразные эксплуатационные характеристики (мощность двигателя, расход топлива), связи между этими атрибутами и параметрами, определяющими ваш "стиль жизни", — частота и продолжительность поездок, предполагаете ли вы брать в поездку каких-либо экзотических попутчиков (лошадь или собаку) или необычный груз (например, лодку, домик на колесах) и т.п.
II) Попробуйте найти способ формального представления перечисленных концепций и отношений между ними. Например, изготовитель автомобиля и его модель могли бы быть выбраны из существующего набора классов — седан, спортивное авто, микроавтобус и т.д. Проанализируйте, не нужно ли при этом использовать многомерную классификацию концепций, при которой придется использовать множественное наследование.
III) Обратите внимание на важность учета приоритета разных свойств рассматриваемого объекта и необходимость использования средств разрешения конфликтов между ними. Если, например, хочется купить автомобиль, который, с одной стороны, имеет мощный двигатель, а с другой стороны, потребляет мало бензина, то нужно подумать над тем, как найти компромисс между этими противоречивыми требованиями.
4. Составьте на языке CLIPS несложную консультационную программу, которая помогла бы пользователю в решении проблемы целесообразности покупки, сформулированной при выполнении предыдущего упражнения. При разработке программы главное внимание нужно уделить тому, как представить сформулированные ранее концепции и отношения между ними в виде структур данных. Нужно также продумать и режимы управления, которые учитывали бы как структуру пространства состояний (например, способ классификации автомобилей), так и механизм обработки приоритетов свойств и разрешения конфликтов между ними.
5. До какого уровня детализации, по вашему мнению, можно спроектировать экспертную систему, не зная, как она будет внедряться? Какие опасности, по-вашему, подстерегают разработчика, который слишком рано принимает решение о способе внедрения экспертной системы?
Уровни анализзнаний
Приведенное выше разделение на этапы встречается также и в работе Уилинги, который разработал моделирующий подход к инженерии знаний в рамках созданной им среды KADS [Wielinga et al, 1992]. В основе этого подхода лежит идея о том, что экспертная система является не контейнером, наполненным представленными экспертом знаниями, а "операционной моделью", которая демонстрирует некоторое нужное нам поведение в столкновении с явлениями реального мира. Приобретение знаний, таким образом, включает в себя не только извлечение специфических знаний о предметной области, но и интерпретацию извлеченных данных применительно к некоторой концептуальной оболочке и формализацию их таким способом, чтобы программа могла действительно использовать их в процессе работы.
В основу оболочки KADS положено пять базовых принципов.
(1) Использование множества моделей, позволяющее преодолеть сложность процессов инженерии знаний.
(2) Четырехуровневая структура для моделирования требуемой экспертности — набора качеств, лежащих в основе высокого уровня работы специалистов.
(3) Повторное использование родовых компонентов модели в качестве шаблонов, поддерживающих нисходящую стратегию приобретения знаний.
(4) Процесс дифференциации простых моделей в сложные.
(5) Важность преобразования моделей экспертности с сохранением структуры в процессе разработки и внедрения.
Ниже мы рассмотрим подробно два первых принципа.
Главным мотивом создания оболочки KADS было преодоление сложности знаний. На сегодняшний день у инженеров по знаниям имеется возможность использовать при построении экспертных систем множество самых разнообразных методов и технологий. Однако при этом остаются три основных вопроса:
определение проблемы, которую необходимо решить с помощью экспертной системы;
определений функций, которые возлагаются на экспертную систему применительно к этой проблеме;
определение задач, которые необходимо решить для выполнения возложенной функции.
Первый из принципов, положенных в основу KADS, состоит в том, что оболочка должна содержать множество частных моделей, помогающих найти ответ на эти вопросы.
Примерами таких моделей могут служить:
организационная модель "социально-экономической среды", в которой должна функционировать система, например финансовые услуги, здравоохранение и т.п.;
прикладная модель решаемой проблемы и выполняемой функции, например диагностика, планирование расписания работ и т.д.;
модель задач, демонстрирующая, как должна выполняться специфицированная функция, для чего производится ее разбиение на отдельные задачи, например сбор данных о доходах, формирование гипотез о заболеваниях.
Между этой терминологией и той, которой пользовался Бучанан, нет прямого соответствия, но можно сказать, что организационная и прикладная модели аналогичны стадии идентификации в предложенной Бучананом структуре.
В подходе, который реализован при создании KADS, стадия "концептуализации" разбивается на две части: модель кооперации, или коммуникации, и модель экспертности. Первая отвечает за декомпозицию процесса решения проблемы, формирование набора простейших задач и распределение их между исполнителями, в качестве которых могут выступать и люди, и машины. Вторая модель представляет процесс, который обычно называется извлечением знаний, т.е. анализ разных видов знаний, которые эксперт использует в ходе решения проблемы.
Кроме указанных, в состав оболочки KADS входит еще и модель проектирования, включающая технологии вычислений и механизмы представления знаний, которые могут быть использованы для реализации спецификаций, сформулированных предыдущими моделями.
На первый взгляд кажется, что представленный выше анализ в какой-то степени смазывает отличие между стадиями концептуализации и формализации. Можно, конечно, возразить, что стадия формализации представляет собой просто более детальную проработку концепций и отношений, выявленных на ранних стадиях. Модель проектирования частично включает то, что в прежней схеме было отнесено к стадии реализации, но она не предполагает создание выполняемой программы.
В своей ранней работе Уилинга немного по-другому проводил разграничение между уровнями анализа [Wielinga and Breuker, 1986]. Он рассматривал четыре уровня анализа.
Концептуализация знаний. На этом уровне предполагалось формальное описание знаний в терминах принципиальных концепций и отношений между концепциями.
Уровень эпистемологического анализа. Целью такого анализа было выявление структурных свойств концептуальных знаний, в частности таксономических отношений.
Уровень логического анализа. Основное внимание уделялось тому, как строить логический вывод в данной предметной области на основе имеющихся знаний.
Уровень анализа внедрения. Исследовались механизмы программной реализации системы.
В более поздней разработке три первых уровня включены в состав модели экспертно-сти, а уровень анализа внедрения — в модель проектирования. Четырехуровневая структура KADS согласуется с предложенной Кленси схемой разделения знаний различного вида в соответствии с их ролью в процессе решения проблем [Clancey, 1985]. Подробно схема Кленси будет рассмотрена в главе 11. В частности, знания, касающиеся конкретной предметной области, теперь разделены на знания более высокого уровня (знания, относящиеся к построению логического вывода в этой предметной области), знания выбора решаемых задач и знания стратегии решения задач.
Эти уровни знаний представлены в табл. 10.1. Стратегический уровень управляет процессом выполнения задач, использующих при решении проблем методы логического вывода, подходящие для конкретной предметной области, и знания из этой области. Анализ такой схемы дифференциации знаний будет проведен в следующей главе.
Сейчас же только отметим, что описанная схема дифференциации знаний приводит нас к довольно простой архитектуре экспертной системы. В частности, оказывается, что даже в рамках традиционной архитектуры, предполагающей наличие базы знаний и машины логического вывода, можно неявным образом включить задачи и стратегии и в структуру знаний о предметной области, и в механизм построения логических заключений. Мы еще увидим в дальнейшем, что явное выделение этих задач и стратегий является главным моментом как в процессе приобретения знаний, так и в процессе проектирования структуры экспертной системы.
Таблица 10.1. Четырехуровневая схема дифференциации знании в системе KADS
Категория знаний |
Организация |
Виды знаний |
||
Стратегическая |
Стратегии |
Планы, метаправила |
||
Задача |
Задачи |
Цели, управляющие термы, структуры задач |
||
Логический вывод |
Структура логического вывода |
Источники знаний, метаклассы, схема предметной области |
||
Предметная область |
Теория предметной области |
Концепции, свойства, отношения |
||
Описанные принципы построения оболочки системы приобретения знаний получили дальнейшее развитие в системе CommonKADS [Breaker and van de Velde, 1994]. Эта система поддержки инженерии знаний содержит редакторы каждого из перечисленных типов моделей и множество инструментальных средств и компонентов, облегчающих проектирование экспертной системы. Существенную помощь менеджеру проекта при планировании работ должна оказать модель жизненного цикла экспертной системы. В дополнение к тем моделям, которые входили в состав ранних версий оболочки KADS, в новую версию включено несколько новых, в частности модель агента, которая представляет саму экспертную систему, ее пользователей и подключенные вычислительные системы.
В рамках проекта KASTUS онтология и методология оболочки KADS была использована и при построении больших повторно используемых баз знаний [Wielinga and Schreiber, 1994]. Наименование проекта KASTUS — сокращение от Knowledge about Complex Technical Systems for Multiple Use (знания многоразового применения о сложных технических системах). Цель проекта — создание системы знаний, которую можно было бы использовать в множестве разнообразных приложений.
Уилинга и его коллеги сформулировали ряд принципов, которые составили основу 'методологии построения баз данных совместного использования. Один из них предполагает четкое разделение знаний, относящихся к предметной области и методам управления процессом применения знаний, другой — дальнейшее углубление онтологии предметной области, т.е.модели сущностей этой области и отношений между сущностями. Углублению и развитию этих двух концепций посвящено целое направление в современной литературе по экспертным системам, в которой такой подход противопоставляется методологии, основанной на приоритете технологий программирования, таких как формализм порождающих правил.
Инструментальные средстви задачи
12.1. Инструментальные средства и задачи, решаемые экспертной системой
В своей статье [Clancey, 1985] Кленси отметил, что хотя языки, базирующиеся на правилах, такие как EMYCIN, и не учитывают многих свойств предложенной им модели эвристической классификации, все же они являются достаточно подходящими инструментами для задач классификации, в частности задач диагностики. Хотя вразрез с рекомендациями Кленси ни система MYCIN, ни системы, базирующиеся на EMYCIN, не содержат специфических средств таксономии симптомов или признаков неисправностей, тот факт, что решения могут быть заранее пронумерованы, означает, что можно применить обратную стратегию построения суждений, т.е. строить логическую цепочку от абстрактных категорий решений к подходящим данным через промежуточный этап абстрагирования данных. Этот этап неявно включен в используемые правила. Тот факт, что выводы из набора правил индексируются в терминах медицинских параметров, на которые они ссылаются, позволяет без особого труда реализовать стратегию рассуждения от цели к средствам.
Ранее мы уже упоминали о таких особенностях MYCIN, как отказ от обратного прослеживания в пользу деструктивной модификации рабочей памяти и использование стратегии исчерпывающего поиска.
Эти две особенности MYCIN тесно увязаны. Нет необходимости использовать обратное прослеживание, поскольку мы неотступно следуем за множеством независимых свидетельств и на заключительной стадии ранжируем гипотезы. Если бы не использовалась стратегия достаточно исчерпывающего поиска, то потребовалось бы выполнять в той или иной форме обратное прослеживание, как это было показано в главе 2. Процесс обратного прослеживания требует больших затрат вычислительных ресурсов системы, так как приходится сохранять информацию о предыдущих этапах вычислений, к которым, возможно, придется еще возвращаться. Большой объем пространства состояний, в котором ведется поиск, требует значительных ресурсов памяти. На практике при этом используется механизм постраничного обмена между оперативной и дисковой памятью, что отрицательно сказывается на производительности системы в целом.
Однако значительные вычислительные ресурсы отвлекаются на активизацию каждого потенциально подходящего правила, от чего приходится отказываться в некоторых системах. Во многих системах используется методика восхождение на гору, в которой принятие решения об использовании некоторого правила не может быть пересмотрено или отменено (см. главу 2). Иногда при этом может потребоваться использование локального обратного отслеживания (подробнее об этом — в главе 14 и в Приложении).
Такой простой режим управления редко используется при решении проблем конструирования. Проблемы проектирования и формирования конфигураций, как правило, требуют использования средств, характеризующихся наличием множества альтернативных способов решения, причем эти способы отнюдь не равноценны по качеству результата. Довольно часто приходится сталкиваться с ситуацией, когда отсутствует хорошая оценочная функция, которую можно было бы применить при поиске в пространстве состояний. Это объясняется тем, что качество проектирования определяется не только изолированными свойствами проектируемой конструкции и ее компонентов, но и глобальными параметрами, которые можно оценить только после завершения проектирования конечного продукта. Например, при решении задачи рациональной расстановки мебели в помещениях нужно принимать во внимание необходимость удовлетворения определенных ограничений и пожеланий: желательно письменный стол ставить вблизи окна, книжный шкаф размещать недалеко от письменного стола, диван ставить против телевизора и т.д. Но сформированные решения могут удовлетворять одним пожеланиям (ограничениям) и не удовлетворять другим, поскольку нужно удовлетворить какие-либо важные глобальные ограничения — оставить свободным проход через комнаты или обеспечить единообразную расстановку мебели.
В главах 14 и 15 мы еще познакомимся с дополнительными стратегиями управления поиском, которые приходится использовать в задачах конструирования. Сюда входят:
стратегия наименьшего принуждения (least commitment) — стремление отложить на будущее, насколько это возможно, принятие решений, ограничивающих свободу последующего выбора;
стратегия предложения и исправления (propose and revise) — стремление устранить нарушение сформулированных ограничений, как только такое нарушение обнаруживается;
различные виды обратного прослеживания, когда при обнаружении нарушения определенных условий пересматриваются только что принятые решения и выполняется откат в предшествующее состояние.
Отображение таких методов на множество типов решаемых задач — предмет дальнейших исследований.
Как бы там ни было, но для выбора подходящих инструментальных средств построения экспертных систем существенную роль играет идентификация уровня задач анализа, которая базируется на используемых методах решения проблем. Этот уровень, как правило, располагается между более высокими концептуальным и эпистемологическим уровнями и более низкими логическим и уровнем реализации, о которых шла речь в главе 10. Если не выполнить такую идентификацию, появляется опасность утраты обобщенных связей между типами задач и структурами логического вывода и языками представления знаний.
Использование коэффициентов уверенности в программе MORE
Выше уже не раз обращалось внимание на тот факт, что эксперты зачастую испытывают серьезные затруднения при назначении коэффициентов уверенности конкретным правилам. Прежде чем назначить коэффициент новому правилу, эксперты любят просмотреть уже сформулированные и сравнить установленные в них значения с тем, которое планируется присвоить новому правилу. Они стараются добиться взаимной увязки всех сформулированных правил как в отношении степени важности отдельных свидетельств, так и в отношении "крепости" ассоциативных связей между свидетельствами и гипотезами. Как помочь эксперту решить эту задачу?
Определенную помощь в этом эксперту может оказать программа MORE, которая формирует предположительные значения коэффициентов, основываясь на ранее введенных правилах, и предлагает их эксперту. Если введенное экспертом значение игнорирует предложенные программой, то выводится предупреждающее сообщение для инженера по знаниям, в котором программа приводит свои соображения относительно обнаруженного противоречия. После этого пользователь имеет возможность воспользоваться набором опций и устранить противоречие между параметрами нового правила и ранее созданных.
Программа MORE формирует предположительные значения коэффициентов следующим образом.
Предположим, что неисправность D проявляется в виде симптома S1 а появление симптома S1 влечет за собой и появление симптома S2. В таком случае программа MORE предполагает, что отрицательный коэффициент уверенности, назначенный правилу, которое связывает симптом S1 с гипотезой D, будет больше или равен отрицательному коэффициенту, назначенному правилу, которое связывает симптом S2 с гипотезой D. В схеме модели событий на рис. 12.2 ожидается, что С1=> С2. Здесь коэффициентом С, оценивается связь между симптомом S1 и гипотезой D, а коэффициентом С2 — связь между симптомом S2 и гипотезой D.
Почему предполагается такое соотношение между значениями коэффициентов, интуитивно понятно. Если отсутствие симптома S1 является более веским аргументом против гипотезы D, то отсутствие симптома S2 не меняет положения дел.
Если вновь вернуться к модели событий на рис. 12.1, то отрицательная связь между притоком воды и повышением уровня содержания неэмульсионной воды должна быть более "сильной", чем связь между притоком воды и повышением вязкости.
Диагностическая значимость симптома является величиной, обратной количеству гипотез, в которых учитывается наличие этого симптома. В модели событий, схема которой представлена на рис. 12.3, программа MORE предполагает, что С1 > С2, поскольку появление симптома S1 может быть вызвано только неисправностью (гипотезой) D1, a появление симптома S2 может быть вызвано и другими неисправностями.
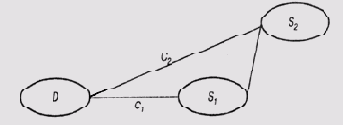
Рис. 12.2. Отрицательные коэффициенты достоверности в цепочке причинно-следственной связи
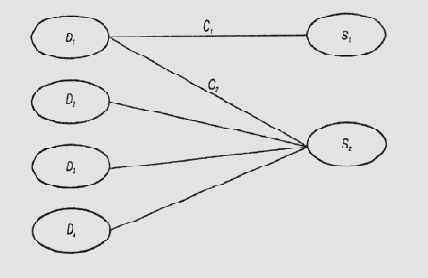
Рис. 12.3. Положительные коэффициенты достоверности в случае множественной связи симптома с гипотезами
Программа MORE также оценивает и отношения между значениями коэффициентов в правилах одного семейства (т.е. в правилах, делающих одинаковое заключение или, что то же самое, относящихся к одной и той же гипотезе). Например, если в семейство правил добавляется новое условие проявления симптома, которое увеличивает условную достоверность симптома, это скажется на тех правилах, которые имеют большие отрицательные значения коэффициентов, чем составные правила. (Напомним, что составными называются правила, расширенные при добавлении нового условия.) Рациональность этих предположений заключается в том, что чем больше мы рассчитываем на появление определенного симптома при данной гипотезе (при данной неисправности), тем сильнее будет наше недоверие к этой гипотезе при отсутствии такого симптома.
Каждое из таких предположений основано на стремлении сохранить взаимную согласованность коэффициентов в правилах одного семейства.
Эвристическая классификация (II)
12.1. Инструментальные средства и задачи, решаемые экспертной системой
12.2. Эвристическая классификация в системах MUD и MORE
12.3. Совершенствование стратегий Рекомендуемая литература Упражнения
Сейчас мы продолжим начатый в предыдущей главе анализ различий между задачами классификации и конструирования. Но теперь основное внимание будет сосредоточено на методах решения проблем, включая и различные способы представления знаний и реализации машины логического вывода. В частности, мы подробно рассмотрим типы инструментальных программных средств, наиболее подходящих для разработки систем эвристической классификации, примеры использования эвристической классификации в экспертных системах, более современных, чем MYCIN и EMYCIN, и увидим, каким образом сказывается обладание знаниями об используемых методах решения проблем на работе автоматизированных систем извлечения знаний.
Мы начали обсуждение методов решения проблем с эвристической классификации по той причине, что этот метод наиболее понятный. В следующих главах будут рассмотрены другие, более сложные методы, и вы сможете сравнить их.
Но в этой главе мы будем считать, что метод решения проблем выбран, а наша задача — проанализировать процесс выбора инструментальных средств для проектируемой экспертной системы и средств приобретения знаний.
Эвристическая классификация в системах MUD и MORE
12.2. Эвристическая классификация в системах MUD и MORE
В этом разделе мы проанализируем последствия применения методики анализа, предложенной Кленси, к процессу приобретения знаний. Сначала будет рассмотрена экспертная система MUD, которая ориентирована на решение задач геологоразведки, в частности бурения скважин. Эта система является хорошим примером весьма эффективного использования метода эвристической классификации. Затем для этой системы будет описан прототип системы извлечения знаний, названный MORE, в котором стратегия приобретения знаний связывается с используемыми методами решения проблем.
Как и в системе MYCIN, в MOD процесс приобретения знаний в основном ориентирован на установление отображения множества данных на множество решений. Однако в системе MYCIN другие виды знаний, например иерархические отношения между данными и абстрактными категориями решений, эвристики раскрытия пространства состояний и т.п., представлены в наборе правил только неявным образом. Подход, использованный при создании MUD и MORE, делает эти знания более явными, и в этом смысле существует определенное сходство между этими системами и системой OPAL (см. главу 10). И там, и здесь используется промежуточное представление, которое играет роль модели предметной области.
Модель предметной области выполнения буровых работ
Система MUD [Kahn and McDermott, 1984] предназначена для консультирования инженеров при проведении буровых работ на газонаполненных и текучих пластах. Основываясь на описании свойств пластов, система анализирует проблемы, возникающие при таком бурении, и предлагает способы их преодоления. Изменение свойств пластов, такое как внезапное увеличение вязкости в процессе бурения, может возникать вследствие самых различных факторов, например повышения температуры или давления или неправильной рецептуры смеси химических добавок.
Система MUD реализована с помощью языка описания порождающих правил OPS5 (предшественника CLIPS). Правила связывают изменения свойств пластов (абстрактные категории данных) с возможными причинами этих изменений (абстрактные категории решений). Ниже приведено одно из таких правил в переводе на "человеческий" язык.
ЕСЛИ:
(1) обнаружено уменьшение плотности пласта и
(2) обнаружено повышение вязкости,
ТО:
есть умеренные (7) основания предполагать, что имеется приток воды.
В формулировке таких правил числа в скобках — коэффициенты уверенности, которые при "сцеплении" правил комбинируются таким же способом, как и в системе MYCIN (подробнее об этом см. в главе 3). Таким образом, для того, чтобы определить достоверность предположения о проникновении воды, нужно принять во внимание все правила, которые "порождают" свидетельства за и против этой гипотезы. Мера доверия (или недоверия), связанная с каждым свидетельством, определяется способом, описанным в главе 9, а коэффициент уверенности в достоверности гипотезы является разностью между мерами доверия и недоверия.
Опыт, приобретенный Каном в процессе работы над этой системой, показал, что эксперты часто затрудняются сформулировать правила, приемлемые для подхода на основе эвристической классификации. Формат правила далеко не всегда соответствует способу мышления, привычному для экспертов, и способу обмена знаниями, принятыми в их среде. Определенные сложности вызывает и назначение коэффициентов уверенности в констатирующей части новых правил.
При этом обычно приходится пересматривать сформулированные ранее правила и сравнивать имеющиеся в них значения коэффициентов. Очень часто эксперты используют коэффициенты уверенности для частичного упорядочения в отношении определенного "заключения. Бучанан и Шортлифф [Buchanan and Shortliffe, 1984, Chapter 7] также отмечали, что экспертам иногда для правильной формулировки правил нужно располагать довольно подробной информацией о режиме применения правил и распространении значений коэффициентов уверенности в процессе их "сцепления".
При проектировании программ эвристической классификации, таких как MUD или MYCIN, процесс уточнения правил является, по существу, шестиэтапным.
(1) Эксперт сообщает инженеру по знаниям, какие правила нужно добавить или изменить.
(2) Инженер по знаниям вносит изменения в базу знаний системы.
(3) Инженер по знаниям запускает на выполнение программу, вводит данные, которые ранее уже обрабатывались прежним набором правил, и проверяет таким образом полноту нового набора.
(4) Если при обработке новым набором правил ранее проверенных исходных данных возникают какие-либо проблемы, инженер по знаниям обсуждает способы их преодоления с экспертом и далее повторяется этап 1.
(5) Эксперт запускает систему и вводит новый вариант данных.
(6) Если при обработке нового варианта не возникает никаких проблем, можно считать очередной сеанс внесения изменений в правила завершенным. В противном случае повторяется вся процедура начиная с 1-го этапа.
Как было показано в главе 10, именно такой базовый алгоритм внесения изменений в базу знаний используется в системе MYCIN, а для повышения эффективности выполнения отдельных этапов применяются разнообразные инструментальные средства, в частности язык сокращенного описания правил из состава оболочки EMYCIN, библиотека тестовых наборов данных, средства выполнения тестовых примеров в пакетном режиме и т.п.
Кан и его коллеги пошли по другому пути [Kahn et al, 1985], [Kahn, 1988]. Они применили программу извлечения знаний MORE, которая использует для обновления базы знаний MUD как знания о предметной области, так и знания о стратегии решения проблем.
Как и OPAL, программа MORE располагает моделью предметной области, в которой представлены основные отношения между базовыми концепциями. Эти знания используются для организации опроса экспертов, обнаружения ошибок при назначении коэффициентов доверия и для генерации правил, на основании которых выполняется эвристическая классификация.
В программе MORE модель предметной области состоит из следующих компонентов:
симптомы, т.е. явления, которые можно наблюдать в процессе проведения диагноза; появление этих явлений и должна объяснить система;
атрибуты, которые являются средством детализации симптомов, например резкое возрастание или снижение значения какого-либо параметра;
события, которые являются возможным следствием симптомов и таким образом могут рассматриваться в качестве гипотез;
фоновые условия, позволяющие судить о большей или меньшей вероятности наличия связи между обнаруженными симптомами и теми или иными гипотетическими причинами их появления;
тестовые процедуры, которые можно использовать для обнаружения наличия или отсутствия упомянутых выше фоновых условий;
условия выполнения тестовых процедур, способные повлиять на точность результатов тестирования.
Эти знания организованы в виде сети, в которой явно обозначены связи между симптомами и возможными причинами их появления, а также связи между условиями и теми состояниями или событиями, на которые эти условия могут повлиять. На рис. 12.1 представлен фрагмент сети представления модели предметной области, в которой используется система MUD.
Загрязнение сланцами и приток воды — это гипотезы, объясняющие появление четырех симптомов: понижение давления внутри пласта, повышение доли твердых включений, повышение уровня содержания неэмульсионной воды и повышение вязкости. Все они являются свойствами вязких и жидких пластов, на которых может сказаться загрязнение теми или иными компонентами при выполнении буровых работ. Обратите внимание, что на этой схеме некоторые линии причинно-следственных связей параметризиро-ваны степенью влияния на симптом. ТСМ— это тест синевы метилена, который проверяет повышение количества твердых включений в вязких пластах, а используется масляная эмульсия — фоновое условие, которое может сказаться на связи между притоком воды и повышением уровня содержания неэмульсионной воды.
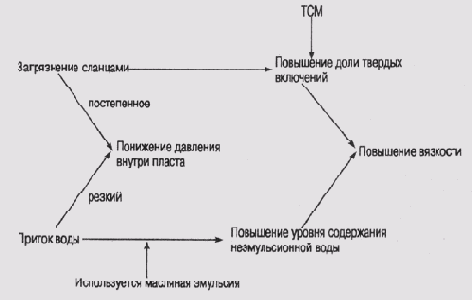
Рис. 12.1. Фрагмент модели предметной области, которая используется в программе MORE
12.1. Диагностические правила в М U D
Ниже приведены некоторые диагностические правила для той предметной области, на которую ориентирована система MUD. Правила, реализованные в виде программы на языке CLIPS, описывают те же причинно-следственные связи, что и на рис. 12.1. Если вы запустите эту программу на выполнение и ответите на оба вопроса утвердительно, то программа придет к заключению, что возможны два варианта объяснения наличия указанных симптомов— и загрязнение сланцами, и приток воды. Если на один из вопросов ответить отрицательно, то программа отдаст предпочтение одной из гипотез.
;; ШАБЛОНЫ (deftamplate symptom
(field datum (type SYMBOL))
(field change (type SYMBOL))
(field degree (type SYMBOL) (default NIL))
)
(deftamplate hypothesis
(field object (type SYMBOL))
(field event (type SYMBOL))
(field status (type SYMBOL) (default NIL))
(deftemplate testing
(field name (type SYMBOL))
(field for (type SYMBOL))
(field status (type SYMBOL) (default NIL)) )
;; ФАКТЫ
(deffacts mud
a(symptom (datum viscosity)
(change increase))
(symptom (datum density)
(change decrease) (degree gradual))
(testing (name МВТ)
(for low-SG-solids))
(testing (name oil-mud)
(for unemulsified-water))
)
;; ПРАВИЛА
;; Правило обратного вывода, принимающее во внимание
;; вязкость (viscosity).
(defrule viscosity (symptom
(datum viscosity) (change increase))
=>
(assert (hypothesis (object low-SG-water)
(event increase))) (assert (hypothesis
(object unemulsified-water) (event increase)))
)
;; Правила обратного вывода, принимающие во внимание
;; плотность (density). (defrule density :
(symptom (datum density)
(change decrease) (degree gradual))
=>
(assert (hypothesis (object shale)
(event contamination)))
)
(defrule density
(symptom (datum density) (change decrease)
(degree rapid)) =>
(assert (hypothesis (object water) (event influx»)
)
;; Свидетельства в пользу загрязнения сланцами
(shale contamination) (defrule shale ?effect
<- (hypothesis (object low-SG-water)
(event increase)
(status yes)) => (assert (hypothesis
(object shale) (event contamination)
(status yes)))
(modify ?effect (status done)) )
;; Свидетельства в пользу притока воды (water influx)
(defrule water ?effect <- (hypothesis
(object unemulsified-water)
(event increase) (status yes)) =>
(assert (hypothesis (object water)
(event influx)
(status yes))) (modify ?effect
(status done))
)
;; Поиск теста гипотезы (defrule peek-test
(hypothesis (object ?obj) (event ? change))
?operator <- (testing (name ?name)
(for ?obj) (status NIL)) =>
(printout
t crlf
"Is there " ?obj " " ?change " according to the "
?name " test? "
;; "Существует " ?obj " " ?change " в соответствии с " ,
;; " тестом " ?name " ? "
) ;; (modify ?operator (status (read)))
)
;; Применить результат теста к гипотезе.
{defrule poke-test
?cause <- (hypothesis (object ?obj)
(event ?change))
?operator <- (testing (name ?name)
(for ?obj) (status yes))
=>
(modify ?cause (status yes)
(modify ?operator (status done))
)
; ; Вывести активную гипотезу.
(defrule show-and-tell
(hypothesis (object ?obj)
(event ?ev) (status yes))
=>
(printout
t crlf
?obj " " ?ev "is a possibility. " t crlf
;; ?obj " " ?ev " является вероятной. "
)
Опыт эксплуатации системы MORE
В одной из своих ранних работ, посвященных созданию системы MYCIN, Шортлифф обратил внимание на необходимость разработки такого механизма извлечения знаний, который помогал бы эксперту назначать порождающим правилам коэффициенты уверенности [Shortliffe, 1976]. В сборнике [Buchanan and Shortliffe, 1984, Chapter 10, Section 5] собрано множество статей, в которых обсуждается ряд вопросов, связанных с этой проблемой. В этих статьях, в частности, обсуждается, как добавлять новые правила в существующий набор и как модифицировать ранее сформулированные правила.
Тот подход, который использован в программе MORE, достаточно прозрачен и понятен. Но в этой программе совершенно не затрагивается вопрос о независимости значений коэффициентов, который был в свое время поднят Шортлиффом. В главе 6 мы видели, что применение теоремы Байеса требует, чтобы свидетельства в пользу гипотез были независимыми, если мы собираемся комбинировать их параметры с помощью простой мультипликативной схемы.
Шортлифф предложил сгруппировать зависимые свидетельства в одном правиле, а не распределять их по множеству и рассматривать такую группу свидетельств в качестве "суперсимптома". Оценку весомости этого суперсимптома можно сделать на основе аппроксимации конъюнкции весов индивидуальных свидетельств. В программе MORE это предложение не реализовано, но в ней имеется вся необходимая для этого информация, представленная в модели событий. Анализ функционирования системы подтвердил предположение, что при нарушении независимости свидетельств коэффициенты уверенности отклоняются в значительно большем диапазоне, чем вероятности (см. об этом в [Buchanan and Shortliffe, 1984, Chapter 11, Section 5]).
Кан обратил внимание на другие проблемы, обнаруженные при эксплуатации прототипа системы MORE.
Пользователи предпочли бы, чтобы программа MORE использовала каким-то образом модель событий для формирования предположительных значений коэффициентов и задавала меньше вопросов общего характера.
Такие концептуальные понятия, как гипотезы и симптомы, с трудом воспринимаются экспертами в большинстве предметных областей, связанных с промышленным производством, чьи знания очень важны для систем, ориентированных на диагностику неисправностей.
Стандартный алфавитно-цифровой интерфейс общения эксперта с системой показал свою полную непригодность даже для выполнения экспериментов с прототипом системы.
Последнее замечание еще раз подтверждает важность хорошо продуманного и удобного интерфейса для успешного внедрения экспертной системы. До тех пор, пока пользователь будет лишен возможности легко интерпретировать то, что он видит на экране, быстро отыскивать необходимую ему информацию, он не сможет понять, что именно делает система.
Привычный для всех современных пользователей графический интерфейс значительно повышает производительность работы с системой на всех стадиях ее развития.
Другой ряд проблем связан с тем, что программа MORE реализована на языке OPS5, а модель событий описывается в терминах сложных векторов, размещаемых в рабочей памяти. Такое представление плохо подходит для представления знаний о причинно-следственных отношениях, а потому при описании, модификации и сопровождении модели событий разработчикам пришлось столкнуться с большими сложностями. Здесь скорее подошло бы представление в виде структурированных объектов, которое было описано в главе 6.
За время, прошедшее после создания программы MORE, на свет появилось еще множество других программ извлечения знаний для последующего использования в экспертных системах, выполняющих эвристическую классификацию. Одна из таких программ — TDE — будет представлена в следующей главе.
Рекомендуемая литература
В дополнение к системам, описанным в этой главе, читателям рекомендуется познакомиться с системой MOLE [Eshelman and McDermott, 1986], [Eshelman et al., 1987], [Eshelman, 1988]. Это интересная оболочка для построения экспертных систем, решающих проблему классификации. Она более интеллектуальная, а следовательно, и более сложная для понимания, чем MORE, а потому мы не рассматривали ее в данной книге. Особенностью этой системы является разделение между категориями накрывающих знаний {covering knowledge) — знаний, относящихся к сопоставлению данных и гипотез, и дифференцирующих знаний (differentiating knowledge) — знаний, которые позволяют сделать выбор между конкурирующими гипотезами. Это разделение используется для структурирования процесса извлечения знаний и уточнения сформированной базы знаний.
Подробное обсуждение вопросов эвристической классификации и эпистемологического анализа в системах, основанных на правилах, можно найти в работах [Clancey, 1993,а] к [Clancey, 1993,b].
Совершенствование стратегий
Работа инженера по знаниям отнюдь не заканчивается после того, как эвристические знания будут представлены в виде исходного набора порождающих правил. И исследователи, и практики давно пришли к выводу, что процесс дальнейшего совершенствования базы знаний не уступает по сложности процессу создания ее первой версии. Существует довольно большой круг проблем, связанных как с обслуживанием большого набора правил, так и с дальнейшим уточнением их на базе опыта, полученного в процессе эксплуатации системы.
Только часть из этих проблем может быть решена с помощью таких инструментальных средств извлечения знаний, как система MORE. Создается впечатление, что некоторые аспекты этих проблем являются следствием применения подхода, базирующегося на правилах, а потому требуется определенное переосмысление способов организации набора правил. В этом разделе мы попытаемся провести краткий обзор существующих на сегодняшний день мнений на этот счет.
Стратегии приобретения знаний
12.2.2. Стратегии приобретения знаний
Кан и его коллеги атаковали проблему извлечения знаний с двух направлений. С одной стороны, в процессе проектирования системы MUD они совершенствовали методику опроса экспертов инженерами по знаниям. С другой стороны — проанализировали используемую методику в терминах метода решения проблем с помощью эвристической классификации, который используется в MUD. В результате были выделены восемь вариантов стратегий извлечения знаний, которые перечислены ниже. Каждый из вариантов стратегии используется программой MORE для подтверждения или опровержения гипотез в процессе диагностирования.
Дифференциация. Поиск симптомов, позволяющих разделить гипотезы, например симптомов, которые могут иметь единственную причину. Такое взаимно однозначное соответствие между симптомом и явлением, его вызвавшим, в медицинской литературе называется патогенетической (pathognomic) ассоциацией.
Частотное упорядочение условий. Определение тех фоновых условий, которые влияют на степень правдоподобности конкретных гипотез. Если подходить к задачам диагноза с точки зрения теории принятия решения, то степень поддержки конкретной гипотезы об источнике неисправности, которую вносит определенное свидетельство (симптом), зависит от априорной вероятности этой неисправности.
Отчетливость симптомов. Идентификация тех свойств симптомов, которые могут являться индикаторами лежащих в глубине причин появления этих симптомов. Так, в схеме на рис. 12.1 видно, что резкое повышение плотности пласта является довольно отчетливым индикатором наличия притока воды.
Установление связи между симптомами и условиями. Отыскание таких условий, при которых можно рассчитывать на то, что разные симптомы проявятся сами по себе при данной неисправности. Такие ожидания могут служить для опровержения гипотез, если они не получили подтверждения.
Разделение пути. Попытка найти такие промежуточные события между гипотезами о причинах неисправности и вероятными симптомами, которые имеют более высокую условную вероятность, чем сами симптомы.
Если такие промежуточные события не фиксируются в процессе диагностирования, то это может служить более серьезным доводом против данной гипотезы, чем отсутствие симптома.
Дифференциация путей. Как и в случае разделения пути, анализируется "траектория" причинно-следственных связей между симптомами и неисправностями. В процессе этого анализа стараются выявить такие промежуточные события, которые позволят провести разделение неисправностей, имеющих одинаковые симптомы.
Дифференциация тестирования. Определение степени доверия к результатам тестирования. Свидетельство, как правило, является результатом тестирования, а последнее может быть охарактеризовано различными значениями степени достоверности.
Установление связи между тестированием и условиями его проведения. Определение фоновых условий, которые могут сказаться на степени достоверности результатов тестирования. Такая информация влияет на оценку результатов текущих наблюдений для анализируемого случая.
Извлечение знаний с помощью программы MORE начинается с получения от эксперта знаний о базовых неисправностях (патологиях) и связанных с ними симптомах. Затем программа избирательно активизирует указанные выше стратегии приобретения знаний, базируясь на тех знаниях, которые приобретены на предыдущих стадиях. Чтобы понять механизм выбора стратегий, рассмотрим процесс приобретения знаний с помощью MORE более подробно.
В той предметной области, на которую ориентирована программа MORE, существуют три типа порождающих правил.
Диагностические правила описывают соответствие между симптомами и гипотезами. Правила такого типа имеются во многих экспертных системах — MYCIN, ONCOCIN, MUD и т.п.
Правила оценки степени достоверности симптомов. С помощью этих правил выполняется неявная качественная оценка абстрактных категорий данных в пространстве симптомов, которая опирается на уровень достоверности результатов тестирования при различных фоновых условиях.
Правила оценки степени правдоподобности гипотез позволяют провести неявную качественную оценку абстрактных категорий решений в пространстве гипотез.
При этом оценивается априорная вероятность гипотез при различных фоновых условиях.
Отличительной чертой диагностических правил, которые используются в системе MUD, является наличие двух коэффициентов доверия — положительного и отрицательного. Положительный коэффициент отображает степень поддержки заключения данным правилом при соблюдении сформулированных в нем условий, а отрицательный— степень "опровержения" заключения данным правилом, если сформулированные в правиле условия не соблюдаются. В правилах, относящихся к двум другим группам, используется только один коэффициент. В правилах оценки степени достоверности симптомов значение коэффициента несет информацию об изменении степени достоверности определенного симптома, которое вносится данным правилом. В правилах оценки степени правдоподобности гипотез значение коэффициента определяет изменение степени правдоподобия гипотезы, которое вносится при выполнении условий, специфицированных в данном правиле.
Программа MORE работает с двумя видами моделей — моделью событий и моделью правил. Модель событий охватывает симптомы, гипотезы и условия и связи между ними, как показано на рис. 12.1. В MORE это представление используется для формирования порождающих правил, в отличие от программы OPAL, в которой правила формируются на основании модели предметной области.
Если быть точным, то программа MORE генерирует целое семейство диагностических правил по одному на каждую гипотезу. Например, прямо из модели событий MUD программа MORE может сформировать следующее диагностическое правило:
[Правило 1]
ЕСЛИ обнаружено повышение уровня хлоридов,
ТО существует солевое загрязнение.
Но это правило является слишком общим. Ему нужно дать качественную оценку, например с помощью стратегии отчетливости симптомов. Эта оценка позволит учесть эффект влияния фоновых условий на степень важности симптома. Таким образом, в семейство правил солевое загрязнение может быть добавлено следующее правило:
[Правило 2]
ЕСЛИ обнаружено повышение уровня хлоридов и пласт недостаточно насыщен,
ТО существует солевое загрязнение.
Программа MORE работает с семействами правил следующим образом. Когда программа "изучает" новые условия, имеющие отношение к некоторой гипотезе, она создает новое правило с единственным условием в левой части и добавляет его в семейство правил этой гипотезы. Если же новое условие имеет отношение и к другим правилам, ранее включенным в это же семейство, то в них также добавляется это условие. (Если новое условие не совместимо с другими, указанными в одном из правил семейства, то такое правило не изменяется.) Правила, в которые добавляется новое условие, называются составными правилами (constituent rules). О них мы поговорим в следующем разделе, когда будем рассматривать коэффициенты уверенности.
Приведенный пример применения стратегии отчетливости симптомов показывает, как с помощью той или иной стратегии извлечения знаний выполняется уточнение сформулированных правил. Стратегия отчетливости симптомов используется тогда, когда в семействе не оказывается правил с отчетливо выраженным положительным коэффициентом доверия. Приведенное выше исходное правило было слишком общим, а потому ему нельзя было назначить высокий коэффициент доверия. Поскольку на начальном этапе это правило является единственным в семействе, для его уточнения и активизируется стратегия отчетливости симптомов. Чаще всего, после того как формулируются другие правила семейства, в которых специфицируются различные фоновые условия, такие общие правила удаляются из семейства. Такое удаление можно рассматривать как стремление отдавать предпочтение специализированным правилам, а не более общим, на чем основаны некоторые стратегии разрешения конфликтов.
Стратегия установление связи между симптомами и условиями используется в том случае, если в семействе отсутствуют правила с отчетливо выраженным отрицательным коэффициентом доверия. В таких случаях программа MORE предпринимает попытку выявить те фоновые условия, которые позволяют более отчетливо проявиться симптому какой-либо определенной гипотезы.
Знание условий, при которых повышается вероятность проявления симптома, позволяет компоненту решения задач отбрасывать часть гипотез, для которых наиболее показательные симптомы отсутствуют.
Другие стратегии — дифференциация, дифференциация путей и разделение пути — используются для создания новых семейств правил. Стратегия дифференциации задейст-вуется в тех случаях, когда программа обнаруживает пару гипотез, не имеющих отличающихся симптомов. В этом случае на схеме модели событий, аналогичной приведенной на рис. 12.1, возникает ситуация, когда для пары гипотез Н1 и H2 не оказывается ни одного симптома, который имел бы связь с Н1 но не имел связи с H2, или наоборот. Используя стратегию дифференциации, программа MORE пытается выяснить у эксперта, какой еще симптом можно добавить в набор и с его помощью устранить неоднозначность. Этот новый симптом добавляется затем в модель событий и связывается с определенными гипотезами. Таким образом модель уточняется до тех пор, пока не появится возможность сформировать отдельные семейства правил для гипотез Н1 и H2
Стратегия дифференциации путей выбирается в том случае, если в модели событий некоторый симптом оказывается связан с двумя разными гипотезами. В этой ситуации программа MORE пытается выяснить у эксперта, существует ли какое-либо промежуточное событие, которое, с одной стороны, может послужить причиной появления такого симптома, а с другой, может возникнуть только в том случае, когда правдоподобна одна из "конкурирующих" гипотез и неправдоподобна другая. Включение такого события в модель поможет разделить существующие объяснения появления такого симптома, а соответственно и уточнить связанные с ними правила.
К стратегии разделения пути программа обращается в том случае, если в семействе правил некоторой гипотезы обнаруживается отсутствие правила, которое связало бы высокое значение отрицательного коэффициента доверия с отсутствием какого-либо симптома. В этой ситуации программа MORE пытается выяснить у эксперта, существует ли какое-либо промежуточное событие, причиной которого могла бы быть данная гипотеза.
Если такое событие существует, то тот факт, что оно не наблюдается, может с большей очевидностью свидетельствовать против данной гипотезы, чем тот факт, что симптом не наблюдается. В результате можно создать новое семейство правил для гипотезы.
Остальные стратегии — частотное упорядочение условий, дифференциация тестирования и установление связи между тестированием и условиями его проведения — активизируются в случаях, когда в семействе обнаруживается отсутствие правил с достаточно высоким или достаточно низким значением положительного или отрицательного коэффициента доверия. В таком случае правила нельзя считать достаточно информативными для решения проблемы классификации. Получение от эксперта информации о новых тестовых процедурах и условиях их выполнения, а также оценок априорной вероятности гипотез при различных фоновых условиях позволит либо увеличить, либо уменьшить коэффициенты в правилах, связывающих симптомы и гипотезы. Информация первого типа используется для корректировки правил оценки степени достоверности симптомов, а информация второго типа — для корректировки правил оценки степени правдоподобности гипотез.
Структурзадач в системе NEOMYCIN
Опыт, полученный в ходе работы над системой GUIDON, был использован Кленси при разработке более сложной модели выполнения диагностирования, которая получила название NEOMYCIN. При создании базы медицинских знаний для этой консультационной системы была использована доработанная обучающая программа GUIDON2. Главные отличия системы NEOMYCIN от MYCIN состоят в следующем.
Использованная в системе процедура вывода суждений наиболее четко отделена от содержимого порождающих правил, как об этом было сказано в предыдущем разделе при описании программы GUIDON.
Процедура вывода суждений может использовать как прямую, так и обратную цепочку логического вывода.
Таким образом, поток данных и управляющей информации в программе NEOMYCIN в большей степени независим от порождающих правил и механизма их интерпретации, чем в системе MYCIN, которая тратила большую часть рабочего времени на выполнение исчерпывающего нисходящего поиска. MYCIN задавала пользователю вопросы и собирала необходимую информацию в том случае, когда не находила такого правила, которое можно было бы применить для формирования заключения, связанного с некоторым фактом. В этом смысле MYCIN очень напоминала те системы логического программирования, в которых использовалась технология "спроси у пользователя". Работая с пользователем в интерактивном режиме, программа накапливала факты, недостающие для выполнения доказательства. Процесс функционирования NEOMYCIN, напротив, лучше всего может быть представлен как обработка множества разнообразных гипотез и тестов, среди которых отыскивается наиболее предпочтительная гипотеза и сравнивается с конкурентами. Следовательно, вопросы, которые система задает пользователю, диктуются желанием выбрать между альтернативными предложениями, а не просто собрать факты для проведения единственной линии суждений, которая может завершиться успехом или неудачей.
Кленси утверждает, что поведение NEOMICYN ближе к модели поведения человека при диагностировании, чем поведение MYCIN.
Например, клиницисты обычно стараются определить диапазон возможных заболеваний, которыми может страдать пациент, на основе ограниченного набора анализов. По Кленси такое поведение можно рассматривать как стремление "ограничить пространство гипотез". Одна из стратегий, используемых для этого, называется "сгруппируй и раздели", т.е. задавшись какой-либо начальной гипотезой, правдоподобной при имеющихся данных, врач сначала пытается собрать все другие гипотезы, учитывающие те же признаки и симптомы, а затем разделить их на те, которые подходят к данному случаю, и те, которые должны быть отброшены.
Стратегия диагностирования в системе NEOMYCIN может быть представлена в виде дерева задач, в котором задачей верхнего уровня является КОНСУЛЬТАЦИЯ, в которую в виде подзадач входят ИДЕНТИФИКАЦИЯ ПРОБЛЕМЫ и СБОР ИНФОРМАЦИИ. Именно эта иерархия задач определяет направление потока управления, а не неявная иерархия концептуальных правил, прослеживаемая с помощью методики построения обратной цепочки рассуждений. В дополнение к задаче "сгруппируй и раздели" существуют еще две стратегии, которые помогают сформировать пространство гипотез: "попробуй и уточни" и "задай обобщенные вопросы". Первая предполагает достаточно детальное исследование определенной гипотезы, а вторая служит для сбора фоновой информации (например, можно запросить у пользователя, не беременна ли пациентка, не перенес ли пациент недавно хирургическую операцию).
Обеим задачам — и "сгруппируй и раздели", и "попробуй и уточни" — отводится свое место в контексте сложной иерархии патологий. Стратегия "сгруппируй и раздели" включает анализ той части иерархии, которая находится выше первоначальной гипотезы, и таким образом предпринимается попытка отыскать в этой части конкурирующие гипотезы. Стратегия "попробуй и уточни" включает анализ той части иерархии, которая находится ниже первоначальной гипотезы, и таким образом предпринимается попытка дальнейшего уточнения диагноза.
В следующей главе мы проанализируем весь процесс формирования гипотез и их тестирования в иерархии альтернатив. Здесь же важно обратить внимание на принцип представления в программе стратегии формирования логического вывода явно в структуре задач. Те результаты, которые получил Кленси при разработке конкретной интеллектуальной обучающей системы, могут быть с успехом распространены и на весь класс экспертных систем.
Независимо от того, всеми ли будет одобрена предложенная Кленси методика анализа, можно с уверенностью заявить, что она открыла новые направления в исследованиях в области экспертных систем. Точно так же, как задачи, выполняемые экспертными системами, нуждаются в той или иной форме онтологического анализа, который помогает систематизировать объекты и отношения между ними в конкретной предметной области, они нуждаются и в эпистемологическом анализе видов знаний о способах решения проблем в этой области, которыми обладает эксперт. Эти знания в совокупности со знаниями о том, на какой стадии процесса логического вывода их следует применять, как правило, слишком обширны. Поэтому для их представления недостаточно какого-то одно формализма (например, порождающих правил) и одного режима управления (например, построения обратной цепочки вывода).
Один из подходов к построению экспертных систем (как, впрочем, и любых других программ) — спросить себя, как распределить "сложность" между компонентами проекта. Существуют два крайних варианта — спроектировать конструкцию с достаточно богатыми возможностями, которую можно было бы относительно легко реализовать, или спроектировать простую конструкцию, но сосредоточить главные усилия на стадии кодирования. Это пример реализации принципа "бесплатных ленчей не бывает" в отношении программного обеспечения. Ресурсы, сэкономленные на одном уровне, непременно придется растратить на другом.
в системах, основанных на правилах,
1. Почему в системах, основанных на правилах, сложно выполнять обратное прослеживание на большую глубину?
2. Перечислите шесть основных этапов проектирования систем, основанных на знаниях.
3. В чем разница между стратегиями частотного упорядочения условий и установления связи между симптомами и условиями в системе MORE?
4. Говорят, что правила ожидаемости гипотез в системе MORE "неявно квалифицируют абстрактные категории решений в пространстве гипотез". Что под этим понимается?
5. В чем заключается значение фоновых условий в модели, используемой в MORE?
6. В чем состоит отличие между моделями событий и правил в системе MORE?
7. Какая ошибка допущена при назначении коэффициентов уверенности на схеме модели событий, представленной на рис. 12.4? На этой схеме D — это неисправность, а
S1,S2 и S3 -СИМПТОМЫ.
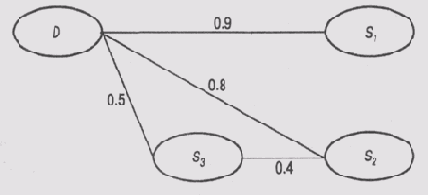
Рис. 12.4. Модель событий
8. Какая ошибка допущена при назначении коэффициентов уверенности на схеме модели событий, представленной на рис. 12.5? На этой схеме Di — это неисправности, а Si — симптомы.
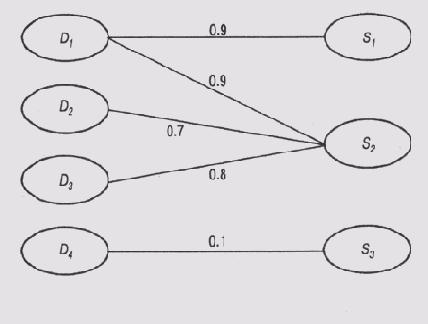
Рис. 12.5. Модель событий
9. Рассмотрите CLIPS-программу, представленную во врезке 12.1.
I) Добавьте в программу новые правила, соответствующие представленным ниже
IF: there is an increase in chlorides, and
the drilling fluid is undersaturated, THEN: there is salt contamination.
IF: there is salt contamination
THEN: there is an increase in viscosity.
ЕСЛИ: обнаружено повышение уровня хлоридов и
пласт недостаточно насыщен, ТО: существует солевое загрязнение.
ЕСЛИ: существует солевое загрязнение,
ТО: повышается вязкость.
II) Назначьте значения коэффициентов уверенности дугам, соединяющим узлы на схеме рис. 12.1. Включите также коэффициенты, связывающие процедуры анализа и результаты проведения анализа. При установке значений коэффициентов соблюдайте ограничения, описанные в разделе 12.2.3. Значения всех коэффициентов могут быть положительными.
III) После этого измените определения шаблонов в тексте программы таким образом, чтобы и гипотезы, и тесты имели соответствующие атрибуты.
IV) Измените в программе правила таким образом, чтобы в них был реализован механизм распространения коэффициентов уверенности по мере формирования гипотез и выполнения тестирующих процедур. Комбинирование коэффициентов должно выполняться в соответствии с формулой
Z = X+Y-XY,
где Z— новое значение коэффициента уверенности, полученного на основании значений X и Y, связанных с симптомами. Таким образом, если программа приходит к заключению increase in low-specific-gravity solids (повышение доли твердых включений) исходя из симптома increase in viscosity (повышение вязкости), который характеризуется коэффициентом уверенности X, и результатов теста МВТ (тест синевы метилена), которые характеризуются коэффициентом Y, то с помощью приведенной выше формулы можно получить значение коэффициента Z, характеризующее степень достоверности заключения.
V) Запустите программу на выполнение и проверьте, как она будет реагировать на разные варианты ответов на вопросы.
10. Приведенная ниже модель диагностики взята из руководства владельца автомобиля BMW 320.
I) Представьте приведенные ниже инструкции по поиску неисправностей в виде модели предметной области, которая используется в системе MORE (см. рис. 12.1).
Симптом |
Причины |
||
Двигатель не заводится |
|||
На стартер не подается ток |
Разряжена аккумуляторная батарея |
||
Поврежден провод, подключенный к одной из клемм батареи |
|||
Поврежден соленоид стартера |
|||
Плохой контакт с "массой" |
|||
На стартер подается ток |
Заклинило шестерню стартера |
||
Поврежден двигатель стартера |
|||
Двигатель проворачивается, |
но не запускается |
||
Нет искры между электродами свечи |
Загрязнены контакты прерывателя Наличие влаги в распределителе |
||
Неправильно подключены контакты прерывателя |
|||
Поврежден конденсатор (модель прежних лет выпуска) |
|||
Поврежден ключ прерывателя |
|||
Повреждена катушка (модель прежних лет выпуска) |
|||
Нет топлива в жиклере карбюратора |
Нет топлива в баке Паровая пробка в системе подачи топлива |
||
(в жаркое время года) |
|||
Засорен жиклер |
|||
Неисправен бензонасос |
|||
Двигатель заглох и вновь не |
заводится |
||
Заливает карбюратор |
Заедание игольчатого клапана |
||
Поврежден поплавок |
|||
Неправильно установлен уровень поплавка |
|||
Нет топлива в жиклере карбюратора |
Нет топлива в баке Вода попала в систему подачи топлива |
||
Замечания в круглых скобках в столбце "Причины" следует рассматривать как фоновые условия в системе MORE.
II) Постройте на основе этой инструкции набор порождающих правил и разработайте соответствующую CLIPS-программу. Фоновые условия должны вводиться пользователем в ответ на запросы программы.
Уроки проектGUIDON
В своей работе [Clancey, 1983] Кленси раскритиковал использование неструктурированного набора порождающих правил в экспертных системах, основываясь в основном на опыте адаптации системы MYCIN для учебных целей в ходе выполнения проекта GUIDON. Описание этого проекта можно найти в работе [Clancey, 1987, а]. Главный аргумент Кленси состоит в том, что единообразный синтаксис правил в виде выражений "если... то" скрывает тот факт, что такие правила часто выполняют совершенно различные функции и соответственно должны конструироваться по-разному. При нынешней постановке вопроса определенные структурные и стратегические решения, касающиеся представления знаний о предметной области, присутствуют в наборе правил неявно, а потому недоступны для коррекции или анализа в явном виде.
Мы уже видели, что порождающие правила в обобщенной форме могут быть интерпретированы следующим образом: если предпосылки Р1 и ... и Рт верны, то выполнить действия Q1 и ... и Qn
Порядок перечисления предпосылок Рi не имеет значения, поскольку Р1 ^ P2 эквивалентно P2^P1 в любой стандартной логике. Однако порядок перечисления предпосылок влияет на процедурную интерпретацию таких правил, поскольку он материализуется в логическом программировании. Различные варианты упорядочения в совокупности могут породить совершенно различные виды пространства поиска, которые будут анализироваться по-разному, как мы это уже видели в главе 8. Аналогично, порядок применения правил для достижения определенной цели будет влиять на порядок формирования подцелей. Можно с уверенностью утверждать, что такой механизм разрешения конфликтов, при котором первыми будут выполняться наиболее предпочтительные правила, в большинстве случаев позволит намного сократить процесс поиска.
Проблема состоит в том, что критерии, по которым можно было бы упорядочить правила и логические фразы, представлены в наборе правил в неявном виде. Знания о том, какое правило следует применить первым и в каком порядке анализировать члены совокупности предпосылок в правиле, являются, по существу, метазнаниями, т.е.
знаниями о том, как применять знания. Вряд ли кто-нибудь будет спорить с тем, что такие знания имеют важнейшее значение для правильного функционирования экспертной системы, а получить их от эксперта и представить в удобном виде в программе чрезвычайно трудно.
Кленси утверждал, что система, основанная на правилах, нуждается в эпистемологической оболочке, которая каким-то образом придает смысл специфическим знаниям о предметной области. Другими словами, правила логического вывода, имеющие отношение к определенной предметной области, часто оказываются неявно включены в более абстрактные знания. Лучший способ объяснить эту мысль -- воспользоваться примером, описанным Кленси. Рассмотрим следующее правило:
ЕСЛИ: 1) заражение — менингит,
2) доступны только косвенные свидетельства,
3) тип инфекции — бактериальный,
4) пациент принимает кортикостероиды,
ТО: имеются основания предполагать наличие таких микроорганизмов e.coli (.4)
klebsiella-pneumoniae (.2) или pseudomonas-aeruginosa (.1).
Порядок перечисления предпосылок (конъюнктов) в этом правиле исключительно важен. Обычно стараются сначала сформулировать гипотезу относительно природы инфекции (предпосылка 1), а затем решать, являются ли свидетельства, относящиеся к этой гипотезе, косвенными или нет (предпосылка 2). Бактериальный менингит— это подкласс, отличный от вирусного менингита, и, следовательно, предпосылку 3 можно рассматривать как уточнение предпосылки 1. И наконец, решение отложить проверку предпосылки 4 можно, вероятно, отнести к категории стратегических. Если сделать эту последнюю предпосылку первой в правиле, то пространство поиска будет иметь совершенно другой вид, причем возможным следствием такого изменения будет отбрасывание всех последующих проверок, если эта даст отрицательный результат.
Процесс представления знаний приводит к тому, что знания становятся явными, но порождающие системы оставляют множество общих принципов управления поиском представленными в неявном виде. Возможно, этим и объясняется тот факт, что добавление или удаление правил из существующего набора иногда дает совершенно неожиданный эффект.
Декларативная интерпретация правил на "человеческом" языке подводит нас к одному выводу, а процедурная интерпретация этих же правил в системе может дать совершенно иной результат.
Кленси предложил довольно привлекательную методику анализа разных видов знаний, выполнение которого может быть возложено на эпистемологическую оболочку системы, основанной на правилах. Предлагается выделить такие компоненты знаний: структурные, стратегические и поддерживающие.
Структурные знания состоят из абстрактных категорий разных уровней, посредством которых представляются знания о предметной области. Таксономия — это, возможно, один из самых очевидных примеров источника таких знаний, которые обычно явно представляются в виде порождающих правил. Знание, что менингит — это заражение, которое может быть острым либо хроническим, бактериальным или вирусным и т.д., неявно представляется в предпосылках многих правил.
Стратегические знания — это знания о том, как выбрать порядок применения методов или выбора подцелей, который минимизировал бы объем работы, необходимый для поиска' в пространстве решений. Например, правило, которое гласит, что пациент, склонный к определенной патологии (например, алкоголик), может с большей вероятностью иметь необычную этиологию, должно побудить эксперта первым делом обратить внимание на менее обычные причины заражения. Такие знания обычно используются в сочетании со структурными знаниями. Например, такая эвристика может быть связана скорее с бактериальным менингитом, чем с вирусным.
Поддерживающие знания — - это знания, которые содержатся в причинно-следственной модели предметной области и которые объясняют, почему в этой предметной области имеют место определенные необычные явления. Так, в системе MYCIN имеется правило, которое связывает употребление стероидов с наличием грамотрицательных микроорганизмов в форме палочек, которые могут вызвать бактериальный менингит. В основе этого правила лежит тот факт, что стероиды ослабляют иммунную систему.К тому же такие знания увязываются со структурными знаниями, касающимися классификации заболеваний и классификации микроорганизмов.
Очевидно, что большая часть таких фундаментальных знаний не представлена в явном виде в порождающих правилах. Структурные знания лучше всего представляются в форме составных объектов данных, таких как фреймы, но некоторая часть управляющей информации может быть представлена в процедурном виде. Поддерживающие знания, как правило, включаются в сопроводительную документацию к программе, но они должны быть доступны и для программы, формирующей объяснения сделанных заключений. Попытка "втиснуть" разнородные знания в единый формат представления отрицательно сказывается на ясности и прозрачности системы для пользователя, но, тем не менее, позволяет весьма изобретательно использовать эффект от рационального выбора способа упорядочения правил и предпосылок.
Эвристическая классификация (I)
11.1. Классификация задач экспертных систем
11.2. Классификация методов решения проблем
11.3. Классификация или конструирование?
Рекомендуемая литература
Упражнения
В предыдущей главе мы уже упоминали о том, что базовые компоненты экспертных систем, хорошо зарекомендовавшие себя на практике (машина логического вывода и подсистема представления знаний), могут быть использованы для построения аналогичных систем для других областей приложения. Так, архитектура оболочки EMYCIN явилась результатом дальнейшего развития принципов, положенных в основу ранней и узкоспециализированной системы MYCIN.
В этой главе мы рассмотрим вопросы применения тех методов решения проблем, которые используются на практике при построении экспертных систем разного назначения, и постараемся увязать характерные черты этих методов со спецификой областей применения. В идеальном случае хотелось бы получить ответы на следующие вопросы.
Можно ли классифицировать области применения экспертных систем на основе характеристик задач, решаемых в этой области?
Можно ли сформулировать хорошо дифференцированный набор методов решения проблем, которые приложимы для определенных классов областей применения?
Можно ли определить, какие стили представления знаний и правил логического вывода наиболее подходят для данного метода решения проблем?
Мы попытаемся дать ответы на эти вопросы, основываясь на том опыте построения экспертных систем, который накопило научное сообщество на сегодняшний день. Не следует ожидать, что эти ответы будут обладать исчерпывающей полнотой и четкой аргументацией, но, тем не менее, они представляют большой интерес как в теоретическом, так и в практическом плане. Если уж технология экспертных систем должна иметь солидный теоретический базис, то необходимо представлять себе, почему эта технология оказывается работоспособной при решении одних задач и неработоспособной при решении других. С практической точки зрения ответы на поставленные вопросы помогут разработчикам экспертных систем принять правильное решение и таким образом избавят их от крушения надежд и разочарования, которыми часто сопровождается ошибочный выбор.
В этой главе читатель найдет следующий материал.
Сначала будет представлен критический обзор подходов к классификации задач экспертных систем, описанных в технической литературе.
Затем мы рассмотрим те методы решения проблем, которые в литературе объединены под общим названием эвристической классификации. Этим термином принято характеризовать поведение множества экспертных систем, ориентированных на выполнение таких задач, как диагноз и интерпретация данных.
В последних разделах будет проведено сравнение эвристической классификации с другими методами, пригодными для решения задач, оказавшихся не под силу эвристической классификации.
Противопоставление различных подходов, рассмотренное в заключительном разделе, в дальнейшем будет описано при более глубоком анализе различных методов в главах 12-15. В качестве примеров применения таких методов мы выбирали экспертные системы различного назначения, достаточно подробно описанные в литературе. Пользуясь такой методикой изложения, мы постараемся отыскать те более или менее общие схемы представления знаний и механизмы логического вывода, которые целесообразно применять для конкретных типов задач. В главах 18, 22 и 23 мы остановимся на более "экзотических" схемах и механизмах решения задач.
Эвристическое сопоставление
Кленси отметил, что одна из важнейших особенностей классификации состоит в том, что эксперт выбирает категорию из ряда возможных решений, которые можно заранее перечислить. Когда мы имеем дело с простыми вещами или явлениями, то для их классификации вполне достаточно бросающихся в глаза свойств объектов. Это позволяет почти мгновенно сопоставлять данные и категории. В более сложных случаях таких лежащих на поверхности свойств может оказаться недостаточно для того, чтобы правильно определить место объекта в иерархической схеме классификации. В этом случае нам остается уповать на тот метод, который Кленси назвал эвристической классификацией. Суть его состоит в установлении неиерархических ассоциативных связей между данными и категориями классификации, которое требует выполнения промежуточных логических заключений, включающих, возможно, и концепции из другой таксономии.
На рис. 11.3 показаны три основных этапа выполнения эвристической классификации: абстрагирование от данных, сопоставление абстрактных категорий данных с абстрактными категориями решений (утолщенная стрелка) и конкретизация решения. Рассмотрим их по очереди.

Рис. 11.3. Структура логических связей при эвристической классификации ([Clancey, 1985])
Абстрагирование от данных. Часто бывает полезно абстрагироваться от данных, характеризующих конкретный случай. Так, при диагностировании заболевания зачастую важ_но не столько то, что у пациента высокая температура (скажем, 39.8°), а то, что она выше нормальной. То есть врач обычно рассуждает в терминах диапазона температур, а не в терминах конкретного ее значения.
Эвристическое сопоставление. Выполнить сопоставление первичных данных в конкретном случае и окончательного диагноза довольно трудно. Гораздо легче сопоставить более абстрактные данные и достаточно широкий класс заболеваний. Например, повышенная температура может служить индикатором лихорадки, наводящей на мысль о инфекционном заражении. Данные "включают" гипотезы, но на относительно высоком уровне абстракции.
Такой процесс сопоставления имеет ярко выраженный эвристический характер, поскольку соответствие между данными и гипотезами на любом уровне не бывает однозначным и из общего правила может быть множество исключений. Анализ данных, которые "вписываются" в определенную абстрактную категорию, просто позволяет отбирать решения, лучше согласующиеся с абстрактами решений.
Конкретизация решений. После того как определена абстрактная категория, которая сужает пространство решений, нужно определить в этом пространстве конкретные решения-кандидаты и каким-то образом их ранжировать. Это может потребовать дальнейших размышлений, в которые включаются уже количественные параметры данных, или даже сбора дополнительной информации. В любом случае целью этой процедуры является отбор "соревнующихся" гипотез в пространстве решений и последующее их ранжирование — сортировка по степени правдоподобия.
Кленси различает три варианта построения абстрактных категорий данных.
Определительный. В этом варианте в первую очередь рассматриваются характерные признаки класса объектов, и он во многом напоминает таксономический подход в ботанике и зоологии.
Количественный. В этом варианте абстрагирование выполняется исходя из количественных характеристик, как это было сделано в упоминавшемся выше примере с температурой пациента.
Обобщение. Этот вариант основывается на иерархии характерных свойств. Например, пациенты, обладающие подавленной иммунной активностью, в более общем смысле могут рассматриваться как потенциальные носители инфекции.
На рис. 11.4 представлена эвристическая классификация в контексте программы медицинской диагностики MYCIN, которую мы обсуждали в главе 3.
Исходными являются данные анализа крови пациента (количество лейкоцитов). Сначала выполняется количественное абстрагирование от конкретного значения этого показателя, который оценивается как низкий, что, в свою очередь, является характерным признаком лейкопении (здесь мы имеем дело с определительным вариантом абстрагирования). Обобщение лейкопении — подавленная иммунная активность, а обобщение последней— повышенная склонность к переносу инфекции (т.е.такие пациенты более подвержены воздействию различных микроорганизмов). Повышенная склонность к переносу инфекции является уже родовой категорией и наводит на мысль о наличии инфекции, вызванной грамотрицательными микроорганизмами (т.е. инфекции, связанной с определенным классом бактерий). Затем это родовое решение конкретизируется и предполагается, что источником инфекции являются бактерии E.Coli.
В системе MYCIN сопоставление данных и абстрактных категорий решений выполняется с помощью порождающих правил, а эвристическая природа такого сопоставления выражается коэффициентами уверенности. Эти коэффициенты можно рассматривать как заложенную в порождающее правило меру "строгости" соответствия между предпосылкой и выводом. Другие правила затем будут уточнять выполненное сопоставление и таким образом "подстраивать" коэффициент уверенности.
Классификация или конструирование?
Отличительным признаком эвристической классификации является возможность заранее перенумеровать пространство решений. Так, при выполнении диагностической процедуры в системе MYCIN программа выбирает из фиксированного множества предлагаемых микроорганизмов. Но имеется множество задач, в которых не производится выбор в пространстве решений, а решение конструируется программой. Примером может служить программа формирования курса лечения, которая входит в состав MYCIN. Курс лечения представляет собой комбинацию назначенных больному препаратов и их дозировок. Можно, конечно, представить себе и таблицу, в которую включены все возможные комбинации препаратов и дозировок, но вряд ли такой подход будет целесообразным.
Конструирование решения для некоторой проблемы обычно требует наличия какой-либо модели структуры решения и поведения сложного объекта, который мы собираемся построить. В эту модель должно быть заложено знание об ограничениях, которым должен удовлетворять создаваемый объект, а именно: ограничения на конфигурацию компонентов решения, ограничения на значения входов и выходов любых процессов и ограничения на взаимодействие двух первых ограничений.
Например, при планировании действий робота, который должен достичь заданной цели, будут существовать ограничения, запрещающие выполнение определенных операций или последрвательностей операций. Это могут быть физические ограничения, предписывающие, как можно захватывать и размещать объекты (в главе 3 они называются пред- и постусловиями). Такие ограничения частично определяют временные ограничения на то, как связывать воедино операции захвата и размещения, т.е. они определяют конфигурацию компонентов решения. Нужно также уделить внимание и ограничениям на взаимные отношения между такими компонентами. Так, если ставится задача покрасить дом в течение одного дня, то скорее всего нужно начинать с покраски комнат, которые находятся на верхнем этаже.
Как Правило, такие проблемы сами по себе не приводят к решениям в терминах эвристической классификации.
Пространство возможных последовательностей действий для открытой системы планирования является практически бесконечным, а потому вряд ли существует способ заранее определить все возможные варианты таких последовательностей и затем выбрать из них подходящее решение. В отличие от классификации, задача конструирования осложняется наличием комбинаторных перестановок возможных элементов решения. Таким образом, приходится сразу отказаться от ориентации на выбор решения из какого-либо подходящего класса и конкретизации его с помощью эвристического сопоставления.
Тем не менее очень важно учитывать предложенное Кленси разделение между задачами и методами решения проблем. Все диагностические задачи не являются проблемами классификации, поскольку при их решении может потребоваться создать новые классы отказов или модифицировать существующие, по мере того как будет накапливаться опыт работы с новыми устройствами. Аналогично, для задачи планирования в какой-то проблемной области может оказаться возможным организовать выбор из библиотеки планов или набора заготовок планов, как это делается в системе ONCOCIN (мы рассматривали ее в главе 10). Все зависит от того, какие ограничения накладываются в данной ситуации на процесс решения проблемы. Даже обычную задачу проектирования, например нового дома, можно решить несколькими способами. На одном конце диапазона стоит привлечение архитектора, который спроектирует дом с нуля (метод конструирования), а на другом — выбор проекта из каталога (метод классификации).
Кленси утверждает, что его работа может следующим образом, повлиять на исследования в области экспертных систем.
Она предоставляет в распоряжение исследователей инструмент для выполнения декомпозиции проблемы в набор операций, которые значительно легче классифицировать.
Разработка и анализ методик, аналогичных эвристической классификации, может послужить прелюдией к созданию специальных инструментальных средств инженерии знаний для этих целей.
Эта работа предоставляет проектировщикам экспертных систем базис для выбора областей приложения.Например, если оказывается, что проблема подходит для эвристической классификации, то имеются серьезные основания верить, что эту проблему можно решить с помощью технологии экспертных систем.
В следующей главе мы рассмотрим, как, используя концепции конструирования и эвристической классификации, можно взаимно увязать задачи, методы и инструментальные средства. В частности, мы остановимся на возможности использования такой методики анализа для целей автоматизации извлечения знаний.
Классификация методов решения проблем
Классификация — это одна из наиболее распространенных проблем в любой предметной области. Например, эксперты в области ботаники или зоологии первым делом пытаются определить место в существующей таксономии для вновь открытого растения или животного. Как правило, система классов имеет явно выраженную иерархическую организацию, в которой подклассы обладают определенными свойствами, характерными для своих суперклассов, причем классы-соседи на одном уровне иерархии являются взаимно исключающими в отношении наличия или отсутствия определенных наборов свойств.
Классификация задач экспертных систем
В сборнике статей, опубликованном под общей редакцией Хейеса-Рота [Heyes-Roth et al, 1983], была предложена классификация экспертных систем, которая отражает специфику задач, решаемых с помощью этой технологии. С тех пор эта классификация неоднократно критиковалась различными авторами, в основном из-за того, что в ней были смешаны разные характеристики, а это привело к тому, что сформулированные категории нельзя рассматривать как взаимно исключающие. Тем не менее мы кратко представим эту классификацию и будем рассматривать ее как отправную точку для дальнейшего совершенствования.
Интерпретирующие системы предназначены для формирования описания ситуаций по результатам наблюдений или данным, получаемым от различного рода сенсоров. Типичные задачи, решаемые с помощью интерпретирующих систем, — распознавание образов и определение химической структуры вещества.
Прогнозирующие системы предназначены для логического анализа возможных последствий заданных ситуаций или событий. Типичные задачи для экспертных систем этого типа — предсказание погоды и прогноз ситуаций на финансовых рынках.
Диагностические системы предназначены для обнаружения источников неисправностей по результатам наблюдений за поведением контролируемой системы (технической или биологической). В эту категорию входит широкий спектр задач в самых различных предметных областях — медицине, механике, электронике и т.д.
Системы проектирования предназначены для структурного синтеза конфигурации объектов (компонентов проектируемой системы) при заданных ограничениях. Типичными задачами для таких систем является синтез электронных схем, компоновка архитектурных планов, оптимальное размещение объектов в ограниченном пространстве.
Системы планирования предназначены для подготовки планов проведения последовательности операций, приводящей к заданной цели. К этой категории относятся задачи планирования поведения роботов и составление маршрутов передвижения транспорта.
Системы мониторинга анализируют поведение контролируемой системы и, сравнивая полученные данные с критическими точками заранее составленного плана, прогнозируют вероятность достижения поставленной цели.
Типовые области приложения таких систем — контроль движения воздушного транспорта и наблюдение за состоянием энергетических объектов.
Наладочные системы предназначены для выработки рекомендаций по устранению неисправностей в контролируемой системе. К этому классу относятся системы, помогающие программистам в отладке программного обеспечения, и консультирующие системы.
Системы оказания помощи при ремонте оборудования выполняют планирование процесса устранения неисправностей в сложных объектах, например в сетях инженерных коммуникаций.
Обучающие системы проводят анализ знаний студентов по определенному предмету, отыскивают пробелы в знаниях и предлагают средства для их ликвидации.
Системы контроля обеспечивают адаптивное управление поведением сложных человеко-машинных систем, прогнозируя появление возможных сбоев и планируя действия, необходимые для их предупреждения. Областью применения таких систем является управление воздушным транспортом, военными действиями и деловой активностью в сфере бизнеса.
Как уже упоминалось, множество исследователей отмечали наличие ряда существенных недостатков в приведенной классификации. Рейхгелт и Ван Гармелен обратили внимание на то, что некоторые из категорий в ней перекрываются или включают друг друга [Reichgelt and van Harmelen, 1986]. Например, категорию системы планирования в этой классификации вполне можно рассматривать как составную часть категории системы проектирования, поскольку планирование можно трактовать как проектирование последовательности операций (на это, кстати, обратили внимание и авторы классификации [Heyes-Roth et al, 1983]). Кленси также задался вопросом: "Является ли автоматизация программирования проблемой планирования или проектирования!" [Clancey, 1985]. Совершенно очевидно, что подобное замечание можно высказать и по отношению к таким категориям, как диагностические системы, системы мониторинга, системы оказания помощи при ремонте и обучающие системы.
Кленси предложил альтернативный метод классификации, взяв за основу набор родовых (generic) операций, выполняемых в рассматриваемых системах.
Вместо того чтобы пытаться разделить анализируемые программы решения проблем по признакам особенностей тех проблем, на решение которых они ориентированы, он предложил поставить во главу угла те виды операций, которые выполняются по отношению к реальной обслуживаемой системе (механической, биологической или электрической).
Кленси предложил разделять синтетические операции, результатом которых является изменение структуры (конструкции) системы, и аналитические операции, которые интерпретируют характеристики и свойства системы, не изменяя ее как таковую. Эта обобщенная концепция может быть конкретизирована, в результате чего построена иерархическая схема видов операций, выполнение которых может быть затребовано от программы. На рис. 11.1 и 11.2 представлены такие иерархические схемы для аналитических и синтетических операций.
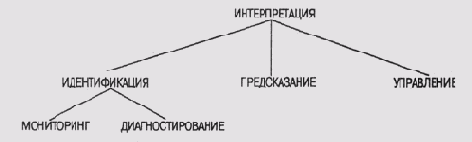
Рис. 11.1. Иерархия родовых аналитических операции ([Clancey, 1985])
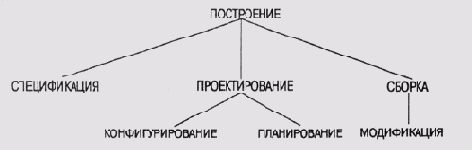
Рис. 11.2. Иерархия родовых синтетических операции ([Clancey, 1985])
На рис. 11.1 показано, как различные виды операции Интерпретация соотносятся с понятием система. Операция Идентификация позволит выяснить, с системой какого типа мы имеем дело, используя в качестве объекта анализа пары сигналов "стимул/реакция". Если обслуживаемая система является системой управления, то операция Предсказание предоставит нам информацию о том, каких выходных сигналов (проявлений поведения системы) следует ожидать для определенного класса входных сигналов. Операция Управление, опираясь на известные характеристики системы, определяет, какие стимулы (входные сигналы) следует подать на ее вход, чтобы получить желаемую реакцию. Таким образом, три указанные разновидности операции Интерпретация перекрывают все возможные варианты неопределенности любого из членов множества {вход, выход, сиcтема} при известных двух других. Для систем, в которых существует неисправность, можно провести дальнейшую конкретизацию операции Идентификация. Операция Мониторинг определяет наличие отклонений в поведении, а операция Диагностирование выявляет причины этих отклонений.
Как показано на рис. 11.2, есть три варианта конкретизации операции Построение. Операция Спецификация задает ограничения, которым должна удовлетворять синтезируемая система. Операция Проектирование формирует структурную организацию компонентов, которая удовлетворяет заданным ограничениям, а операция Сборка реализует спроектированную систему, собирая воедино отдельные ее компоненты. Операция Проектирование, в свою очередь, разделяется на операции Конфигурирование (формирование структуры системы) и Планирование (формирование последовательности действий по созданию системы с заданной структурой).
Теперь посмотрим, как соотносится описанная ранее классификация экспертных систем с предложенной Кленси иерархической схемой операций.
Кленси относит интерпретацию к родовым операциям, таким образом, задача интерпретации "накрывает" любые другие задачи, в том или ином виде выполняющие описание обслуживаемой системы. В частности, выделенные в первой классификации задачи (категории экспертных систем) предсказание и управление теперь превращаются в разновидность задачи интерпретация.
Мониторинг и диагноз становятся вариантами задачи идентификации, которая, в свою очередь, является разновидностью задачи интерпретации. Задачу наладка можно включить в задачу диагноз, хотя частично она включает и задачу модификация (чтобы привести обслуживаемую систему в режим нормальной работы).
Проектирование остается базовой категорией, а обучение "поглощается" задачей модификация, так же, как и ремонт. Задача планирование превращается в один из вариантов задачи проектирование.
Как уже отмечалось, то внимание, которое мы уделяем вопросам классификации, объясняется не только любовью к отвлеченным теоретическим рассуждениям. В идеале мы стремимся к тому, чтобы иметь возможность отобразить множество методов решения проблем на множество задач. Тогда можно было бы сказать, какой из методов наиболее приемлем для любой заданной задачи. Вклад Кленси в этот вопрос — выявление определенного метода решения проблем, эвристической классификации, к рассмотрению которой мы сейчас и перейдем.Мы уделяем этому методу так много внимания по той простой причине, что он достаточно понятен и может быть использован для характеристики поведения множества систем, которые мы рассматривали в предыдущих главах.
Общность эвристической классификации
Интересной особенностью методики анализа, предложенной Кленси, является то, что она подходит для большого спектра экспертных систем. Оказывается, что, несмотря на различие областей применения, многие экспертные системы функционируют, в принципе, одинаково. В своей статье Кленси продемонстрировал применение предложенной методики на множестве систем, помимо MYC1N.
Программа SAGON [Bennett et al., 1978] предназначена для выработки рекомендаций относительно использования программного пакета MARC, с помощью которого выполняется анализ характеристик механических систем методом конечных элементов. MARC — это достаточно сложный программный продукт, который предоставляет в распоряжение пользователей огромное количество опций. Разумное использование широких возможностей MARC представляет серьезную проблему для неопытных пользователей. Роль программы SAGON состоит именно в том, чтобы помочь таким пользователям. Программа формирует стратегию анализа, которая основывается на введенном пользователем описании компонентов.
Рис. 11.4. Структура логических связей в системе MYCIN ([Clancey, 1985])
Программа SAGON располагает знаниями о более чем 30 классах анализа. При определении типа анализа, наиболее подходящего для заданной пользователем проблемы, программа использует два этапа эвристического сопоставления, которые аналогичны описанным Кленси. Первый этап — выбор математической модели для оценки напряжений и деформаций при различных условиях, которая учитывает введенную пользователем информацию о геометрии моделируемой конструкции и нагрузках. Второй этап — выбор стратегии анализа этой модели, руководствуясь принципом наихудшего случая распределения напряжений и деформаций.
Оба этапа включают выбор из набора альтернативных вариантов и эвристическое сопоставление различных абстрактных категорий. Этап конкретизация решения отсутствует, поскольку на втором этапе определяются только подходящие классы программ из комплекта MARC, хотя формируемая стратегия анализа включает и рекомендации о выборе специфических функций из числа тех, которые имеются в MARC.
В отличие от MYCIN, при сопоставлении не используются коэффициенты уверенности. Это объясняется тем, что за основу принят принцип наихудшего случая, который позволяет давать категоричные рекомендации даже в случае не совсем точного сопоставления.
Кленси обратил также внимание на то, что в большинстве экспертных систем используется не одна, а несколько родовых операций из тех, что представлены на рис. 11.1 и 11.2. В частности, процесс выработки рекомендаций о курсе лечения в системе MYCIN включает мониторинг состояния пациента, диагностирование категории заболевания, идентификацию микроорганизмов и модификацию состояния пациента (или состояния организма). Программа SACON идентифицирует типы структур, предсказывает в терминах математической модели, как такие структуры будут себя вести, и затем идентифицирует подходящий метод анализа.
В своей статье Кленси также проанализировал и систему SOPHIE ([Brown et ai, 1982]), предназначенную для поиска неисправностей в электронных схемах. Программа создавалась как инструмент для проведения исследований в области обучения с использованием компьютера, но включенный в ее состав модуль решения проблем способен классифицировать электронные схемы в терминах компонентов, которые вызывают неправильное функционирование схемы. Заранее пронумерованное пространство решений этого модуля содержит описания дозволенных и ошибочных пар вход/выход.
На рис. 11.5 схематически показано, каким образом структуру логического вывода в системе SOPHIE можно трактовать в качестве примера эвристической классификации. Результаты измерений в различных точках электронной схемы позволяют SOPHIE формировать количественные утверждения о поведении схемы, например о напряжении между двумя точками электрической цепи. Программа затем может преобразовать их в утверждения относительно качества функционирования схемы (например, слишком высокое напряжение), а последние эвристически сопоставляются с отказами на уровне модуля. Таким образом, в терминах задач анализа, представленных на рис. 11.1, можно говорить о том, что в системе SOPHIE выполняется мониторинг состояния схемы и диагностирование отказавших модулей и компонентов.
В системе COMPASS, описанной в предыдущей главе, также используется некоторая форма эвристической классификации как часть процесса декомпозиции проблем. При анализе отказов системы переключений телефонной сети программа сначала разбивает сообщения об ошибках на группы. Это можно рассматривать как этап формирования абстрактной категории данных в соответствии с методикой Кленси. Во-первых, такое разбиение необходимо, поскольку для идентификации отказа недостаточно единственного сообщения, а во-вторых, разбиение возможно, поскольку существует эвристика, позволяющая сопоставлять отказы с набором сообщений определенных групп. Но в этой системе можно найти и аналог этапа конкретизации, на котором устраняются неопределенности, остающиеся после группирования. Без неявной абстракции данных на этапе группирования не удалось бы сопоставить сообщения и отказы, а без последующего этапа конкретизации рекомендации, которые формирует система, были бы слишком расплывчаты и неконкретны.
Ценность предложенной Кленси методики анализа заключается в том, что она непосредственна связана с поиском ответов на сформулированные в начале этой главы вопросы. В частности, эта методика позволяет определить базовый метод решения проблем, который может быть с успехом применен в различных предметных областях. В следующей главе мы попытаемся четче обозначить различие между эвристической классификацией и другими методами и выделим тот класс проблем, по отношению к которым применение эвристической классификации наиболее целесообразно.
Рис. 11.5. Структура логических связей в системе SOPHIE ([Clancey, 1985])
Нужно отметить, что предложенная Кленси методика анализа фундаментальных аспектов решения проблем с помощью технологии экспертных систем не является единственной. Например, в работе [Chandrasekaran, 1986] получило дальнейшее развитие понятие родовой задачи (generic task). Родовая задача представляет собой, по сути, спецификацию задачи, включающую описание различных форм знаний о предметной области и их организации для выполнения задачи вручную и набор режимов выполнения задачи.
Примерами таких задач являются иерархическая классификация, сопоставление или оценка гипотез и передача информации, направляемая знаниями.
Задача иерархической классификации включает отбор гипотез из иерархически организованного пространства альтернатив, а затем уточнение этих гипотез с учетом' имеющихся данных. Гипотезами могут быть, например, заболевания или неисправности оборудования. Каждая такая гипотеза может быть порождена имеющимися данными, но прежде чем развивать ее дальше, необходимо выполнить определенные проверки или уточнить гипотезу таким образом, чтобы она соответствовала более широкому набору имеющихся фактов. Экспертные системы, в которых выполняются такие родовые задачи, мы рассмотрим в главах 13 и 16.
Под сопоставлением гипотез понимается выполнение количественной оценки свидетельств в пользу достоверности гипотез или того, насколько полным является соответствие между имеющимися данными и гипотезами. В такую оценку иногда включается априорная вероятность гипотез, поиск возможных конкурирующих гипотез и т.п. Все операции, связанные с обработкой коэффициентов уверенности в системе MYCIN, можно рассматривать как реализацию механизма родовых задач этого вида. Некоторые из этих тем мы рассмотрим в главе 12.
Передача информации, направляемой знаниями, проявляется в виде неочевидных логических связей, которые трудно классифицировать, но которые характерны для способа мышления эксперта. Например, врач не оставит без внимания тот факт, что пациент недавно перенес хирургическую операцию, поскольку, скорее всего, он подвергся анестезии, а это может косвенно сказаться на формировании диагноза. В логических рассуждениях такого типа используются "фоновые" знания о предметной области, а не те порождающие правила, с которыми мы связываем свое представление об экспертной системе медицинской диагностики. Ниже, в главе 12, мы обсудим дифференциацию разных видов знаний.
Итак, одно из отличий между подходами Кленси и Чандрасекарана состоит в том, что для первого характерно стремление разбить решение проблемы на мелкие абстрактные категории.
Подход Кленси приводит к поглощению этапа сопоставления гипотез эвристической классификацией, в то время как Чандрасёкаран делает акцент на том, что обработка гипотез может рассматриваться как самостоятельная родовая задача со своими собственными правами вне контекста классификации. Таким образом, появляется проблема, до какого уровня "зернистости" целесообразно доводить абстрагирование и какие критерии следует выбрать для оценки этой "грануляции". Рассмотрение этих вопросов выходит за рамки вводного курса, однако те, кто собирается профессионально заниматься конструированием экспертных систем, должны не упускать из виду существование множества способов разрешения этих проблем.
11.1. Определение понятия "оружие нападения"
Под термином "оружие нападения" чаще всего понимаются различные виды полуавтоматического индивидуального стрелкового оружия, подобного тому, которое используется в профессиональной армии. Довольно трудно дать точное определение оружия нападения, из которого было бы ясно, чем отличается такое оружие от спортивного, например. Но в таком определении весьма заинтересованы законодатели на самых различных уровнях— федеральном, штата и местном. В сборниках законодательных актов можно встретить самые разные толкования этого термина. В контексте этой книги попытка сформулировать такое определение может быть хорошим примером эвристической классификации.
Определение, данное законодателями города Рочестер, шт. Нью-Йорк, включает пять частей. В первых трех специфицируются свойства стрелкового оружия, которые позволяют отнести его к категории оружия нападения. В части 4 просто перечисляются модели оружия, которые следует отнести к этой категории. В части 5 перечисляются типы огнестрельного оружия, которые не считаются относящимися к категории оружия нападения.
Можно считать, что в первых трех частях выполняется абстрагирование от данных, как, например, в этом предложении:
"Любая винтовка с центральным боем или охотничье ружье, в котором используется сила пороховых газов для перезаряжания после каждого выстрела и которое заряжается или может быть заряжено обоймой на 6 и более боеприпасов".
Этим определением "накрывается" большинство полуавтоматических винтовок и охотничьих ружей, оснащенных магазином, в который помещается более пяти патронов.
В части 4 перечисляются 17 моделей индивидуального стрелкового оружия, причем некоторые из них уже подходят под определение, которое дано в первых трех частях. Но некоторые модели отнесены к этой категории, несмотря на то, что они не обладают признаками, обозначенными ранее. В, частности, к таким моделям относится полуавтоматический пистолет с 30-зарядным магазином Gobray М11. Можно считать, что в этой части рассматриваются специальные случаи, не учтенные при составлении предыдущих трех.
Часть 5 можно рассматривать как аналог этапа конкретизация решения. В этой части некоторые из типов оружия, "подпадающие" под действие частей 1-3, исключаются из категории при наличии дополнительных признаков.
В разделе упражнений вы встретите набор правил на языке CLIPS, которые соответствуют определению, сформулированному в рассматриваемом документе.
Рекомендуемая литература
Помимо тех работ, ссылки на которые приведены в тексте, существует и ранняя классификация подходов к решению проблем, выполненная Чандрасекараном [Chandrasekaran, 1983]. Теоретические аспекты классификации родовых задач были увязаны с проектом MDX [Chandrasekaran, 1984], в котором исследовались методы решения проблем применительно к области диагностики легочных заболеваний. Наиболее полное изложение подхода, предполагающего использование родовых задач, сопровождаемое комментариями и материалами дискуссии, читатель найдет в работе [Chandrasekaran, 1988].
Достаточно полное изложение результатов, полученных Кленси, можно найти в работе [Clancey, 1987, а, в]. Описание системы HERACLES, задуманной как прототип оболочки для исследования методики эвристической классификации, представлено в работе [Clancey, 1987,с].
Методика эвристической классификации была использована в системе KADS в качестве абстрактной модели экспертноети [Scheiber et al, 1993]. В настоящее время существуют KADS-модели и для других родовых задач, таких как мониторинг, конфигурирование, моделирование и т.д.
Проанализируйте классификацию задач, решаемых экспертными
1. Проанализируйте классификацию задач, решаемых экспертными системами, которую предложил Хейес-Рот.
I) Как вы считаете, существуют ли задачи, которые не представлены в этой классификации?
II) В какую категорию систем этой классификации входит, по вашему мнению, система, которая консультирует пользователей относительно их юридических прав и выдает рекомендации о действиях в ходе судебного процесса.
2. Проанализируйте схему задач экспертных систем, предложенную Кленси (рис. 11.1 и 11.2).
I) Где в этой схеме, по-вашему, место для компьютерной системы обработки данных?
II) Можете ли вы предложить способ расширения или уточнения такого анализа? Например, можете ли вы предложить способ дальнейшей дифференциации задачи "Управление"?
3. Являются ли перечисленные ниже задачи по своему характеру задачами классификации, задачами конструирования или задачами, обладающими признаками обоих этих типов?
I) Принятие решения о том, какой курс дисциплин следует прослушать в колледже.
II) Принятие решения о том, как провести отпуск.
III) Изменение ранее составленного плана проведения отпуска вследствие непредвиденных обстоятельств.
IV) Подготовка налоговой декларации.
4. Ниже представлен список правил на языке CLIPS, который соответствует приведенному во врезке 11.1 определению термина "оружие нападения" (assault-weapon). Некоторые правила в этом наборе вам следует попытаться сформулировать самостоятельно.
;; Объявления (deftemplate gun
(field name (type SYMBOL))
(field class (type SYMBOL))
(field action (type SYMBOL))
(field caliber (type FLOAT))
(field capacity (type INTEGER))
(field feature (type SYMBOL))
)
(deftemplate assault-weapon
(field name (type SYMBOL)) )
;; Факты
;; Данный набор исходных правил квалифицируют
;; только модели Heckler & Kock 91 и Benelli
;; как "оружие нападения".
(deffacts guns
(gun (name Browning22)
(class rifle) (action semi)
(caliber .22) (capacity 11))
(gun (name CobrayMll)
Формирование суждений нбазе модели в системе INTERNIST
В программе INTERNIST предпринята попытка смоделировать поведение врача на различных этапах диагностического процесса. Как правило, общая картина, которая вырисовывается на основании имеющихся симптомов, порождает одну или несколько гипотез о том, какие патологии имеются у пациента. Эти гипотезы, в свою очередь, подталкивают врача к поиску других симптомов. Дальнейшее наблюдение пациента может привести к тому, что какие-то из ранее выдвинутых гипотез получат дальнейшее подтверждение, а другие, наоборот, окажутся противоречащими новым данным. Не исключен и вариант появления после более тщательного исследования пациента новых гипотез. Гипотезы, которые появились на начальном этапе, можно считать порожденными первичными данными в том смысле, что определенное проявление патологии порождает множество догадок. Последующее накопление новых данных, призванных подтвердить или опровергнуть первоначальные догадки, можно рассматривать как ведомое моделью в том смысле, что оно базируется на определенных стереотипах или концептуальных идеях о том, как проявляется то или иное заболевание.
В большинстве задач, связанных с логическим выводом (к ним относятся и задачи диагностирования), редко когда рассуждение ведется только в одном направлении, т.е. в направлении одной цели (версии о причинах случившегося). В основном это происходит из-за неполноты исходной информации, которой бывает недостаточно для четкой формулировки проблемы. Например, врач может не располагать на начальном этапе обследования достаточно полной информацией для того, чтобы очертить круг возможных заболеваний пациента, или та информация, которой он располагает, может вести его в разных направлениях (не исключено, что пациент страдает не одним, а несколькими заболеваниями).
При разработке программы INTERNIST ставилась задача провести разграничение между множеством взаимно исключающих гипотез о заболеваниях, которые могут возникнуть, в процессе диагностирования. Если пациент страдает несколькими заболеваниями, то программа должна отобрать такое множество гипотез, которое "накрывало" бы как можно большую часть (а лучше все) обнаруженных симптомов. Для этого сначала исследуется наиболее правдоподобная гипотеза, определяется, какую часть из имеющихся симптомов она учитывает, затем анализируется следующая по степени правдоподобия гипотеза, и так до тех пор, пока набором гипотез не будут учтены все имеющиеся симптомы.
Иерархическое построение и проверкгипотез
13.1. Влияние сложности пространства гипотез на организацию работы системы
13.2. Структурированные объекты в CENTAUR
13.3. Формирование суждений на базе модели в системе INTERNIST
13.4. Рабочая среда инженерии знаний TDE Рекомендуемая литература Упражнения
В данной главе будут рассмотрены три системы, реализующие комбинированный метод решения проблем, который получил в литературе наименование иерархического построения и проверки гипотез (hierarchical hypothesize and test). С методом эвристической классификации этот метод сходен в том, что в нем используется отображение множества абстрактных категорий данных на множество абстрактных категорий решений, но этот подход усложнен тем, что элементы решений могут комбинироваться и объединяться в составные гипотезы. Цель такого усложнения — построение гипотезы, которая могла бы объяснить все симптомы и признаки анализируемой ситуации. Классическим примером ситуации, в которой проявляются достоинства нового метода, является дифференциальное диагностирование, когда предполагается, что пациент страдает не одним, а несколькими заболеваниями, и нужно по множеству симптомов и показаний определить, какими именно.
Включение в процесс анализа комбинированных гипотез значительно усложняет положение вещей. Пространство гипотез "разрастается", и его приходится каким-то образом структурировать, чтобы сделать обозримым. Метод иерархического построения и проверки гипотез пытается решить эту проблему с помощью явно выраженного таксо-нометрического представления пространства гипотез. Таксонометрическое представление обычно имеет вид дерева, листьями которого являются элементы решения. Нет ничего удивительного в том, что при представлении знаний, основанном на иерархически структурированной организации объектов, процесс активизации гипотез направляется этой организацией и заданным режимом управления.
Первой будет рассмотрена система CENTAUR [Aikins, 1983], поскольку она лучше документирована и в особенностях ее работы легче разобраться. Затем мы рассмотрим более сложную систему INTERNIST [Pople, 1977], на примере которой можно увидеть, какие проблемы возникают при использовании метода иерархического построения и проверки гипотез. Последней будет рассмотрена современная система TEST [Kahn et al., 1987], на примере которой можно увидеть, какое влияние оказывает иерархическая стратегия на методику извлечения знаний.
Методиквыделения правдоподобных гипотез в INTERNIST
В процессе выполнения консультаций программа INTERNIST работает следующим образом. Сначала пользователь вводит список существующих проявлений заболеваний пациента. Каждое проявление активизирует один или несколько узлов в дереве заболеваний.
Из выделенных на этом этапе узлов программа формирует модели заболевания, каждая из которых включает четыре списка:
(1) наблюдаемые проявления, не связанные с данным заболеванием;
(2) наблюдаемые проявления, согласующиеся с данным заболеванием;
(3) проявления, отсутствующие во введенных данных, но всегда сопутствующие данному заболеванию;
(4) проявления, которые отсутствуют во введенных данных, но не согласуются с данным заболеванием (опровергают выдвинутую гипотезу).
В модели заболевания проявления, подтверждающие гипотезу, получают положительные оценки, а те, которые им противоречат, — отрицательные. Оба типа оценок "взвешиваются" значениями свойств IMPORT соответствующих проявлений, и модель получает премиальные очки, если имеет причинную связь с другим подтвержденным заболеванием. Затем модели заболеваний разделяются на две группы. В одну группу попадают модель с самой высокой оценкой и все остальные, которые представляют взаимно исключающие с ней гипотезы. Их можно считать "соседними" узлами на дереве заболеваний. Другая группа включает заболевания, совместимые с наиболее правдоподобной гипотезой, т.е. узлы, принадлежащие другим областям заболеваний (рис. 13.2).
Рис. 13.2. Разделение узлов в дереве гипотез. Узлы активизированных гипотез вычерчены утолщенными прямоугольниками, а узел наиболее правдоподобной гипотезы и его дочерние узлы залиты серым цветом
В таком разделении используется концепция доминирования, которой придается следующий смысл. Модель заболевания D1 доминирует над D2 в том случае, если наблюдаемые проявления, которые не могут быть объяснены гипотезой D1, входят как подмножество в число проявлений, которые не объясняются и гипотезой D2. Если мы выделили наиболее правдоподобную гипотезу D0 среди всех активизированных на первом этапе, то каждая из остальных гипотез Di сравнивается с гипотезой Do Если D0 доминирует над Di или Di доминирует над Do, то Di включается в ту же группу "привилегированных" гипотез, что и Do Эта группа должна рассматриваться программой в первую очередь.
В противном случае Д включается в другую группу гипотез, анализ которых откладывается на будущее.
Рациональное зерно в таком разделении в том, что модели, включенные в привилегированную группу на любом этапе уточнения, можно считать взаимно исключающими альтернативами. Такое заключение основано на том, что для любых гипотез (моделей) Di и Dj в этой группе диагноз, включающий Di иDj, добавит очень немного или не добавит ничего к "полноте накрытия" каждой из гипотез Di и Dj по отдельности. На следующем этапе уточнения модели обрабатываются по той же методике, если проблема выбора среди моделей, связанных с Do, будет решена. Разделение начинается с нового узла Do, который получит наивысшую оценку среди уточняемых моделей.
Уже после ввода первой порции исходных данных будет активизирована только часть всех узлов дерева. Теперь задача программы состоит в том, чтобы преобразовать дерево из исходного состояния в состояние решения. В состоянии решения дерево должно включать только те терминальные узлы, которые в совокупности "накрывают" все имеющиеся симптомы.
Разделив модели заболеваний, программа может использовать ряд альтернативных стратегий, которые выбираются в зависимости от количества обрабатываемых гипотез.
Если обрабатывается более четырех гипотез, используется стратегия опровержения (режим RULEOUT). Смысл ее заключается в том, чтобы как можно сильнее свернуть дерево пространства гипотез, задавая пользователю вопросы о симптомах, которые являются наиболее сильными индикаторами гипотез-кандидатов.
Если количество анализируемых гипотез не превышает четырех, но больше одной, используется стратегия дифференциации (режим DISCRIMINATE). При этом пользователю задают вопросы, которые помогут выбрать между гипотезами-кандидатами.
Если анализируется всего одна гипотеза, используется стратегия верификации (режим PURSUING). Пользователю задают вопросы, способные подтвердить справедливость анализируемой гипотезы.
Весь процесс носит итеративный характер.Данные, которые пользователь вводит в ответ на вопросы программы в любом из перечисленных режимов, обрабатываются по той же методике, что и введенные сразу после начала сеанса работы с программой. При этом, в частности, активизируются новые узлы дерева, обновляется активизация ранее проанализированных узлов, формируются и сортируются модели заболеваний и выбираются узлы (возможно, новые) для формирования уточняющих вопросов.
Правила, включенные в прототипы
Нелишне напомнить, что именно компоненты прототипа представляют большую часть знаний объектного уровня, специфичных для определенной предметной области, поскольку в структуре этого типа содержится информация о лабораторных исследованиях, результаты которых должны быть использованы при диагностировании того или иного конкретного заболевания. Эти компоненты являются значениями слотов прототипов, представляющих заболевания, и в то же время имеют собственную внутреннюю структуру и являются прототипами со своими собственными правами. Таким образом, оказывается, что в составе прототипа имеются не только порождающие правила, но и другие прототипы. Можно с полным правом утверждать, что система прототипов имеет по крайней мере двухмерную организацию в дополнение к иерархической организации, представленной в явном виде в терминах типов и подтипов заболеваний. Структуры данных, которые могут быть включены сами в себя, принято называть рекурсивными.
В CENTAUR используется пять типов правил.
Правила логического вывода. Связаны с компонентами, представляющими клинические параметры, и задают возможные способы определения их значений.
Правила активизации. Это антецедентные правила, связанные с клиническими параметрами, которые служат для выдвижения прототипов в качестве гипотез с некоторой степенью правдоподобности.
Правша обработки остаточных фактов. После того как система придет к какому-нибудь заключению в форме набора подтвержденных прототипов, эти правила стараются оценить, как это заключение согласуется с фактами, неучтенными при формировании заключения (остаточными фактами).
Уточняющие правила. Эти правила предполагают проведение дополнительных лабораторных анализов. После выполнения этих правил будет сформировано окончательное множество прототипов с указанием, какой из них учитывает тот или иной из имеющихся фактов, причем каждый факт должен быть учтен по крайней мере одним прототипом.
Правша вывода. Эти правила переводят информацию, представленную в прототипах, на "человеческий" язык и представляют ее пользователю.
Другие слоты содержат обычную информацию, необходимую для учета, — имя автора, сведения об источнике информации и о текущей ситуации, которые затем используются при формировании объяснения, почему данный прототип был активизирован.
Как видно, в системе CENTAUR в основу классификации правил положены функции, выполняемые с их помощью. В системе PUFF, реализованной на базе оболочки EMYCIN, все правила считаются правилами логического вывода, хотя многие из них и не имеют непосредственного отношения к логическому выводу. Например, большая группа правил предназначена для сбора информации, используемой в качестве свидетельств, или для установки значений по умолчанию. Кроме того, контекст применения правил в CENTAUR представлен в явном виде, поскольку правила являются значениями слотов. Например, в системе PUFF правила для оценки значений клинических параметров индексированы по наименованию параметра, которое появляется в консеквентной части правила, т.е. использован тот же принцип, что и в системе MYCIN. В системе CENTAUR правила оценки определенных параметров хранятся в виде значения одного из слотов в прототипе компонента, представляющего этот параметр, и применяются только в контексте этого прототипа, т.е. в том случае, если прототип активизирован.
Ниже, в главе 18, будет показано, что дальнейшее углубление такого "распределенного" подхода к организации порождающих правил приводит к созданию нового класса систем, получивших название систем с доской объявлений (blackboard systems). Но уже на опыте эксплуатации системы CENTAUR исследователи убедились в преимуществах явного связывания правил с контекстом их применения. Это не только упрощает процесс программирования экспертной системы, но и помогает при формировании объяснений, почему в конкретной ситуации были использованы определенные правила (более подробно об этом — в главе 16).
Представление знаний в дереве заболеваний
Попл (Pople) рассматривает четыре этапа процесса логического вывода при диагностировании.
(1) Клинические наблюдения должны дать основания для формирования списка возможных заболеваний (кандидатов для дальнейшего уточнения), которые могут быть причиной наблюдаемых явлений или симптомов.
(2) Эти гипотетические кандидаты затем порождают предположения относительно того, какими другими проявлениями они могли бы "дать знать" о себе.
(3) Далее потребуется изыскать какой-либо метод, позволяющий сделать выбор в пользу определенных гипотез на основании имеющихся свидетельств.
(4) Нужно иметь возможность разделить множество имеющихся гипотез на ряд взаимно исключающих подмножеств. Правдоподобие одного подмножества автоматически означает при этом неправдоподобие другого.
Ключевым моментом в рассматриваемой Поплом схеме является двунаправленная связь между заболеваниями, с одной стороны, и признаками или симптомами, с другой. Программа INTERNIST рассматривает такую связь как пару отдельных отношений: EVOKE и MANIFEST.
Отношение EVOKE (истребование) указывает на способ, которым некоторый признак дает основание предполагать наличие определенного заболевания.
Отношение MANIFEST (провозглашение) указывает на то, как (в виде каких показаний или симптомов) может проявляться определенное заболевание.
Знания в области медицины представлены в программе INTERNIST в виде дерева заболеваний — иерархической классификации типов заболеваний. Корневой узел в этом дереве соответствует всем известным заболеваниям, нетерминальные узлы — областям заболеваний, а терминальные — сущностям заболеваний, т.е. конкретным заболеваниям, которые можно диагностировать и для которых можно назначать курс лечения. Это дерево представляет собой статическую структуру данных, отдельную от основного программного кода системы INTERNIST, что делает его сходным с таблицами знаний в системе MYCIN. Но в отличие от таблиц знаний в MYCIN, знания в системе INTERNIST играют куда более активную роль в управлении процессом логического вывода.
База знаний программы INTERNIST формируется следующим образом.
(1) Определяется базовая структура иерархии— к корневому узлу подсоединяются узлы основных областей внутренних болезней (органов дыхания, болезней печени, сердца и т.п.).
(2) Выделяются подкатегории, в которых объединяются области заболеваний с похожими схемами протекания (патогенезом) и проявлениями (признаками и симптомами).
(3) Эти подкатегории разделяются до тех пор, пока не будет достигнут уровень сущностей, т.е. конкретных заболеваний.
(4) Собираются данные, касающиеся связей между сущностями заболеваний и их проявлениями. В число этих данных входят: список всех проявлений конкретного заболевания; оценка вероятности того, что данное заболевание является причиной проявления именно такого признака или симптома; оценка того, насколько часто у пациентов, страдающих определенным заболеванием, наблюдается каждое из отмеченных проявлений.
(5) К представлению каждого заболевания D присоединяется список связанных с ним проявлений (M1, ..., Мn), список показателей причинности L(D, Mi) и список показателей частотности L(Mi, D). Показатели обоих типов определены в диапазоне 0-5.
(6) С каждым заболеванием D, помимо признаков и симптомов, могут быть связаны и другие заболевания, которые также могут рассматриваться как проявления заболевания D. Такие ''вторичные" заболевания связываются в структуре представления знаний с узлом заболевания отношениями EVOKE и MANIFEST.
(7) После сбора и представления всей информации, касающейся "обслуживаемых" системой заболеваний D (т.е. терминальных узлов дерева), запускается программа, которая преобразует описанное дерево в обобщенное представление иерархической структуры. В этом представлении нетерминальные узлы содержат только те свойства, которые являются общими для всех его дочерних узлов.
(8) Вводятся данные об отдельных проявлениях. Наиболее существенными свойствами проявлений являются TYPE (например, признак, симптом, лабораторный тест и т.п.) и INDEX (число в диапазоне 1-5, которое является показателем важности данного проявления).
В ходе выполнения первых трех этапов формируется "суперструктура" базы знаний, т.е. в общих чертах определяется ее схема — диапазон категорий и уровень анализа каждой категории. На последующих трех этапах сформированная структура базы знаний наполняется содержимым. Введенные значения показателей причинности и частотности позволяют программе манипулировать в дальнейшем с "вескостью" свидетельств в пользу или против определенной гипотезы.
На шаге 7 программа определяет проявления для нетерминальных узлов, представляющих области заболеваний, анализируя степень их общности для дочерних узлов более низких уровней иерархии. Например, разлитие желчи является проявлением целой группы заболеваний печени, которая объединяется областью гепатитные заболевания.
Целесообразность такого обобщения проявлений объясняется следующим образом. Как уже не раз подчеркивалось ранее, пространство диагностируемых категорий для пациентов, страдающих несколькими заболеваниями, оказывается чрезвычайно большим. Вследствие этого на практике не удается применить в этом пространстве обычные методы поиска, такие как поиск в глубину. Нужно каким-то способом "свернуть" пространство поиска или сфокусировать усилия программы на определенной области пространства и таким образом добиться приемлемой скорости поиска.
Проблема скорости поиска не стояла бы с такой остротой даже при наличии у пациента нескольких заболеваний, если бы существовали более прямые ассоциативные связи между заболеваниями и их проявлениями, т.е. если бы определенное проявление сразу позволило врачу прийти к заключению о наличии определенного заболевания. Такие отношения в медицинской литературе называются патогенетическими, и они действительно существуют, но, к несчастью, значительно реже, чем нам хотелось бы. Хуже всего то, что патогенетические отношения характерны для тех проявлений, которые могут быть выявлены только в процессе сложных лабораторных исследований или хирургическим путем.
Установить же достаточно жесткие связи между определенными проявлениями и целой группой заболеваний (областью заболеваний в терминологии программы INTERNIST) удается гораздо чаще.
Такое проявление, как разлитие желчи, жестко связано с областью заболеваний печени, а кровохаркание — с областью легочных заболеваний. Программа INTERNIST использует связи на верхних уровнях дерева для "сужения" пространства поиска. При этом начальная точка поиска как бы переносится на более низкие уровни иерархии в пространстве заболеваний и уже оттуда начинается выполнение процедуры поиска в глубину.
В используемой Поплом терминологии сужение (constrictor) для конкретного случая диагноза — это нахождение во множестве известных проявлений "намека", в какой области пространства заболеваний находятся правдоподобные гипотезы. Однако не следует забывать, что такое сужение является эвристическим, а потому не гарантирует на все сто процентов, что искомое заболевание находится именно в определенной таким способом области. Хотя на верхних уровнях иерархии и могут существовать проявления, прямо связанные с определенной областью, другие проявления остаются только более предпочтительными для одной области и менее предпочтительными, но отнюдь не невозможными, для другой. При этом ситуация еще более ухудшается по мере перехода на более низкие уровни иерархии.
Из всего сказанного следует, что то упорядочение проявлений, которое выполняется на этапе 7, позволяет консультационной программе начинать диагностическую процедуру на том уровне иерархии, на котором начинают проявляться патогенетические отношения, и отсеивать таким образом целые классы заболеваний.
На этапе 8 обрабатываются свойства самих проявлений, что в процессе работы программы скажется на эффективности выполнения функций на стратегическом уровне. Например, свойство TYPE позволяет судить о том, насколько велики будут затраты на получение того или иного показателя или насколько процесс его получения будет опасен для здоровья пациента, а эту информацию следует учитывать при назначении уточняющих анализов. Свойство IMPORT позволяет принять решение, нельзя ли проигнорировать данное проявление в контексте определенного заболевания.Обратите внимание на то, что на этапах 5 и 8 используется довольно неформализованное представление неопределенности в суждениях. Но в дальнейшем мы увидим, что основной причиной появления проблем в процессе работы с системой INTERNIST является неудовлетворительная формулировка структуры пространства поиска, а не недостаточная точность исходных данных.
Ниже, в разделе 13.4, мы рассмотрим, как отражается использование в программе INTERNIST иерархической структуры дерева гипотез на методике извлечения знаний при опросе экспертов.
Проблемы, обнаруженные в процессе эксплуатации системы INTERNIST
В общих чертах программа INTERNIST работает следующим образом. На начальном этапе данные о пациенте вводятся в любом порядке, при этом объем данных значения не имеет. Далее программа приступает к первому шагу решения задачи дифференциального диагностирования — формируется первичный набор гипотез, который может включать как области заболеваний (т.е. нетерминальные узлы дерева заболеваний), так и конкретные заболевания (терминальные узлы). Если какая-либо из отобранных гипотез объясняет наличие важных проявлений из числа тех, которые наблюдаются у пациента, то этой гипотезе "начисляются" поощрительные очки. Если из гипотезы следует, что у пациента должно быть определенное проявление заболевания, а в действительности оно не наблюдается, то гипотеза "наказывается" штрафными очками. В списке гипотез, отсортированном по сумме набранных оценок, два элемента считаются конкурирующими в том случае, если их объединение не объясняет никаких новых проявлений, которые не могли бы быть объяснены любой из этих гипотез по отдельности. Определив набор альтернатив, программа таким образом формулирует задачу дифференциации. Далее программа "сосредоточит внимание" на множестве гипотез, в которое входят наиболее правдоподобная гипотеза и ее конкуренты.
Однако следует подчеркнуть, что INTERNIST в действительности не использует тот простой алгоритм иерархического построения и проверки гипотез, который в общих чертах был описан в разделе 13.1. Это объясняется тем, что симптомы, которые активизируют определенный нетерминальный узел в дереве заболеваний, могут быть также существенны и для других узлов. Таким образом, программа не может предполагать, что заболевание, которым страдает пациент, должно быть найдено только среди дочерних узлов активизированного нетерминального узла. Так, хотя симптомом холеры (cholestasis) и является разлитие желчи (jaundice), существуют и другие заболевания, никакого отношения к холере не имеющие, которые могут иметь такой же симптом, например группа алкогольных гепатитов (alcoholic hepatitis).
Таким образом, хотя основная идея построения дерева заболеваний состоит в том, что соседние узлы в иерархии должны соответствовать заболеваниям или группам заболеваний с общими симптомами, программе приходится часто рассматривать гипотезы из достаточно разнородных областей заболеваний.
В этом и состоит основная проблема при решении задачи диагностирования с помощью INTERNIST. В одной из своих работ Попл указал на то, что на практике использованные в программе эвристические методы управления процессом логического вывода иногда оставляют без внимания важные данные о состоянии пациента, а отдают предпочтение менее существенным с точки зрения специалистов-практиков [Pople, 1982]. Поскольку сходимость процесса поиска не совсем соответствует той идеальной картине, которая была описана выше, это приводит к серьезному затягиванию интерактивного процесса диагностирования в сложных случаях, так как на начальной стадии программа отдала предпочтение неконструктивной гипотезе. Так, результаты клинических анализов исследования различных органов пациента, если рассматривать их по отдельности, заставляют программу "распылять" внимание в нескольких направлениях. Опытный клиницист постарается интегрировать имеющиеся данные на ранних стадиях диагностирования и сосредоточиться на какой-либо одной ключевой гипотезе. Таким образом, оказывается, что схема управления процессом логического вывода, реализованная в программе INTERNIST, на практике оказывается слишком упрощенной по сравнению с моделью рассуждений, используемой опытным врачом.
Как показал опыт эксплуатации систем PUFF и CENTAUR, при работе в ограниченной предметной области, т.е. в случае, когда диагностируется довольно жестко очерченный круг заболеваний, описанная стратегия оказывается вполне приемлемой. Проблемы возникают при расширении предметной области. Нельзя сказать, что при этом метод оказывается вообще неработоспособным, поскольку программа INTERNIST все-таки справляется с довольно сложными случаями, но врачи отмечают, что при этом она иногда демонстрирует довольно странный путь поиска решения.
Попл пришел к выводу, что базовая стратегия иерархического построения и проверки гипотез нуждается в дополнении новыми структурами знаний, которые представляли бы сведения о подходящем структурировании множества альтернатив, известных опытным клиницистам. Он отметил, что в нынешней базе знаний программы INTERNIST знания о возможных конкурирующих заболеваниях представлены недостаточно полно, нужно провести дальнейшие исследования целесообразности использования различных стратегий управления логическим выводом после того, как задача дифференциального диагностирования сформулирована, в частности разработать наиболее удачные критерии отсеивания гипотез.
Если воспользоваться терминологией Кленси (см. главу 12), то в решении проблем, связанных с медицинской диагностикой, имеются структурный и стратегический аспекты, которые не представлены явно ни в организации пространства гипотез, ни в организации процедур конструирования и решения задач дифференциального диагностирования.
Рабочая срединженерии знаний TDE
TDE [Kahn et at, 1987] представляет собой среду разработки для комплекса инструментальных средств создания экспертных систем TEST [Pepper and Kahn, 1987]. Последний ориентирован прежде всего на решение проблем классификации, к которым, в частности, относится и задача диагноза. Название системы TEST— аббревиатура от Troubleshooting Expert System Tool (комплекс инструментальных средств для построения экспертных систем поиска неисправностей), а название системы TDE — аббревиатура от TEST Development Environment (среда разработки TEST). При создании этих программ был использован подход, существенно отличающийся как от подхода при разработке программ MYCIN/EMYCIN (см. главу 10), так и от подхода, использованного при разработке программ MUD/MORE (см. главу 12).
Основным элементом представления знаний является структурированный объект, а не порождающее правило. (Для разработки TDE был использован язык описания фреймов Knowledge Craft.)
Объекты представляют понятия, тесно связанные со способом мышления специалистов по поиску и устранению неисправностей. Такие абстрактные понятия, как гипотезы и симптомы, заменены конкретными— вид отказа (failure mode) и тестовая процедура (test procedure), смысл которых будет объяснен ниже.
Свои знания пользователи вводят в систему, манипулируя пиктограммами (в этом смысле процедура ввода знаний напоминает использованную в системе OPAL (см. главу 10)).
Представление знаний имеет ярко выраженный процедуральный аспект. Например, в представлении знаний тестовые процедуры связаны с видами отказов в дополнение к вычислению степени уверенности в правдоподобности гипотезы, которая рассматривается как функция от наблюдаемых симптомов.
Вид отказа, пожалуй, самое важное понятие в TEST и TDE: оно означает любое отклонение в поведении объекта при тестировании — от полной неработоспособности до отклонений в функционировании какого-нибудь малозначительного компонента. Так, если речь идет об обслуживании автомобиля, то "двигатель не заводится" — это типичный вид отказа, но "разряжена аккумуляторная батарея" — это тоже один из видов отказа.
В традиционных экспертных системах нужно было различать, чем является разряд аккумуляторной батареи, — гипотезой об источнике неисправности, которая следует из первичных данных, или симптомом, представленным в составе первичных данных. Для системы TEST это разделение не имеет такого существенного значения, как для системы MUD или MYCIN. При организации знаний в TEST использованы и другие концепции:
процедуры тестирования и ремонта неисправностей (отказов);
представление в явном виде причинно-следственных связей между отказами.
Виды отказов в системе организованы в древовидную структуру, в которой корневой узел, как правило, представляет неисправность всего устройства (составного объекта), а терминальные узлы (листья дерева)— неисправности конкретных компонентов устройства (простейших объектов). Нетерминальные узлы представляют отклонения или неисправности при выполнении отдельных функций, например "нет освещения". Между корнем дерева и терминальными узлами может находиться довольно много уровней нетерминальных узлов.
Как и в системах CENTAUR и INTERNIST, это дерево неисправностей в TEST является скелетом базы знаний. Следующий уровень структуризации составляют процедуры выполнения тестирования и устранения неисправностей и различные виды правил, представляющих процедуральные знания, связанные с видами отказов. К ним относятся знания о том, какие измерения нужно выполнить для подтверждения неисправности, как устранить ее, как отыскать компонент, неисправность которого может быть причиной данного отказа, и т.п. И, наконец, существует еще и третий уровень структуризации декларативных знаний, который представлен множеством атрибутов, связанных с узлами отказов. Эти атрибуты описывают разнообразные свойства компонентов, имеющих отношение к определенной неисправности, а также связи между компонентами.
Хотя в структуре базы знаний системы TEST и не используются такие традиционные понятия, как гипотезы и симптомы, все же можно говорить о том, что работа системы построена на базе метода эвристической классификации.
Узлы отказов, расположенные ближе к корню дерева, представляют абстрактные категории данных, а те, что ближе к листьям, — абстрактные категории решений (рис. 13.3). Задача программы— построить цепочку причинно-следственных связей от узлов отказов верхних уровней, например "двигатель не заводится", до терминальных узлов вроде "разряжена аккумуляторная батарея". Отображение абстрактных категорий данных на абстрактные категории решений состоит из двух типов отношений между узлами отказов в дереве — из-за (due-to) и всегда_приводит_к (always-leads-to). Эвристики представляются на программном уровне в виде подключенных к узлам дерева правил, которые направляют процесс поиска узлов более нижних уровней.
TDE является сравнительно новой системой, которую можно считать существенным шагом вперед по сравнению с системой MORE. К сожалению, когда эта книга готовилась к печати, у нас не было возможности опробовать эту систему на практике, но кое-какие тенденции в ее конструкции просматриваются довольно четко. Например, совершенно очевидно, что графический интерфейс предоставляет пользователю гораздо большую свободу при построении базы знаний, чем символьный интерфейс системы MORE. Для новичков в системе предусмотрена опция переключения на режим вопросов и ответов. В этом режиме система задает пользователю вопросы и последовательно "ведет" его через три стадии описания знаний, которые были описаны чуть выше. Опытный пользователь может отказаться от такого режима и вводить информацию, необходимую для представления знаний, в той последовательности, которую считает наиболее целесообразной.
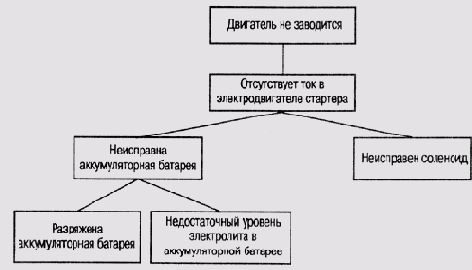
Рис. 13.3. Иерархическая организация узлов отказов в системе TEST
Сравнивая системы MORE и TDE, можно прийти к заключению, что даже в том случае, когда в экспертной системе используется один определенный метод решения проблем, например метод эвристической классификации, может существовать несколько методик извлечения и структурирования знаний. Многое в этом процессе еще не ясно, предстоит еще много работы по сравнению разных методик, но тот опыт, который уже получен при разработке и эксплуатации систем типа MORE и TDE, дает значительный экспериментальный материал для дальнейшего теоретического осмысления и обобщения.
Рекомендуемая литература
Подробное описание программы INTERNIST и исследований, выполненных в процессе работы над этой программой, читатель найдет в работе [Pople, 1982]. Но не все идеи, описанные в этой статье, были реализованы в готовой системе и не все декларированные принципы были соблюдены при ее разработке. Архитектура системы GENTAUR была успешно использована для построения экспертных систем, не имеющих отношения к медицине. В частности, эта архитектура использована в системе REX, консультирующей статистиков при выполнении регрессионного анализа [Gale, 1986]. В работе этого же автора [Gale, 1987] описана программа извлечения знаний Student, созданная для работы в той же предметной области, что и Rex. В этой системе использованы некоторые принципы, опробованные в системе OPAL, в частности во главу угла поставлены знания, а не определенная стратегия решения проблем, принятая в данной проблемной области.
В работе [Мшеп et al, 1995] описан опыт переделки программы INTERNIST с помощью набора инструментальных средств PROTEGE (о последнем см. в [Musen, 1989] и [Rothenfluket al., 1994]). Комплекс PROTEGE во многом сходен с CommonKADS. В нем объединена1 онтологическая оболочка, подобная реализованной в системе OPAL, с обобщенным методом решения проблем [Puerto et al., 1994].
Структурфреймов в CENTAUR
Основная идея, положенная в основу системы CENTAUR, состоит в том, что фреймо-подобные структуры обеспечивают явное представление предметной области, которое может быть использовано для формирования суждений с помощью порождающих правил. Такое описание предметной области позволяет разделить стратегические знания о том, как управлять процессом формирования суждений, и ситуационные знания о том, какой вывод можно сделать из имеющегося набора фактов. Теоретически это позволит отделить ситуационные знания, специфичные для конкретной предметной области, а значит, создать систему, которую можно будет приспособить для работы в разных областях.
При таком подходе порождающие правила могут быть просто включены в структуру фрейма в качестве значения одного из слотов. Связывание правил со слотами фрейма создает возможность организации единого механизма функционирования правил на основе естественного группирования. Другие слоты в данном фрейме образуют в явном виде контекст применения правила.
В CENTAUR используются три типа фреймоподобных структур: прототипы, компоненты и факты. Из 24 прототипов двадцать один представляет определенные заболевания органов дыхания, один — знания, общие для всех заболеваний этого вида, а еще два — знания, в определенной мере независимые от предметной области. Это знания о том, как запустить консультирующую программу и просмотреть имеющиеся свидетельства. Таким образом, знания организуются вокруг самих диагностических категорий. Альтернативный вариант, используемый в большинстве других систем, — заложить эти знания в неявной форме в набор неструктурированных правил.
Прототипы в программе CENTAUR содержат знания и объектного, и метауровня. Из них организована сеть, фрагмент которой представлен на рис. 13.1. Верхний уровень иерархии занимает прототип CONSULTATION (консультация), который управляет всеми стадиями процесса проведения консультаций (ввод исходных данных, активизация гипотез и т.п.). Затем следует слой прототипов, представляющих определенные патологические состояния, такие как RESTRCTIVE LUNG DESEASE (легочные заболевания), OBSRTUCTIVE AIRWAYS DESEASE (заболевания верхних дыхательных путей) и т.п.
И на самом нижнем уровне категории заболеваний разделяются, во-первых, на конкретные заболевания, а во-вторых, по степени остроты. Так, категория заболеваний верхних дыхательных путей (OBSRTUCTIVE AIRWAYS DESEASE) может быть разделена на подкатегории MILD (мягкие), MODERATE (умеренные), MODERATELY SEVERE (умеренной остроты) и SEVERE (острые). А конкретные виды заболеваний, представленные на этом уровне, — ASTHMA (астма), BRONCHITIS (бронхит) и EMPHYSEMA (эмфизема).
Каждый прототип имеет слоты для некоторого набора компонентов, которые содержат указатели на субфреймы знаний на объектном уровне. В каждом прототипе заболеваний органов дыхания существуют слоты, представляющие результаты анализов легких, причем каждый из этих слотов также является фреймом с собственными правами и собственной внутренней структурой. Например, фрейм OBSRTUCTIVE AIRWAYS DESEASE (заболевания верхних дыхательных путей) включает 13 компонентов, каждый из которых имеет собственное наименование, характеризуется диапазоном допустимых значений и степенью (мерой) важности. В дополнение к этому фрейм компонента часто содержит специальный слот, называемый "inference rules" (правила вывода), в котором хранятся порождающие правила формирования логического вывода на основе значения этого компонента. Если компонент не содержит такого рода правил или правило по каким-либо причинам не может обработать значение компонента, программа обращается с вопросом к пользователю. Такую меру предосторожности в отношении набора правил можно рассматривать как процедурную связь определенного вида. Процедурная связь обычного вида потребовала бы включение в программу довольно значительного по объему фрагмента LISP-кода.
Факты, с которыми работает программа, представляются фреймами, каждый из которых имеет шесть слотов. В них содержится информация о наименовании параметра, его значении, степени достоверности, источнике, классификации и обоснованности.
Помимо знаний, специфичных для предметной области, в прототипах имеется и управляющий слот. В нем представлены знания метауровня о том, как использовать этот структурный элемент знаний.Этот слот содержит LISP-выражения, предназначенные для
конкретизации прототипа— установки множества компонентов, значения которых должны быть определены;
реагирования на подтверждение или отклонение прототипа; реакция программы заключается в том, что задается множество прототипов, которые следует активизировать на следующем шаге;
вывода сообщения, в котором приводится окончательное заключение.
Каждый управляющий слот можно рассматривать как консеквентную часть правила, условная часть которого сопоставима с ситуацией, описанной компонентами прототипа.
Структурированные объекты в CENTAUR
Для того чтобы понять алгоритм работы программы CENTAUR, нужно хотя бы в общих чертах представлять себе ту предметную область, на которую ориентирована эта программа. CENTAUR выполняет практически те же задачи, что и разработанная ранее система PUFF (см. [Кит et al, 'I978J, [Aikins et al., 1984]}. Система PUFF предназначалась для диагностики нарушения работы дыхательных органов. В качестве исходных данных, как правило, использовались результаты анализа объема выдыхаемого воздуха и скорость движения воздуха при выдохе (этот анализ выполняется с помощью спирографа).
в системе CENTAUR? Какие функции
1. Что понимается под прототипом в системе CENTAUR? Какие функции возлагаются на прототипы?
2. В чем преимущества смешанного способа представления знаний в системе CENTAUR?
3. Что представляет собой модель заболевания в системе INTERNIST? Объясните смысл концепции доминантности применительно к модели заболеваний в системе INTERNIST.
4. Какие проблемы обнаружились при работе над системой INTERNIST и как они соотносятся с проведенным Кленси анализом различных видов знаний?
5. Выполнение этого упражнения потребует некоторых познаний в медицине — знаний о физическом смысле некоторых параметров, измеряемых при лабораторных анализах органов дыхания. (Лично я узнал о них от д-ра Джереми Уатта (Jeremy Wyatt) и д-ра Патриции Твидейл (Patricia Tweedale). Любые фактические ошибки в приведенном ниже описании прошу отнести на мой счет, но думаю, они не повлияют на смысл самого упражнения.)
При диагностике легочных заболеваний используются следующие параметры, измеряемые при лабораторном обследовании пациентов.
Index0.htm FEV1 (Forced Expiratory Volume). Объем форсированного выдоха за 1 секунду, измеренный в литрах. Измеряется количество воздуха, выдыхаемого пациентом в течение 1 секунды. Этот параметр является показателем эластичности легочных тканей (а следовательно, и их здоровья).
Index0.htm IFV1. Показатель изменения FEV1 после курса лечения с применением бронхолитиков.
Index0.htm FVC (Forced Vital Capacity). Жизненная емкость легких - объем вдыхаемого воздуха при максимальном наполнении легких.
Index0.htm IFVC. Показатель изменения FVC после курса лечения с применением бронхолитиков.
Index0.htm TLC (Total Lung Capacity). Общая емкость легких.
Index0.htm RV (Residual Volume). Остаточный объем легких - объем воздуха, который остается в легких после максимального выдоха.
Index0.htm RATI01 = FEV1/FVC.
Index0.htm RATI02 = FEV1/FVC после курса лечения с применением бронхолитиков.
Ниже в постановке задачи переменная PRED означает ожидаемое значение любого из перечисленных выше параметров. (Ожидаемое значение медицинского параметра зависит главным образом от пола пациента.) Выражения вида
Влияние сложности пространствгипотез норганизацию работы системы
Такие системы, как MYCIN, имеют дело с отдельной, очень специфической частью проблемной области (в данном случае — медицины). В частности, система MYCIN диагностирует только заболевания крови. Поскольку пространство состояний в системах, подобных MYCIN, достаточно ограничено, в них можно использовать метод исчерпывающего поиска в глубину.
А что делать, если мы собираемся построить экспертную систему, имеющую дело со всеми возможными заболеваниями, а не только с отдельным специфическим классом? Количество различных заболеваний, известных врачам на сегодняшний день (диагностических категорий), лежит, по разным оценкам, в диапазоне от двух до десяти тысяч. Нужно также учитывать, что существуют пациенты, у которых обнаруживается до десятка заболеваний одновременно. Как отметил Попл (Pople), в худшем случае программе, использующей обратную цепочку рассуждений, придется при диагностировании таких пациентов проанализировать около 1040 диагностических категорий!
Именно в тех системах, в которых пространство решений потенциально может быть очень большим, и проявляются преимущества метода иерархического построения и проверки гипотез. Пространство поиска в таком случае может рассматриваться как дерево, представляющее таксономию типов решений. Узлы более верхних уровней дерева соответствуют более широким (а потому менее четко очерченным) категориям решений, чем узлы более нижних уровней. Терминальные узлы дерева соответствуют совершенно конкретным решениям. При такой организации пространства решений процесс уточнения гипотез значительно упрощается, поскольку структура пространства решений может быть использована для формирования эвристик управления последовательностью анализа.
На рис. 13.1 показана часть иерархической систематики заболеваний, которая используется в системе CENTAUR. Корневым узлом этого фрагмента являются ЗАБОЛЕВАНИЯ_ ОРГАНОВ_ДЫХАНИЯ, а все последующие узлы — различные виды таких заболеваний. Следующий уровень узлов представляет наиболее общие категории заболеваний органов дыхания, а терминальные узлы (листья) — конкретные заболевания, которые можно диагностировать и в дальнейшем лечить.
Естественно, если таким образом представить медицинские знания обо всех возможных болезнях, то дерево очень сильно "разрастется". В системе INTERNIST организация дерева привязана к основным органам — легким, печени, сердцу и т.п. Хотя иерархическая организация и помогает выполнять поиск, она не устраняет проблему отыскания наилучшего объяснения имеющегося набора данных (симптомов). Для этого необходимо объединять гипотезы об отдельных болезнях и добиваться, чтобы в такой комбинированной гипотезе были учтены все признаки и симптомы, обнаруженные у пациента.
Рис. 13.1. Иерархическое представление заболеваний органов дыхания
Методика вариативного построения гипотез и их проверки оказывается особенно полезной в тех случаях, когда
ассоциативные связи между свидетельствами и "терминальными" гипотезами слабые, а ассоциативные связи между исходными данными и "нетерминальными" гипотезами достаточно сильные, и существуют методы уточнения построенных гипотез и их разделения;
в полном наборе правил имеется большая избыточность, т.е. значительная часть условий одновременно включена во множество правил и таким образом связывается с множеством различных заключений;
система спроектирована с расчетом на явное представление пространства гипотез, которым можно манипулировать, причем на любом этапе работы может существовать множество конкурирующих гипотез, которые нельзя анализировать независимо;
не все условия можно одинаково легко сформулировать либо из-за сложности сопутствующих вычислений, либо вследствие факторов стоимости и риска; таким образом, оказывается, что процесс накопления свидетельств сам по себе представлен в пространстве состояний и к нему нужно применять некоторые методы логического вывода;
возможны множественные и частичные решения, например пациент может страдать несколькими заболеваниями, либо для проведения лечения вполне достаточно знания класса заболеваний или основных альтернативных заболеваний.
Один из этапов подхода, использованного в CENTAUR, состоит в том, что просматривается, насколько полно представление гипотетического заболевания совпадает с имеющимися данными (симптомами, показаниями и т.п.).
Узлы в дереве представления гипотез активизируются имеющимися данными, конкретизируются, оцениваются и упорядочиваются по степени "накрытия" имеющихся фактов. Узлы, "получившие" наиболее высокие оценки, включаются в список заявок и в дальнейшем анализируются более подробно. В первом приближении этот анализ сводится к выяснению, насколько имеющиеся симптомы соответствуют каждому из дочерних узлов. Последовательно применяя такую процедуру анализа, программа в конце концов формирует список терминальных узлов с достаточно высокими оценками степени соответствия имеющимся данным.
13.1. Обход дерева
В самых общих чертах алгоритм выполнения иерархического построения и проверки гипотез (НАТ-алгоритм) может быть представлен следующим образом. Предположим, имеется дерево гипотез, которые могут быть активизированы на основе части имеющихся данных. Активизированные гипотезы предполагают наличие и других данных, помимо тех, что были использованы для их отбора, которыми мы можем располагать или которые можно дополнительно затребовать.
НАТ-алгоритм
(1) Считать исходные данные.
(2) Для каждой исследуемой гипотезы сформировать оценку, которая показывает, какая часть исходных данных учитывается этой гипотезой.
(3) Определить ту гипотезу (узел) л, которая имеет наивысшую оценку.
(4) Если п— терминальный узел, то завершить выполнение алгоритма. В противном случае выделить в пространстве гипотез два подпространства К и L Подпространство К должно содержать дочерние узлы п, а подпространство L — узлы-конкуренты п на том же уровне дерева.
(5) Собрать дополнительные данные, которые можно использовать для анализа гипотез в подпространстве К, и провести оценку гипотез на основе этих дополнительных данных. Пусть k— наивысшая оценка гипотез из К, а l— наивысшая оценка гипотез из L
(6) Если k выше, чем /, то положить п = k. В противном случае положить n = /.
(7) Перейти к п. 4.
Формирование суждений с учетом ограничений: метод Match
Для иллюстрации использования ограничений в системе R1 рассмотрим, как выполняется подзадача 3), конфигурирование модулей расширения шины UNIBUS в шкафах и блоках.
Основная сложность решения проблемы "распределения по закромам" состоит в том, что, как правило, не удается найти подходящий способ поиска в пространстве состояний, поскольку отсутствует подходящая оценочная функция для сравнения частичных конфигураций. Другими словами, отсутствует формула, которую можно было бы применить для того, чтобы сказать, что такая-то конфигурация лучше некоторой другой. Система функциональных и пространственных связей сама по себе является единым сложным объектом, и невозможно по отдельному ее фрагменту заранее сказать, приведет ли данный путь к удовлетворительному решению или нет. Это можно сделать, только получив определенные характеристики системы в целом, например показатели ее симметричности, которые влияют на избыточность.
В контексте подзадачи 3) существует ряд ограничений, которые можно использовать для унификации поиска решения.
Каждый модуль UNIBUS требует размещения на генплате ответного разъема подходящего типа.
Каждая генплата в шкафу должна быть размещена таким образом, чтобы все подключенные к ней модули пользовались одними и теми же блоками питания.
Выходная мощность каждого блока питания ограничена и не зависит от количества слотов на генплате.
Если модулю необходимо выделить пространство на панели управления, это можно сделать только на панели того шкафа, в котором размещен модуль.
Некоторые модули требуют для своей работы подключения других модулей, которые должны размещаться либо в одном блоке с обслуживаемым модулем, либо подключаться к той же генплате.
Существует оптимальная последовательность подключения модулей к шине UNIBUS, которая влияет на назначение модулям приоритетов прерываний и на скорость передачи информации по шине. Желательно размещать модули таким образом, чтобы их конфигурация как можно меньше отличалась от оптимальной.
Как правило, существует и ограничение на объем внутреннего пространства в шкафах системы. В результате, сказать о том, приемлема определенная конфигурация или нет, можно только после того, как на шине будут размещены все модули системы. Поэтому иногда система R1 вынуждена формировать несколько вариантов компоновки модулей, прежде чем будет найдена приемлемая.
Хотя система R1 и формирует иногда несколько вариантов решения одной и той же задачи, в ней никогда не выполняется обратное прослеживание. Иными словами, в ней никогда не формируется промежуточный вариант решения, к которому затем можно вернуться и отменить. На любой стадии процесса решения задачи система располагает достаточными знаниями для того, чтобы сделать следующий шаг. Использование обратного прослеживания потребовало бы значительных вычислительных ресурсов, особенно ресурсов оперативной памяти. К тому же при использовании обратного прослеживания пользователю очень сложно понять ход рассуждений, который привел к предлагаемому варианту решения.
Для основной проблемы в том способе решения проблемы, который использован в системе R1, разработчики выбрали наименование "Match" (сопоставление), которое вносит некоторую путаницу в смысл проблемы. Любые системы, основанные на применении правил, в той или иной мере используют сопоставление, но разработчики системы R1 придали термину Match (начинающемуся с прописной буквы "М") несколько иной смысл. Вместо того чтобы формировать набор решений-кандидатов и затем выбирать из них подходящий, как это делается в системе DENDRAL (см. главу 20), программа, использующая метод Match, на каждой стадии процесса "распознает", что ей делать дальше.
Метод Match можно рассматривать как метод поиска экземпляра, который означивал бы (конкретизировал) определенную "форму", — символическое выражение, содержащее переменные. Примером такой формы может служить левая часть выражения порождающего правила. Таким образом, пространством поиска для метода Match является "пространство всех означиваний переменных в форме" [McDermott, 1982, а, р. 54]. Каждое состояние в этом пространстве соответствует частично означенной форме.
Существуют формы, которые заключают в себе знания, специфические для данной предметной области, касающиеся удовлетворения ограничений. Именно с ними при решении данной частной проблемы и имеет дело метод Match. Мак-Дермот указал на два условия, которые нужно удовлетворить для того, чтобы можно было использовать для отыскания решения этот довольно "слабый" метод поиска.
Соответствие условий. При сравнении конкретизированного экземпляра с образцом должна существовать возможность определить значение переменной на основе ограниченной информации локального характера. Применительно к системе R1 это означает возможность на любой стадии пользоваться только той информацией, которая доступна в рамках текущего контекста. Решение не должно зависеть от информации, доступной в каких-либо других контекстах ("дочерних" или "братских"), как бы близко к текущему они ни находились в иерархии контекстов. Это не означает, что контексты должны быть независимы; просто последующие сопоставления не должны использовать те, которые были выполнены раньше.
Однонаправленное распространение условий. Применение какого-либо оператора должно сказываться только на тех компонентах решения, которые до сих пор не были определены. Другими словами, применение какого-либо оператора не должно давать никаких побочных эффектов, которые могли бы повлиять на уже сформированные компоненты решения. Само название условия говорит о том, что последствия применения операторов должны распространяться только в одном направлении — от текущего контекста к "дочерним" и еще не проанализированным "соседним", но не в обратном направлении, — к "родительским" контекстам.
Мак-Дермот разделил все правила системы R1 на три категории в зависимости от их отношения к методу Match.
(1) Правила применения операторов, которые формируют и модифицируют частичную конфигурацию.
(2) Правила установки последовательности, которые указывают порядок принятия решений, используя для этого в основном текущий контекст.
(3) Правила накопления информации, которые организуют обращение к базе данных компонентов и отвечают за выполнение разнообразных вычислений "по заказу" других правил.
Выше уже отмечалось, что использование понятия контекста при решении задачи синтеза конфигурации в определенной мере соответствует тому способу мышления, который близок эксперту-человеку. Однако попытка рассмотреть понятие контекста с точки зрения формальных вычислений не предпринималась. Если же обратиться к методу Match, то ситуация становится в определенной мере обратной. Человек-эксперт при решении аналогичной задачи не использует ничего, подобного этому методу. Скорее он склонен к эвристическому поиску в той или иной форме, что само по себе часто приводит к использованию обратного прослеживания. Преимущество использования метода Match с точки зрения затрачиваемых вычислительных ресурсов несомненно, и в этом ему следует отдать предпочтение перед методом эвристического поиска при разработке программ решения тех задач, где метод Match можно применить.
Использование текущего контекстдля управления структурой задачи
Помимо информации о компонентах и ограничениях, в рабочей памяти системы R1 содержатся также символические структуры, определяющие текущий контекст вычислительного процесса. Это помогает разделить задачу конфигурирования на подзадачи. В первом приближении можно считать, что каждой такой подзадаче соответствует активизация определенной группы правил. Более того, эти подзадачи можно организовать, в иерархическую структуру с временными отношениями между ними и таким образом наложить на задачу конфигурирования структуру, в чем-то схожую с планом.
Другими словами, главная задача, скажем "разработать конфигурацию модулей VAX-11/780 соответственно данному заказу", может быть разбита на ряд подзадач, например "проверить корректность заказа", "подобрать компоненты в соответствии с заказом (возможно, ранее скорректированным)". Выполнение этих двух задач приведет к выполнению главной задачи. Естественно, что порядок выполнения подзадач не может быть произвольным, — вряд ли кому-то придет в голову сначала подобрать компоненты в соответствии с заказом, а потом проверять, не допущена ли в заказе ошибка.
Программа R1 разбивает задачу конфигурирования на шесть подзадач, каждая из которых, в свою очередь, может быть разбита на более мелкие подзадачи.
(1) Проверить заказ, уточнить все пропущенные в нем сведения и исправить замеченные ошибки.
(2) Включить в конфигурацию модуль центрального процессора, все компоненты, непосредственно связанные с центральным процессором, и определить состав блоков основной стойки комплекса.
(3) Включить в конфигурацию модули расширения шины UNIBUS, определить состав блоков в стойке расширения интерфейса.
(4) Включить в конфигурацию генпанели, распределить их между стойками и связать с блоками расширения интерфейса и обслуживаемыми устройствами.
(5) Составить план расположения стоек, распределить блоки периферийных устройств между стойками с учетом длин связей.
(6) Разработать схему соединения стоек и выбрать типы кабелей.
По отношению к порядку выполнения подзадач эта иерархическая схема может быть либо детерминированной, либо недетерминированной. Если в пределах подзадачи на любую заданную глубину порядок выполнения операций фиксирован, то говорят, что используется детерминированный анализ задач. В противном случае — допустимы отклонения в последовательности выполнения подзадач на любом уровне — считается, что используется недетерминированный анализ задач.
В системе R1 детерминированный анализ используется только в отношении части задач, которые всегда выполняются в одном и том же порядке. Достигается такое упрощение следующим образом. Множество правил в R1 служит просто для управления символами контекста — теми элементами рабочей памяти системы, которые несут информацию о текущем положении системы в иерархии задач. Одни правила этой группы определяют условия, при которых нужно инициировать новую подзадачу, — при этом в рабочую память добавляются новые символы контекста, а другие правила распознают, закончилось ли выполнение подзадачи, и удаляют символы контекста из рабочей памяти. Все остальные правила содержат элементы условий, анализирующие символы контекста, а потому они выполняются только в том случае, если "активен" соответствующий контекст. Чтобы разобраться в том, как работает этот механизм на практике, нужно остановиться хотя бы вкратце на стратегии разрешения конфликтов, используемой в R1.
Каждый символ контекста содержит имя контекста, например "подсоединение_источника_питания", символ, который несет информацию о том, активен данный контекст или нет, тэг времени, который несет информацию о том, как давно контекст был активизирован. Правила, которые распознают, когда должна быть запущена на выполнение новая подзадача, используют с этой целью текущее состояние частичной конфигурации. Те правила, в условной части которых имеется соответствующий символ контекста, получают более высокий приоритет в цикле "распознавание состояния — действие".
Общепринято размещать условия распознавания контекста в самом начале антецедентной части порождающего правила. В результате, если это условие не соблюдается, не тратится время на анализ остальных. Кроме того, стратегия разрешения конфликтов в системе R1 (она получила название ME А) обращает особое внимание на первое условие в правиле после его конкретизации перед возможным применением. У правил, которые деактивизируют контекст, антецедентная часть состоит из единственного символа контекста. Такое правило будет применено только после всех остальных правил, чувствительных к тому же контексту. Это пример использования стратегии специфики. Следуя этой стратегии, система R1 сначала выполняет все действия, связанные с определенным контекстом, а уже после этого изменяет его.
Основная эвристика специфики состоит в следующем. Если существуют два конфликтующих правила Rule 1 и Rule 2 и условия, специфицированные в правиле Rule 2, являются подмножеством условий, специфицированных в правиле Rule 1, то правилу Rule 1 дается более высокий приоритет, чем правилу Rule 2. Можно и по-другому рассматривать эту эвристику. Правило Rule 2 является более "общим", чем правило Rule 1, и оно обрабатывает по умолчанию те случаи, которые не "охватываются" более специализированным правилом Rule 1. При этом фактически правило Rule 1 имеет дело с исключениями из общего правила Rule 2, поскольку в нем принимаются во внимание дополнительные условия (рис. 14.1).
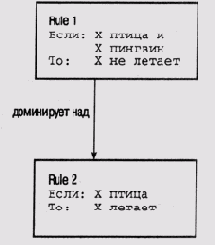
Рис. 14.1. Пример применения стратегии специфики: правило Rule 1 доминирует над правилом Rule 2
В языке OPS5 (а также в CLIPS) эвристика специфим Машина логического вывода частично упорядочивает кон в качестве критерия упорядочения количество проверок правилах. В частности, выполняется анализ соответствия констант или переменных заданным значениям. Доминировать будут те правила, для которых потребуется наибольшее количество проверок. В любом случае применение стратегии МЕА помогает упорядочить применение правил, сделать его более или менее регулярным.
Мак-Дермот (McDermott) конкретизировал использование контекстов состояния применительно к задаче формирования конфигурации вычислительной системы. Он считает, что этот способ довольно хорошо передает подход к решению аналогичных задач экспертом-человеком. Нужно, однако, отметить, что система R1 не располагает реальными знаниями о свойствах контекста, с которым имеет дело. Имена контекста— это только некоторые символические обозначения, в отличие от компонентов, с которыми связаны все виды атрибутов и значений. Следовательно, система R1 не может "рассуждать" о контекстах так же, как она "рассуждает" о компонентах или ограничениях. Система просто распознает состояние, когда ей необходим новый контекст или когда завершены все операции, связанные с данным контекстом.
14.1. Стратегии разрешения конфликтов LEX и МЕА
В главе 5 были упомянуты стратегии разрешения конфликтов LEX и МЕА, реализованные в языке CLIPS. Ниже будет в общих чертах рассмотрена реализация стратегии МЕА, которая использована в системе R1/XCON.
Как было показано в главе 3, анализ "средство — анализ результата" является абстрактным режимом формирования цепочки обратного логического вывода в случае, когда определена некоторая цель. Этот режим позволяет выбрать операторы или правила, которые способны сократить "расстояние" между текущим и заданным целевым состоянием проблемы. Несложно показать, как этот режим можно использовать в контексте порождающей системы с обратной стратегией логического вывода, например MYCIN, когда весь процесс начинается с цели самого верхнего уровня общности (см. главу 3). В системах, использующих прямой логический вывод, которые строятся на основе языковых средств OPS5 или CLIPS, применяется стратегия разрешения конфликтов МЕА. Основанный на ней режим управления позволяет программе "продвигаться" по неявно заданному дереву целей, которые представлены специальными лексемами в рабочей памяти экспертной системы.
Алгоритм МЕА включает пять шагов.
Напомним, что конфликтующее множество правил включает те конкретизированные правила, которые должны быть активизированы в течение одного и того же цикла вычислений. Конкретизация правила представляет собой совокупность обобщенной формулировки правила и значений используемых в нем переменных .
(1) Исключить из конфликтующего множества те правила, которые уже были применены в предыдущем цикле. Если после этого множество стало пустым, прекратить процесс.
(2) Сравнить "новизну" элементов в рабочей памяти, которые соответствуют первым элементам условий в конкретизированных правилах, оставшихся в конфликтующем множестве. Приоритет отдается тем правилам, которые обращаются к самым "свежим" элементам рабочей памяти,— эти правила "доминируют" над остальными. Если существует единственное такое правило, то оно выбирается для применения, после чего процесс должен быть прекращен. В противном случае, если имеется несколько доминирующих правил с
равным приоритетом, они сохраняются в конфликтующем множестве, а прочие из него удаляются. Далее выполняется переход к шагу (3).
(3) Упорядочить конкретизированные правила по "новизне" остальных элементов условий в правилах. Если доминирует единственное правило, оно применяется и затем процесс прекращается. Если же доминируют два или несколько правил, то они остаются в конфликтующем множестве, а остальные удаляются из него. Затем выполняется переход к шагу (4),
(4) Если по критерию "новизны" элементов условий отобрано несколько правил с равными показателями, то сравнивается другой показатель правил — показатель специфики. Предпочтение отдается тому правилу, применение которого требует проверки наибольшего количества условий в рабочей памяти. Если "претендентов" окажется несколько, остальные удаляются из конфликтующего множества и выполняется переход к шагу (5).
(5) Применяется правило, выбранное произвольным образом из оставшихся в конфликтующем множестве, и процесс прекращается.
Таким образом, стратегия МЕА объединяет в едином алгоритме анализ таких показателей, как повторяемость, новизна и специфика. Алгоритм LEX практически идентичен алгоритму МЕА за одним исключением — в нем отсутствует шаг 2), а на шаге 3) сравниваются все элементы условий конкретизированных правил и связанных с ними элементов рабочей памяти. Первые элементы условий, которые использовались на шаге 2), являются, как правило, лексемами задач в рабочей памяти (в главе 5 приведен пример программы, которая манипулирует такими лексемами).
Использование знаний, развитие и расширение системы XCON
В этом разделе мы рассмотрим, какие особенности использования знаний существуют в системе XCON, как эта система совершенствовалась и расширялась. Система XCON выбрана в качестве примера по той простой причине, что процесс приобретения и расширения знаний в этой системе довольно подробно описан в доступной автору документации, чего нельзя сказать о множестве других экспертных систем. Совершенно очевидно, что три эти темы — извлечение знаний, совершенствование и расширение возможностей экспертной системы — тесно связаны. Проблема извлечения знаний применительно к системе XCON осложняется тем, что для решения задачи конфигурирования вычислительной системы требуются самые разнообразные знания. Но не нужно забывать о том, что углубленный анализ применяемых методов решения проблемы может в определенной мере упростить задачу извлечения необходимых знаний, как это было продемонстрировано в главах 11-13.
Извлечение знаний в системе RXCON
В работе [McDermott, 1982, а] содержится множество интересных наблюдений о том, как выполняется начальная фаза извлечения знаний для системы R1.
У экспертов имеется достаточно четкое, систематическое представление о том, как разбить основную задачу на подзадачи, и о том, какие отношения существуют между этими подзадачами.
При решении сформулированных подзадач, однако, поведение экспертов определяется не столько общими принципами, сколько исключениями из них, например "при выполнении подзадачи S выполнять алгоритм X, пока не будет выполнено условие У". Можно считать, что в процессе решения подзадач поведение эксперта в основном направляется событиями.
Такая систематичность в выявлении отношений между подзадачами и несистематичность решения отдельных подзадач при реализации на языке OPS5 приводит к использованию контекстов и специальных случаев. Раздельное уточнение правил и контекстов обеспечивает модульный характер коррекции ошибок в поведении системы на начальном этапе ее разработки. Однако в работе [McDermott, 1988] Мак-Дермот обратил внимание на то, что различные виды знаний не всегда хорошо различимы в рамках решения одной подзадачи. В частности, в составе правил можно встретить два класса знаний:
знания о разных способах расширения частичной конфигурации;
знания о том, какой из возможных вариантов расширения следует выбрать.
Бачан ([Bachant, 1988]) присоединился к мнению Кленси ([Clancey, 1983]) и других, ратовших за более обобщенный подход к этой проблеме. В частности, предлагалось использовать явные средства управления режимом выполнения правил. Сторонники этого подхода обращали внимание на то, что разрешение конфликтов выполняется на очень низком уровне иерархии задач, хотя можно было бы его использовать для декомпозиции в пределах задач. В новом методе, названном RIME (аббревиатура от Rl's Imlicit Made Explicit — то, что в R1 было неявным, сделано явным), была предпринята попытка найти оптимальное соотношение между слишком жестким и слишком мягким режимами управления последовательностью выполнения операций.
Основной метод решения проблем в системе R1 можно отнести к виду предложи-и-примени (propose-and-apply), который состоит из следующих шагов.
(1) Инициализация цепи. Формируется элемент управления для текущей задачи и удаляются все устаревшие элементы управления для тех задач, которые уже завершены.
(2) Предложение. Предлагаются возможные варианты дальнейших действий и отвергаются неприемлемые варианты. Варианты представляются в виде операторов.
(3) Удаление лишнего. Удаляются лишние операторы в соответствии с глобальным критерием, например заранее определенным приоритетом операторов.
(4) Разрешение конфликтов. Выполняется попарное сравнение конкурирующих операторов и принимается решение, какой из двоих оставить.
(5) Выбор единственного оператора. Анализируется результат выполнения шагов 2—4 и из всех оставшихся операторов выбирается единственный.
(6) Применение оператора. Выбранный оператор применяется к текущему состоянию проблемы и таким образом формируется расширение частичной конфигурации.
(7) Оценка цели. Проверяется, не достигнута ли сформулированная цель. Если цель достигнута, процесс завершается, в противном случае цикл повторяется.
Итак, как следует из анализа, выполненного Бачаном, слабый метод (Match) использует в процессе выполнения более строгий метод (предложи-и-примени). Этот подход в чем-то аналогичен использованию эвристической классификации (строгий метод) для формирования подцелей (слабый метод) в системе MYCIN.
Несколько позже Мак-Дермот (см. [McDermott, 1988]) назвал такие более строгие методы, которые используются в сочетании с более слабыми, "role-limiting methods" (методами с ограничением роли). Методы этой группы характеризуются видом тех управляющих знаний, которые используются для выявления, отбора и применения действий, выполняемых системой. При этом предполагается, что существует группа задач, для которых использование определенной части управляющих знаний может считаться независимым от специфики предметной области.
Таким образом, можно считать, что методы с ограничением роли— это такие "методы, которые строго направляют процесс накопления и представления знаний". Хотя это определение и нельзя признать достаточно строгим, в нем выражена главная идея — некоторый метод можно отнести к группе методов с ограничением роли в том случае, если те управляющие знания, которые, как правило, используются этим методом, не очень тесно связаны со спецификой решения задачи. Можно, конечно, возразить, что в таком случае метод эвристической классификации, который используется в MYCIN, также относится к этой группе, если не обращать внимание на тот факт, что в MYCIN используются нарождающие правила.
Справедливо, однако, утверждение, что некоторая часть экспертных систем может содержать управляющие знания менее абстрактного характера, т.е. знания, так или иначе связанные с объектами определенной предметной области и отношениями между ними. Мак-Дермот, в частности, процитировал одно из правил системы R1/XCON, которое приведено ниже.
ЕСЛИ
два действия-кандидата суть
включить в систему НМД RA60,
включить другой тип НМД,
который использует тот же тип корпуса,
ТО
отдать предпочтение на следующем шаге включению в систему НМД RA60.
ЕСЛИ
два действия-кандидата суть
включение в систему устройства, монтируемого на генпанели, тип которого
не RV20A или RV20B,
включение в систему другого устройства, монтируемого на генпанели, тип которого не RV20A или RV20B, и не выбран шкаф, и существует шкаф, в который можно вставить устройство, и желательно разместить первое устройство в шкафу перед тем, как размещать в нем второе устройство,
ТО
отдать предпочтение на следующем шаге включению в систему первого устройства.
Первое правило можно обобщить, если известно, почему предпочтительнее сначала иметь дело с НМД типа RA60. А вот второе правило кажется очень тесно связанным со спецификой размещения устройств отдельных типов в шкафах и их взаимной компоновкой. Более того, в этом правиле использованы отношения между объектами предметной области, которые можно отнести к разным уровням абстракции.Мак-Дермот обратил внимание на то, что тот вид суждений, который представлен в таких правилах, будет меняться от одной области применения системы к другой, а следовательно, его не удастся обобщить.
Компоненты и ограничения
Хотя и R1, и MYCIN являются программами, использующими в своей работе порождающие правила, между ними имеется ряд серьезных отличий. Одно из них состоит в том, что в MYCIN процесс решения проблемы направляется гипотезами (hypothesis-driven), т.е. процесс начинается с формулировки определенной цели, а затем она преобразуется в набор подцелей, совместное достижение которых позволяет достичь главной цели (см. об этом в главе 3). В системе R1 главным является подход, предполагающий, что процесс решения направляется данными (data-driven). Сначала программа определяет множество компонентов и далее пытается сконструировать такую конфигурацию этих компонентов, которая удовлетворяла бы ограничениям, вытекающим как из характеристик отдельных компонентов, так и из отношений и связей между ними. Для реализации программы был использован язык OPS5, один из первых языков представления правил, прямой предшественник языка CLIPS.
Для успешной работы программа R1 нуждается в знаниях двух видов:
о характеристиках компонентов — электрических (напряжение питания, потребляемая мощность, параметры выходных сигналов и т.п.), механических (габариты, тип и количество разъемов), структурных (количество портов) и т.п.;
об ограничениях, накладываемых на "совместимость" компонентов, — правилах формирования частичных конфигураций и их расширения.
Знания о компонентах хранятся в базе данных отдельно как от памяти системы порождающих правил, так и от рабочей памяти транзитных элементов данных. Таким образом, база данных имеет статическую структуру, в то время как рабочая память является динамической, В отличие от памяти порождающей системы, которая организована в виде набора модулей, управляемых по определенной схеме, база данных состоит из записей обычной структуры, которые для каждого компонента хранят информацию о его классе, типе и множестве характеристик. Например, ниже представлен фрагмент записи о контроллере накопителя на магнитных дисках типа
RK611
CLASS: UNIBUS MODULE
TYPE: DISK DRIVE
SUPPORTED: YES
PRIORITY LEVEL: BUFFERED NPR
TRANFER RATE: 212
Знания об ограничениях сохраняются в виде правил в памяти продукционной системы программы R1. Левая часть правил описывает условия (ситуацию), при соблюдении которых возможно расширение частичной конфигурации, а правая часть описывает, как выполняется расширение. В начале сеанса работы с системой рабочая память пуста, а в конце сеанса в ней содержится описание сформированной конфигурации. Компоненты в этом описании представлены в виде лексем, имеющих вид векторов, состоящих из элементов "атрибут-значение". С информацией, хранящейся в базе данных компонентов, система R1 может выполнять пять видов операций: генерировать новую лексему, отыскивать лексему, отыскивать подстановку для заданной лексемы, извлекать атрибуты, связанные с заданной лексемой, и извлекать шаблон, который в дальнейшем должен быть заполнен.
Помимо лексем компонентов, рабочая память содержит элементы, которые представляют частичные конфигурации оборудования, результаты вычислений и символьное описание текущей задачи.
Система R1 хранит порядка 10 000 правил, значительная часть которых определяет, какое следующее действие должна выполнить программа. Пример одного из таких правил приведен ниже.
DISTRIBUTE-MB-DEVICES-3
ЕСЛИ: предыдущим активным контекстом является расширение количества
устройств, подключаемых к шине .MASSBUS
& имеется однопортовый НМД, не подключенный к MASSBUS
& отсутствуют двухпортовые НМД, еще не подключенные к MASSBUS
& количество устройств, которое можно подключить к расширителю MASSBUS,
известно
& существует расширитель MASSBUS, к которому подключен по крайней мере
один НМД и который может
поддерживать дополнительные НМД
& известен тип кабеля, которым должен быть связан НМД с ранее установленным устройством
ТО: подключить НМД к MASSBUS
Такие управляющие знания о предметной области (domain-specific control knowledge) позволяют программе R1 принимать решение о том, с чего начинать и как расширять структуру комплекса, не используя при этом сложной процедуры поиска.Как мы увидим далее, программа R1, как правило, не нуждается в обратном прослеживании неудовлетворительных решений, которое можно было бы использовать для отмены сформированной частичной конфигурации и замены ее новой.
Использованные в R1 управляющие знания малочувствительны к очередности применения отдельных правил. Этим она отличается от систем, в которых общая задача конфигурирования решается разделением на подзадачи и выбором групп правил, соответствующих определенной подзадаче. В результате процесс решения проблемы в R1 направляется последовательностью правил, активизированных последними. Как будет показано в следующем разделе, для упрощения реализации такой стратегии используются некоторые из средств разрешения конфликтов, которые имеются в языке OPS5.
Области применения методов
конструктивного решения проблем
Методы конструктивного решения проблем применяются в экспертных системах, которые используются для планирования, проектирования и некоторых видов диагностирования.
В системах планирования элементами решения являются некоторые операции, а решения — это последовательности операций, которые приводят к намеченной цели. Ограничения чаще всего связаны с естественными отношениями объектов в пространстве и времени, например два объекта не могут занимать одно и то же пространство в одно и то же время, один и тот же человек не может выполнять одновременно два вида работ и т.п.
В задачах конструирования элементами решения являются компоненты, а решения— суть комбинации этих компонентов, которые образуют сложный объект, удовлетворяющий определенным физическим ограничениям, вытекающим из свойств материалов компонентов, или определенным эстетическим соображениям.
При диагностировании множественных неисправностей элементами решения являются отдельные неисправности, а решением — множество неисправностей, которое "экономно накрывает" все наблюдаемые симптомы неправильного функционирования объекта. Таким образом, одним из ограничений может служить стремление так сформировать множество возможных неисправностей, чтобы в нем исключался многократный учет одних и тех же симптомов.
В каждом из этих случаев невозможно заранее сформировать множество решений. Существует слишком много вариантов комбинаций отдельных операций, или компонентов сложной конструкции, или совместимых неисправностей. Более того, операции могут взаимодействовать друг с другом, компоненты конкурировать за пространство или возможность подключения друг к другу, а отдельные неполадки переплетаться самым причудливым образом, учитывая возможные причинные связи между ними.
Относительно простые случаи каждой из перечисленных задач вполне могут решаться методами классификации. Например, в главе 10 мы рассматривали систему ONCOCIN, которая формировала план лечения онкобольных, выбирая из библиотеки заготовки возможных вариантов.
Выбранный вариант нуждался в дальнейшем только в конкретизации дозировок и расписания приема препаратов. Более сложные проблемы таким способом решить не удается, поскольку объем библиотеки заготовок пришлось бы сделать слишком большим. Для таких случаев единственно возможным становится конструктивный подход, который позволяет более гибко строить и модифицировать набор примитивных операций в формируемом плане действий.
В главе 2 уже отмечалось, что стремление решить задачу планирования "в лоб" выбором из пространства возможных решений неизбежно наталкивается на проблему экспоненциального взрыва при усложнении задачи и соответствующем расширении пространства решений. Это не является серьезным препятствием в том случае, когда существует довольно много удовлетворительных решений задачи и мы не слишком озабочены их качеством. Тогда и ненаправленный поиск позволяет за разумное время найти приемлемое решение. Но если желательно отыскать оптимальное или близкое к оптимальному решение, ненаправленный поиск даже при использовании чрезвычайно мощного компьютера чаще всего оказывается обреченным на неудачу. Для эффективного решения таких задач требуются знания о том, как ограничить "обследуемое" пространство решений и сфокусировать поиск именно на тех его элементах, которые образуют искомый результат.
В следующем разделе мы рассмотрим один из вариантов конструктивного метода, который получил название Match. Этот вариант дает хорошие результаты в тех случаях, когда имеющихся знаний о предметной области достаточно для того, чтобы на любой стадии вычислений определить верное направление дальнейших действий. Тогда появляется возможность использовать для решения проблем методику "предложи и попробуй", в которой основной упор сделан на выборе правильного оператора расширения частичного решения. В главе 15 будет показано, что этот метод не является универсальным, пригодным для решения любых конструктивных проблем, но в тех случаях, когда его можно применять, результаты оказываются намного лучше, чем при использовании выбора из библиотеки частичных решений.
Рекомендуемая литература
Процесс разработки и модернизации системы R1/XCON достаточно подробно отражен в технической литературе, однако назвать единственный источник, в котором можно было бы найти все детали этого проекта, затруднительно. Хорошей отправной точкой для знакомства с этим проектом может послужить работа [McDermott and Bachant, 1984]. Рекомендуется обратить внимание еще на одну совместную разработку университета Карнеги—Меллон и фирмы Digital Equipment— систему XSEL ([McDermott, 1982,bJ, [McDermott, 1984]}. Это программа, написанная на языке OPS5, которая помогает клиентам фирмы выбрать компоненты вычислительного комплекса VAX и разместить элементы комплекса в производственном помещении.
Весьма интересный анализ сильных и слабых сторон методов с ограничением роли выполнен в работе [Мшеп, 1992], которую рекомендуется прочесть вслед за статьей Мак-Дермота [McDermott, 1988]. В работе [Studer et al, 1998] обсуждаются как методы с ограничением роли, так и порождающие задачи, причем в качестве примера при обсуждении концепций используются системы CommonKADS и PROTEGE-II.
Решение проблем конструирования (I)
14.1. Области применения методов конструктивного решения проблем
14.2. Система R1/XCON
14.3. Использование знаний, развитие и расширение системы XCON Рекомендуемая литература
Упражнения
В конце главы 11 отмечалось, что отличительной чертой методов решения проблем конструирования является формирование решения из более примитивных компонентов. Этим методы решения задач конструирования отличаются от методов, применяемых для задач классификации, когда решение выбирается из некоторого фиксированного множества. В следующих двух главах будут описаны методы искусственного интеллекта, которые можно использовать для решения проблем конструирования, и на примерах, взятых из различных источников, продемонстрировано, как эти методы реализуются на практике.
Когда речь идет о решении некоторой проблемы конструирования, предполагается, что имеется пространство элементов решения, из которого можно выбирать, и имеются правила, которые помогают комбинировать выбранные элементы. Самым простым примером является задача, которую приходится решать чуть ли не ежедневно, — как одеться, чтобы не выглядеть в родной конторе пугалом. Существуют писаные и неписаные правила, в чем прилично являться на работу, а что рассматривается как пренебрежение мнением окружающих (и руководства). Итак, задача состоит в том, чтобы, во-первых, не выглядеть пугалом, а во-вторых, не вносить диссонанс в рабочую обстановку слишком вызывающим внешним видом. Даже в том случае, если отсутствуют четко сформулированные правила, вряд ли кто-нибудь посчитает совместимым костюм-тройку и кроссовки.
Можно рассматривать задачу решения проблемы конструирования и в терминах ограничений — сформировать такое решение, которое удовлетворило бы некоторым общим требованиям к качеству и при этом не противоречило бы ни одному из специальных правил, отвергающих определенные элементы решения или их комбинации.
СистемR1/XCON
14.2. Система R1/XCON
Система R1 была одной из первых успешных попыток применения экспертных систем в промышленности в начале 1980-х годов [McDermott, 1980], [McDermott, 1981], [McDermott, 1982,а]. Эта система предназначена для помощи разработчикам при определении конфигурации вычислительной системы на базе вычислительных устройств и блоков семейства VAX. Сначала программа проверяет полноту спецификации требований к проектируемой системе, которая представлена заказчиком. На втором этапе программа определяет конфигурацию системы, соответствующую этим требованиям. Коммерческая версия системы, разработанная совместно университетом Карнеги—Меллон и корпорацией Digital Equipment, получила наименование XCON. При описании истории разработки мы иногда будем обращать ваше внимание на отличия между начальным проектом и его коммерческой версией.
Первым практическим применением системы XCON была разработка конфигурации вычислительного комплекса VAX-11/780 на заводе фирмы DEC в Салеме, шт. Нью-Гемршир. Затем последовала разработка конфигураций других типов вычислительных комплексов, таких как VAX-11/750 и последующих модификаций продукции DEC. Наш интерес к этой экспертной системе объясняется тем, что она продемонстрировала, чего можно достичь при использовании даже относительно слабого метода решения проблем, если имеется достаточно знаний о предметной области. История развития этой системы также показывает, как расширяется сфера применения коммерческой экспертной системы при правильном менеджменте и как системы такого типа "врастают" в производственную среду.
Задачу системы R1 нельзя отнести к типу тривиальных. Типовой вычислительный комплекс включает 50-100 компонентов, главными из которых являются центральный процессор, устройство управления оперативной памятью, блоки управления интерфейсом по шинам UNIBUS и MASSBUS, причем все эти компоненты подключены к единой плате синхронизации. Шинные интерфейсы поддерживают обмен с широкой номенклатурой периферийных устройств — устройствами внешней памяти на магнитных лентах и дисках, принтерами и т.п.
В результате имеется возможность строить системы самой различной конфигурации.
Получив заказ со спецификацией характеристик вычислительного комплекса, система R1 должна принять решение о том, какие устройства нужно включить в состав комплекса и как их объединить в единую систему. Принять решение о том, соответствует ли определенная конфигурация тем характеристикам, которые представлены в заказе, не так просто, поскольку для этого нужно обладать знаниями о возможностях и характеристиках всех компонентов и отношениях между разными компонентами. Не менее сложна и задача оптимальной компоновки комплекса из выбранного набора компонентов, поскольку при ее решении нужно принимать во внимание множество ограничений на взаимное расположение компонентов в структуре комплекса. Например, подключение модулей расширения UNIBUS к устройству синхронизации требует учитывать ограничения по токовой нагрузке, существующие для устройства синхронизации, и распределение приоритетов прерываний для подключаемых модулей расширения. Таким образом, задачу выбора конфигурации можно с полным правом считать классической конструктивной проблемой, которая требует для своего решения значительного объема экспертных знаний.
Совершенствование и расширение системы RXCON
Как уже отмечалось ранее (см. главу 3), совершенствование экспертной системы в процессе ее опытной эксплуатации — это отдельная, достаточно сложная тема для обсуждения. В процессе разработки системы оценка ее будущей производительности зачастую бывает весьма туманной. Понятно, что программа должна выполняться за разумное время и на первых порах справляться с типовыми для данной предметной области случаями, в частности с теми, которые использовались для извлечения знаний в процессе интервью с экспертами. Но стоит задуматься и над тем, чтобы разработать тест или набор тестов, которые позволят оценить реальную производительность системы и выявить те случаи, когда она достигает максимума.
В тех областях, где формализация затруднена или невозможна, вряд ли удастся когда-либо представить убедительное доказательство того, что данная система действительно является экспертом в некотором отвлеченном смысле. Свидетельство может быть только эмпирическим и включать диапазон возможных ситуаций, с которыми справляется программа. Для любого нетривиального применения этот диапазон должен быть достаточно широким. Несмотря на то что программа XCON на сегодняшний день обработала десятки тысяч заказов, считается, что просмотрена только малая часть пространства возможных вариантов.
По словам Мак-Дермота, на начальной стадии эксплуатации системы R1 предполагалось, что она сможет стать действительным помощником разработчика только после того, как будет справляться примерно с 90% всех поступающих заказов, т.е. сформированные программой по этим заказам компоновки вычислительной системы будут не хуже тех, которые проектируются опытным специалистом. Для того чтобы достичь такого уровня совершенства, с программой R1 пришлось повозиться почти три года, но опыт показал, что начальные требования к "изобретательности" системы были завышенными. Программа была признана пользователями вполне работоспособной и полезной еще до того, как достигла такого высокого уровня совершенства, поскольку качество ее работы не уступало качеству работы рядового специалиста.
Проектирование конфигураций относится к тому классу задач, который редко решается каким-либо специалистом в одиночку. Как правило, одному специалисту для этого не хватает ни знаний, ни времени. Поэтому помощь, которую оказывала система R1 в решении этой задачи, была весьма кстати.
Можно ли считать решающим критерием сравнение результатов, полученных экспертной системой, с теми, которые получают эксперты в этой же предметной области? Вопрос этот не так прост, как кажется на первый взгляд. Помимо того, что в нем скрыта проблема выбора подходящих тестов, существует еще и проблема адекватного сравнения результатов. Система R1 дает более детальное решение этой задачи, чем человек-эксперт. Последний оставляет многие детали на усмотрение персонала, непосредственно занятого монтажом системы. Можно ли сравнивать проект, созданный экспертной системой, с результатами работы не только инженера-проектировщика, но и техников, монтирующих систему? Нужно принять во внимание еще и следующий нюанс. При монтаже системы техники имеют возможность экспериментировать с компоновкой в определенных пределах, а программа этой возможности лишена. Таким образом, сравнение будет не совсем корректным.
Добавление в экспертную систему новых знаний также не является тривиальной проблемой. Во-первых, новые знания добавляются в систему уже на стадии отладки тех знаний, которые были введены в первоначальный вариант системы. Во-вторых, существуют и другие причины, требующие включения новых знаний на протяжении всего жизненного цикла системы.
(1) Требуется ввод знаний о более широком классе объектов, с которыми должна иметь дело система. Например, может потребоваться проектировать конфигурации новых типов вычислительных систем.
(2) Могут потребоваться новые знания, улучшающие качество решения путем включения новых подзадач. Например, в случае задачи компоновки можно включить подзадачу размещения панелей управления на шкафах комплекса.
(3) Возникла необходимость расширения формулировки основной задачи системы.
Например, первоначальный вариант системы R1 предполагал выполнение компоновки только однопроцессорных вычислительных комплексов, а затем возникла идея поручить этой системе и задачу компоновки многопроцессорных комплексов.
Как показывает опыт работы с системой R1, процесс расширения возможностей системы продолжается до тех пор, пока не завершится ее жизненный цикл. Предметная область вычислительных систем находится в постоянном движении — появляются новые компоненты (устройства) с новыми свойствами, которые по-разному сочетаются друг с другом и с ранее разработанными компонентами. Поэтому в экспертной системе и база данных, и рабочая память находятся в состоянии постоянного изменения. Более того, жизненный цикл системы можно уподобить погоне за движущейся целью, что делает и так непростые ее задачи еще более сложными.
Опыт работы с XCON показал, что непрерывное внесение изменений в систему приводит к определенной ее избыточности. Другими словами, если не предпринимать специальных мер противодействия, то уровень беспорядка в развивающейся системе будет постоянно нарастать. Построение новой системы с самого начала — это слишком дорогое удовольствие как в смысле материальных затрат, так и в смысле времени. Эти ресурсы гораздо целесообразнее направить на разработку средств, облегчающих расширение возможностей существующей системы. Вряд ли существует однозначный ответ на этот вопрос. Грамотный разработчик экспертных систем должен решать эту задачу, принимая каждый раз во внимание конкретные обстоятельства создания и область назначения именно данной системы. Читателям, интересующимся, как решили эту проблему разработчики системы XCON, мы советуем ознакомиться с врезкой 14.2.
В следующей главе будут рассмотрены две другие системы, предназначенные для конструктивного решения проблем, в которых использована более сложная стратегия управления. Дело в том, что в некоторых приложениях экспертных систем не соблюдается описанное в разделе 14.2.3 соответствие условий. Другими словами, не всегда удается на основании локальной информации определить, какая операция должна быть выполнена на следующем шаге, поскольку на текущее состояние задачи не наложены достаточные ограничения.
В такой ситуации можно попытаться принять решение таким образом, чтобы оставались открытыми дополнительные возможности, или подготовиться к возможной отмене принятого решения, если позже обнаружится нарушение заданных ограничений. Будет показано, что такая стратегия серьезно усложняет процесс решения, но часто удается справиться с этими трудностями, привлекая на помощь знания из предметной области.
14.2. Совершенствование системы XCON
В течение 1986-1987 годов система XCON подверглась коренной модернизации на основе методологии RIME. Принцип нисходящего разложения проблемы на подзадачи (последние получили в новой терминологии наименование пространства системы— problem spaces) в процессе вычислений, который был реализован в системе R1, остался в неприкосновенности, но была изменена система классификаций правил. За основу новой системы классификации были взяты этапы выполнения алгоритма предложи-и-примени, на которых используется то или иное правило. Каждое пространство проблемы представляет относительно независимую подзадачу и специфицируется тремя параметрами:
управляющая структура, которая описывает метод решения проблем, применяемый в этом пространстве;
знания, которые используются для принятия решения о том, какое пространство проблемы должно быть активным в любой данный момент времени;
операторы, которые позволяют манипулировать объектами в данном пространстве, если оно становится активным.
Таким образом, за каждым пространством проблемы закрепляются правила типов предложение, удаление лишнего и т.д., чем достигается определенная систематизация представления знаний из системы R1. Однако главная особенность такой организации в том, что она обеспечивает применение более систематического подхода к извлечению необходимых знаний. В частности, она позволяет извлекать знания, специфичные для каждой подзадачи, на что обращал внимание Мак-Дермот.
Возвращаясь к системе R1/XCON тремя годами позже, Мак-Дермот отметил, что из опыта ее эксплуатации и модернизации нужно извлечь три урока [McDermott, 1993].
Работа с R1/ XCON продемонстрировала важность управляющих знаний, специфичных для определенной предметной области. Обладая достаточными знаниями о том, что делать дальше, программа способна в процессе выполнения сложной задачи определить очередную операцию, пользуясь только локальной информацией.
Система, основанная на порождающих правилах, обеспечивает необходимый механизм уточнения и расширения знаний. В частности, это касается знаний об ограничениях, свойственных каждой подзадаче, и о том, какое подмножество всех возможных операций доступно для конкретной подзадачи. Когда такие отношения превалируют между подзадачами, менее вероятно, что добавление новых правил будет каким-либо образом влиять на уже имеющиеся, относящиеся к прежним задачам.
Для того чтобы экспертная система была признана полезной, она должна не только правильно выполнять возложенные на нее в первоначальном проекте задачи. Интеграция программ, подобных R1, в производственную систему является не менее важным фактором успеха всей разработки, что, как правило, со пряжено с преодолением множества трудностей организационного и даже психологического характера.
Таким образом, модернизация системы XCON вполне оправдала затраты. Конечно, этот вывод нельзя распространять на любую экспертную систему. Для небольших систем вполне может подойти и старое доброе правило "пока оно работает, не трогай его",
и проектирования не всегда могут
1. Почему проблемы планирования и проектирования не всегда могут быть решены с помощью методов классификации? При соблюдении каких условий методы классификации могут быть использованы для решения проблем этих классов?
2. Что представляет собой метод Match? Какие "условия соответствия" должны быть соблюдены для того, чтобы этот метод сработал?
3. В чем состоит стратегия специфики, применяемая для разрешения конфликтов, и как она реализована в системе R1?
4. Детально опишите использование контекста в процессе работы системы R1. "Понимает" ли сама система используемую в ней стратегию решения проблемы нисходящим уточнением?
5. Что представляет собой "пространство проблемы" в методологии RIME и какую роль оно играет?
6. В чем преимущество использования более явного представления стратегии, реализованного при модернизации системы XCON?
7. Подумайте, как можно автоматизировать решение следующей задачи проектирования конфигурации. Эта задача достаточно сложна, чтобы не считаться тривиальной, но, конечно же, значительно уступает по сложности задаче проектирования конфигурации вычислительного комплекса.
Описание задачи. Пользователь системы желает скомпоновать музыкальный комплекс, в состав которого должны входить электрогитара, усилитель и педали звуковых эффектов. Задача экспертной системы — помочь пользователю выбрать вариант комбинации компонентов, которые обеспечат желаемое качество звучания.
Данные и знания. Данные, передаваемые в систему, должны включать следующие параметры:
музыкальный жанр, на который ориентируется пользователь (джаз, блюз, рок и т.д.);
стиль игры (ритмический, с медиатором и т.д.);
предпочтительная тональность ("жирный" или "тонкий" звук, "сладкий" или более резкий и т.п.);
"образцы для подражания", стилю игры которых следует пользователь (например, Клептон, Бек, ван Хален и т.д.);
сумма, которой располагает пользователь для покупки каждого из основных компонентов.
Постарайтесь отыскать среди своих знакомых заядлого гитариста и "вытянуть" из него необходимые знания. Рассматривайте это упражнение, в первую очередь, как упражнение на проектирование.
Анализ задачи. Используйте тот же вид анализа задачи, который мы применяли в отношении системы R1, т.е. разложение задачи на подзадачи. Отправной точкой может послужить И/ИЛИ-дерево, приведенное на рис. 14.2. Постарайтесь либо построить систему на определенную глубину дерева, либо сделать ее более специализированной, "разрисовав" подробнее одно из поддеревьев, выбор усилителя или гитары.
Организуйте детерминированный просмотр дерева программой в процессе решения задачи и выполняйте его сверху вниз и слева направо. Наиболее важное решение, которое должна принять программа, — выбор гитары. Поэтому сначала завершите эту задачу, а затем переходите к выбору усилителя. Естественно, сначала нужно выбрать изготовителя и модель, а уже потом тип струн и прочих аксессуаров.
Рис. 14.2. Дерево анализа задачи проектирования конфигурации музыкального комплекса
Мы выделили две категории усилителей — транзисторные и ламповые. Хотя усилители обеих категорий могут работать с гитарами любого типа, все же ламповые усилители предпочтительнее для одних стилей исполнения и музыкальных жанров, а транзисторные — для других. Еще одно соображение нужно принимать во внимание. Некоторые модели усилителей имеют встроенные средства создания звуковых эффектов, например реверберации или хорового исполнения. При выборе таких моделей соответственно должны быть скорректированы требования к педалям дополнительных эффектов. Выбор набора педалей зависит, естественно, от предпочтительных музыкальных жанров и стилей исполнения.
