Программа CHEF
22.1.1. Программа CHEF
Для демонстрации возможностей экспертной системы, базирующейся на прецедентах, рассмотрим систему CHEF, которая предназначалась для формирования кулинарных рецептов [Hammond, 1986]. Эта программа принимает информацию о целевых характеристиках блюда (тип, вкусовые качества, своеобразие) и формирует подходящий рецепт. Например, программа может получить следующий "заказ":
блюдо из баранины (beef);
включает брокколи (broccoli);
использует поджаривание (stir-fry);
блюдо должно получиться хрустящим (crisp).
Заказ оформляется в виде выражения на специальном формальном языке:
dish(beef), include(broccoli), method(stir-frv), texture(crisp)
Результатом работы программы должен быть рецепт— последовательность операций, позволяющая приготовить такое блюдо.
Получив заказ, программа просматривает свою базу прецедентов, отыскивает в ней рецепт приготовления аналогичного блюда и адаптирует его в соответствии с особенностями текущего заказа (проблемы). Например, если в базе уже имеется рецепт для баранины с зеленым горошком, его можно скопировать и вместо горошка вставить брокколи. Этим, правда, адаптация не исчерпывается, поскольку горошек варится, а не жарится, как указано в заказе. Раз блюдо будет жариться, значит, брокколи придется сначала измельчить (если бы нужно было варить, то качанчики брокколи можно было бросать в воду целиком), следовательно, первоначальный план придется дополнить еще одной операцией. Кроме того, если кусочки баранины и броколли жарить вместе, то броколли, вероятно, пропитается соком. Значит, в системе нужно иметь правило, которое определит этот факт и изменит первоначальный простой план, — предложит сначала обжарить брокколи, а затем вынуть их.
На рис. 22.1 представлена упрощенная схема той части программы CHEF, которая имеет отношение к манипуляциям с базой прецедентов.
Методы извлечения и адаптации прецедентов
22.1.2. Методы извлечения и адаптации прецедентов
В системах формирования суждений на основе прецедентов используются разные схемы извлечения прецедентов и их адаптации к новым проблемам.
В таких программах, как CHEF, сопоставляются описания имеющихся прецедентов и полученная спецификация цели, причем в качестве основного средства сопоставления выступает семантическая сеть (см. главу 6). В примере, рассмотренном в предыдущем разделе, модулям извлечения и модификации известно, что и брокколи, и зеленый горошек — это свежие овощи. Модуль извлечения использует эту информацию для вычисления оценки степени близости прецедента и целевой спецификации, а модуль модификации использует эту же информацию для подстановки в рецепт одного ингредиента вместо другого. Это фоновое знание играет весьма существенную роль в решении обеих задач.
Сложность поиска решения и выявления различий между прецедентами в значительной степени зависит от используемых термов индексации. По сути, прецеденты в базе прецедентов конкурируют, пытаясь "привлечь" к себе внимание модуля извлечения, точно так же, как порождающие правила конкурируют за доступ к интерпретатору. В обоих случаях необходимо использовать какую-то стратегию разрешения конфликтов. С этой точки зрения прецеденты должны обладать какими-то свойствами, которые, с одной стороны, связывают прецедент с определенными классами проблем, а с другой — позволяют отличить определенный прецедент от его "конкурентов". Например, в программе CHEF прецеденты индексируются по таким атрибутам, как основной ингредиент блюда, гарнир, способ приготовления и т.п., которые специфицируются в заказе.
Механизм сопоставления должен быть достаточно эффективным, поскольку исчерпывающий поиск можно применять только при работе с базами прецедентов сравнительно небольшого объема. Одним из популярных методов эффективного индексирования является использование разделяемой сети свойств (shared feature network). При этом прецеденты, у которых какие-либо свойства совпадают, включаются в один кластер, в результате чего формируется таксономия типов прецедентов. Сопоставление в такой разделяемой сети свойств выполняется с помощью алгоритма поиска в ширину без обратного прослеживания. Поэтому время поиска связано с объемом пространства логарифмической зависимостью. Индивидуальное сопоставление, как правило, выполняется следующим образом.
Каждому свойству (или размерности) присваивается определенный вес, соответствующий степени "важности" этого свойства. Если, например, прецеденты включают счета пользователей, то имя пользователя, скорее всего, не имеет значения при поиске группы прецедентов с похожими счетами. Следовательно, свойство имя может иметь вес 0. А вот остаток на счете (в долларах) имеет очень существенное значение и ему следует придать вес 1.0. Чаще всего значения весов — это действительные числа в интервале [0,1].
Из всех этих рассуждений вытекает простой алгоритм сопоставления прецедентов, представленный ниже.
База прецедентов
22.1. База прецедентов
Приведенная выше аналогия с библиотекой удобна, но является далеко не полной. Прецеденты — это не книги; хотя их и связывают с книгами некоторые общие абстрактные свойства, имеются и существенные отличия.
Прецеденты напоминают книги (конечно же, не из разряда беллетристики) тем, что содержат определенную специфическую информацию, "вставленную" в некоторый контекст. Содержимое прецедента — это знание, а контекст описывает некоторое состояние внешнего мира, в котором это знание применяется. Однако прецедент содержит знание в такой форме, которая может быть воспринята программой. Другими словами, знания, содержащиеся в описании прецедента, "готовы к употреблению" в том же смысле, в каком порождающие правила готовы к применению.
Прецедент должен представлять решение проблемы в определенном контексте и описывать то состояние мира, которое получится, если будет принято предлагаемое в нем решение. Это свойство часто можно встретить и в содержимом книг, но, опять же, разница состоит в том, что информация не представлена в форме, удобной для восприятия программой.
Хотя описания прецедентов и варьируются по размеру, они все-таки значительно уступают книгам в этом смысле. Информация в описаниях прецедентов значительно более сжата и представляется на каком-либо формальном языке.
Если прецедент — это модуль знаний, который может быть считан программой, то в чем его отличие от других способов представления знаний, множество которых мы уже рассмотрели в этой книге? Самый короткий ответ на этот вопрос — прецедент, как правило, реализуется в виде фрейма (см. главу 6), в котором структурированы информация о проблеме, решение и контекст. Так же, как фрейм или порождающее правило, описание прецедента может быть сопоставлено с данными или описанием цели. Но для извлечения описания прецедента из базы таких описаний используется совсем другой механизм, чем для извлечения фрейма или порождающего правила. Первое, что делается в процессе применения прецедента, — его адаптируют к текущей ситуации. Поэтому поиск описания прецедента требует использования достаточно сложного механизма индексирования.
Обучение с помощью системы САТО
22.2.3. Обучение с помощью системы САТО
При разработке системы САТО преследовалась цель предоставить в распоряжение студентов-юристов среду, в которой они могли бы научиться вести рассуждения в ходе разбора судебного дела и проверять гипотезы относительно применения статей закона [Ashley and Aleven, 1997], [Aleven and Ashley, 1997]. Как было сказано в предыдущем разделе, в процессе обсуждения дела в судебном заседании нужно уметь формулировать собственные аргументы и опровергать аргументы противной стороны. Важной частью судебных прений является также умение формулировать и проверять гипотезы о возможности применения тех или иных статей закона к рассматриваемым обстоятельствам дела.
Задача студента при работе в этой среде состоит в том, чтобы проанализировать обстоятельства дела с юридической точки зрения и сформулировать аргументы в пользу обеих сторон, т.е. как в пользу истца, так и в пользу ответчика. Эти аргументы должны включать список прецедентов, выбранных из базы прецедентов системы, которые каждая из сторон может использовать, отстаивая свою точку зрения. В той версии системы, которая существует в настоящее время, представлены юридические знания о соблюдении секретности при выполнении торговых сделок, т.е. законы, касающиеся контроля конфиденциальной коммерческой информации, которая не должна использоваться в нечестной конкурентной борьбе.
В типичном судебном деле о торговых секретах истец утверждает, что ответчик каким-то образом получил доступ к конфиденциальной информации и затем использовал ее для получения преимущества в конкурентной борьбе. Сторонами в процессе, как правило, но не всегда, являются компании, а конфиденциальная информация носит технический характер. Для всех дел такого рода характерны некоторые общие черты. Например, предпринимал ли истец меры для защиты информации от несанкционированного доступа, давал ли ответчик обязательство не использовать полученную информацию или воспрепятствовать доступу к ней со стороны третьих лиц.
Для анализа конкретного дела можно использовать специальный словарь, ассоциированный с этими темами. База системы САТО содержит около 150 прецедентов, которые проанализированы в отношении ряда факторов. Ниже представлены примеры типичных факторов и их определения.
Преимущество в конкуренции. Получение ответчиком доступа к секретной информации истца дает ответчику преимущество в конкуренции.
Раскрытие секретов. Истец по собственной воле не предоставлял посторонним доступ к информации.
Подкуп служащих. Ответчик подкупил служащих истца, для того чтобы они нарушили обязательства, данные при приеме на работу.
Такие факторы используются для организации индексации прецедентов в базе. Факторы классифицированы в соответствии с тем, аргументы какой из сторон они поддерживают. Эта информация вместе со знанием, какая же из сторон в конце концов выиграла дело, позволяет выполнить довольно интересный анализ прецедентов.
Задав булеву комбинацию факторов по своему выбору, студент может извлечь из базы соответствующие прецеденты и выяснить, какая часть дел была выиграна каждой из сторон в указанных обстоятельствах.
Студент может выбрать из базы те прецеденты, в которых сочетание факторов аналогично рассматриваемому случаю, и проанализировать поведение сторон в ходе судебных прений.
База данных САТО содержит не полные отчеты о судебном разбирательстве, а "выжимки" из него, но поиск в базе осуществляется не по тексту протокола заседания, а по индексированным факторам, что упрощает общение студента со средой.
Информация о прецеденте, извлеченная из базы данных, содержит список факторов этого прецедента, указание, какие из факторов обнаружены и в текущем деле, а какие в нем отсутствуют, в пользу какой из сторон "сыграл" каждый из факторов. Использование более сложного механизма индексации позволяет моделировать и более интеллектуальные методы рассуждений.
Спор вокруг подобия и различия между рассматриваемым делом и прецедентами в значительной мере зависит от того, на каком уровне абстрагирования он ведется. Каждая из сторон выбирает определенную интерпретацию пунктов текущего дела в сравнении с прецедентами. Аргументируя близость, адвокат должен выбрать такие факторы, которые подобны в рассматриваемом деле и прецеденте, и доказать, что именно они играют существенную роль на данном уровне абстракции, в то время как несовпадающие факторы можно игнорировать как несущественные. Если же цель состоит в том, чтобы отвергнуть прецедент, на который ссылается противоположная сторона, нужно доказать, что наиболее существенные факторы в рассматриваемом случае как раз отличаются от прецедента.
Такой способ рассуждения уже не может опираться на обычную семантическую сеть. В иерархии факторов, помимо маркирования каждого из факторов, в чью пользу, истца или ответчика, он "играет", в явном виде должны быть представлены отношения между ними. Лучше проиллюстрировать это соображение примером.
На рис. 22.2 показан фрагмент иерархии факторов в системе САТО. Верхний узел на представленном фрагменте, средства поддержания секретности, представляет фактор, посредством которого истец, ссылающийся на нарушение режима конфиденциальности, утверждает, что с его стороны были предприняты необходимые меры обеспечения секретности. (Утолщенная рамка вокруг этого узла указывает, что данный фактор "работает" в пользу истца.)
Обучение с помощью компьютера: система САТО
22.2. Обучение с помощью компьютера: система САТО
В главах 11 и 12 мы уже говорили о том, что при работе над экспертными системами второго поколения исследователи пришли к выводу, что представление знаний внутри экспертной системы должно со временем привести к созданию систем обучения с помощью компьютера (CAI — computer-aided instruction). Если в нашем распоряжении имеется программа, которая успешно решает определенный круг проблем, то она, вероятно, может быть использована и для того, чтобы научить студентов решать аналогичные проблемы.
Однако оказалось, что превратить экспертную систему в эффективное средство обучения далеко не так легко, как это кажется с первого взгляда. Программа должна отдавать себе отчет в том, как именно она решает проблему и почему на данном этапе процесса отдает предпочтение именно таким знаниям. Исследователи пришли к выводу, что в процессе обучения особую важность имеет набор стратегий решения проблем и что эти стратегии должны быть представлены в программе в явном виде, а не просто реализованы в программном коде.
В этом разделе мы опишем программу САТО, которая была создана для обучения студентов-юристов методике ведения судебных дел. В основу программы положена абстрактная модель процесса прения сторон. Программа является развитием системы HYPO, в которой используется описанная выше методика анализа прецедентов для юриспруденции. База прецедентов этой системы содержит множество отчетов о судебных делах; получив спецификацию нового дела, система отыскивает наиболее близкий прецедент и анализирует отличия между ним и полученными данными. Мы увидим, что методика сравнения и противопоставления (compare and contrast) является таким же мощным средством решения проблем, как и ранее рассмотренные методики предложение и применение и предположение и проверка.
Формирование отчетов в системе FRANK
22.3. Формирование отчетов в системе FRANK
Работая над каким-либо отчетом, авторы могут преследовать совершенно различные цели. В одних случаях составляется беспристрастный обзор состояния дел, в других материал отчета должен подвести читателя к определенному выводу (желательному для автора), в третьих — обосновать определенное решение, принятое ранее. От того, с какой целью составляется отчет, зависит и подбор информации в нем, и стратегия ее освещения. Например, готовя обзор состояния исследований в определенной области для научного журнала, автор старается охватить как можно больший материал, в то время как адвокат в своем отчете ограничивается только теми прецедентами, которые интересуют его клиента.
Система FRANK [Rissland et al., 1993] относится к классу систем с доской объявлений, в которой объединены парадигмы вывода суждений на основе правил и прецедентов и которая предназначена для формирования отчетов по медицинской диагностике. (Название FRANK — искаженная аббревиатура от Flexible Report and Analysis System.) Основной упор при разработке системы был сделан на взаимодействие между целями высокого уровня, которые ставит перед собой автор отчета, и информационными подцелями, такими как извлечение подходящих прецедентов.
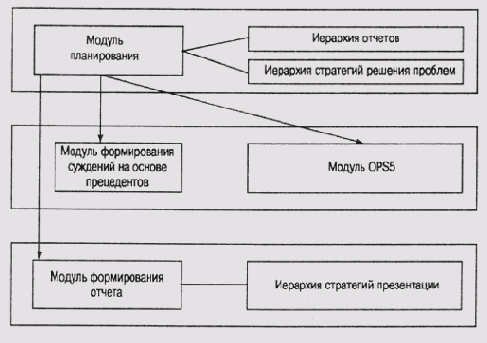
В состав системы FRANK входят три главных компонента (рис. 22.3).
Модуль планирования обеспечивает управление функционированием системы. Он выбирает заготовку плана из библиотеки планов, а затем выполняет иерархическое планирование, конкретизируя выбранную заготовку.
Модуль формирования суждений на основе прецедентов и модуль продукционной системы (в действительности эту функцию выполняет модуль OPS5) выполняют логический вывод в предметной области, опираясь на соответствующие базы знаний.
Модуль формирования отчета для пользователя имеет в своем распоряжении разнообразные стратегии, которые базируются на знаниях из области риторики.
Знания, которыми располагает система FRANK, разделены между тремя иерархическими структурами.
В иерархии отчетов отчеты классифицированы соответственно целям их создания. Например, является ли отчет суммирующим или аргументирующим, отстаивающим определенную позицию или нейтральным и т.д.
В иерархии стратегий решения проблем представлены знания о том, как собирать информацию для отчета определенного типа, например как отыскать подходящие данные или как поступать с данными, поддерживающими противоположное заключение.
Из иерархии стратегий презентации система черпает знания о том, как скомпоновать выводы в отчете. Например, стоит ли сначала располагать веские аргументы или лучше начать с анализа достоинств и недостатков альтернативных вариантов.
Сравнение систем, основанных на правилах и прецедентах
22.4. Сравнение систем, основанных на правилах и прецедентах
Существует достаточно сильная аналогия между системами, основанными на правилах и прецедентах. И те и другие необходимо каким-то образом индексировать, чтобы обеспечить эффективное извлечение. И те и другие выбираются в результате сопоставления, причем выбор и ранжирование производятся на основании фоновых знаний, хранящихся в каких-либо дополнительных структурах, например в виде фреймов (в MYCIN аналогичную роль выполняют таблицы знаний).
Однако нас больше интересуют различия между этими двумя классами систем. Они суммированы в работе [Kolodner, 1993].
Правило выбирается на основе точного сопоставления антецедента и данных в рабочей памяти. Прецедент выбирается на основе частичного сопоставления, причем учитываются еще и знания о сущности характеристик, по которым выполняется сопоставление.
Применение правил организовано в виде итерационного цикла — последовательности шагов, приводящих к решению. Прецедент можно рассматривать как приближенный вариант полного решения. Иногда, однако, появляется возможность итеративно проводить аналогию с разными прецедентами, которые "подходят" для различных частей проблемы.
Построение суждений на основе прецедентов поддерживает и другую стратегию решения проблем, которую мы назвали "извлечение и адаптация". Эта стратегия существенно отличается и от эвристической классификации, и от стратегии "предложение и проверка", как, впрочем, и от всех остальных, рассмотренных в главах 11-15. В новом подходе есть нечто очень близкое нам интуитивно, поскольку весьма напоминает наш повседневный опыт. Даже на первый взгляд ясно, как привлекательно вспомнить аналогичный случай, принесший успех в прошлом, и поступить так же. Редко кто из нас затрудняет себя "нудными рассуждениями", когда можно быстро извлечь готовое решение.
Нужно, однако, предостеречь тех, кто считает, будто использование прецедентов поможет нам избавиться от утомительной работы по извлечению знаний и построению обоснованного логического заключения.
Человеческая память подвержена сильному эмоциональному влиянию — нам свойственно помнить успехи и забывать о неудачах. Прошлые успехи всегда предстают в розовом свете, а потому во многих случаях нельзя рассматривать прецеденты как достаточно надежную основу для правильных выводов. Есть и еще одно существенное соображение, которое не позволяет нам безоговорочно довериться прецедентам, — масштабность. Можно говорить об анализе десятков прецедентов, но когда масштаб решаемой проблемы потребует сопоставления сотен и тысяч прецедентов, существующему механизму анализа задача окажется не по плечу.
Но, тем не менее, мы можем оптимистически смотреть на перспективы систем, использующих в ходе рассуждений прецеденты. Это, без сомнения, один из способов использовать прошлый опыт, и будет весьма интересно проследить, как исследователи и инженеры смогут воспользоваться потенциальными достоинствами этой технологии.
Архитектура программы CHEF
Архитектура программы CHEF
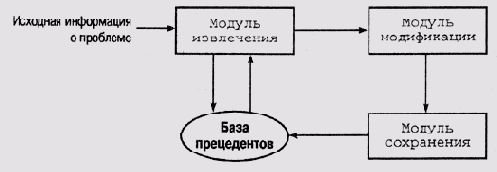
Модель извлечения отыскивает в базе прецедентов рецепты, наиболее близкие к текущему заказу. Очевидно, что этот модуль должен обладать способностью обращаться к базе прецедентов как к памяти, адресуемой по содержанию, оценивать степень соответствия между набором входных спецификаций и характеристиками выбранного прецедента и ранжировать отобранные прецеденты на основании этой оценки.
Модуль модификации затем копирует и переименовывает выбранный прецедент и пытается скорректировать его в соответствии с полученной целевой спецификацией. В приведенном выше примере подстановка "брокколи" вместо "зеленый горошек" и модификация плана выполняются именно этим модулем.
После выполнения всех необходимых коррекций новый рецепт записывается модулем сохранения в базу прецедентов.
В программе CHEF корректировка неудачного плана (рецепта) в действительности выполняется отдельным модулем, который имеет доступ к специальному словарю термов, описывающих отказы, и индексированному множеству стратегий восстановления. Имеется также и специальный "симулятор", который позволяет "проиграть" сформированный рецепт и выявить в нем подводные камни, не заметные на первый взгляд. По основные модули работы с прецедентами выполняют именно те функции, которые мы описали выше.
Архитектура системы FRANK
Архитектура системы FRANK
Поток управления в системе можно описать в терминах последовательности шагов обращения к источниками знаний, которые манипулируют данными на доске объявлений (см. об этом в главе 18). Вместо того чтобы по очереди описывать каждый источник знаний, мы представим основные этапы обработки, в результате которых формируется и выполняется план построения отчета. Исходные данные имеют формат перечня тем (например, нужно ли, чтобы определенная медицинская процедура была подтверждена случаями из практики), а выход системы — это отчет, в котором темы изложены в соответствии с заявленными предпочтениями.
Начальный источник знаний формирует скелет отчета, в котором зарезервированы разделы для определенных фрагментов информации.
Затем формируются стратегии для отдельных разделов, для чего привлекаются другие источники знаний. Стратегии извлекают планы разделов из библиотеки планов.
Специальный источник знаний конкретизирует каждый план и выполняет его, активизируя соответствующую цель. После формирования цепочки "цель—подцель" удовлетворяются цели нижних уровней. Как правило, такие подцели заполняют слоты шаблона отчета.
Другие источники знаний проверяют совместимость разделов отчета. Если противоречия не обнаруживаются, выходной документ формируется в соответствии со стратегией презентации. В противном случае корректируется план.
Таким образом, сначала система на основании введенной пользователем информации выбирает тип отчета. Например, пользователь может запросить у системы отчет с предложением, который должен обосновать определенный диагноз. В этом случае система FRANK выберет отчет типа Diagnosis-with-Alternatives (диагнозы и варианты) и воспользуется стратегией уравнивающее сравнение (equitable comparison), которая назначается для этого типа отчета по умолчанию.
Комбинируя тип отчета и стратегию, система строит определенный план, в котором, в частности, есть место и для информации о прецедентах, подходящих для текущего диагноза. Наиболее подходящий прецедент выбирается по совпадению большинства симптомов с анализируемым случаем, но возможны и другие стратегии.
Например, более аргументированная стратегия может потребовать, чтобы прецедент считался подходящим, если:
он совпадает по большинству симптомов с текущим случаем; Ф имеет совпадающий диагноз;
не содержит никаких свойств, подобных прецедентам, имеющим другой диагноз.
А что произойдет, если не будет найден прецедент, отвечающий перечисленным требованиям? Тогда требования ослабляются (например, убирается последнее из перечисленных), и поиск повторяется.
Формирование запросов к базе прецедентов выполняется под присмотром источника знаний, который играет роль механизма планирования задач. Такие запросы могут быть частичными, т.е. определенные атрибуты запроса заполняются значениями по умолчанию. Этот же модуль обеспечивает различные варианты поведения системы, если поиск не даст результата. В частности, могут быть изменены ограничения на значения параметров в запросе, после чего поиск возобновляется.
Система FRANK поддерживает две методологии формирования суждений на основе прецедентов:
стиль поиска ближайшего соседа, как в системе CHEF;
группирование прецедентов по степени "похожести" в соответствии с определенным набором факторов верхнего уровня, как в системе САТО.
Выбор той или иной методологии зависит от контекста отчета. Например, атрибуты низкого уровня (вроде возраста и пола пациента) могут быть менее важными, чем факторы высокого уровня, используемые для классификации медицинских процедур. Но возможен и такой вариант, когда к определенной проблеме никак не удается применить факторы верхнего уровня и остается полагаться только на атрибуты нижнего уровня.
Такая гибкость в выборе методологии позволяет уравновесить влияние целей высокого уровня и результатов низкого уровня.
Фрагмент иерархии факторов в системе САТО ([Ashley and Aleven, 1997])
Фрагмент иерархии факторов в системе САТО ([Ashley and Aleven, 1997])

Существуют субфакторы, которые поддерживают это утверждение. Например, факт, что были предприняты определенные меры обеспечения безопасности, которые должны были предотвратить утечку информации, очевидно, поддерживает в споре позицию стороны истца. (Связи таких субфакторов с родительским узлом помечены знаком "плюс", поскольку они поддерживают родительский узел в иерархии — "усиливают" завоеванную им позицию.) Существуют, однако, и субфакторы, которые "ослабляют" эффект утверждения, порождаемого родительским фактором. Например, если истец однажды подписал отказ от режима конфиденциальности или разрешил своему служащему ознакомить с этой информацией посторонних на каком-нибудь общедоступном форуме, например, на технической конференции. Такие факторы ослабляют позицию, завоеванную родительским фактором, и потому соответствующие связи маркируются знаком "минус".
Субфакторы, в свою очередь, могут иметь собственные субфакторы, которые также объединены с родительскими узлами положительными или отрицательными связями. В САТО используется несколько алгоритмов, с помощью которых выносится решение, на каком уровне абстракции в этой иерархии нужно сфокусировать аргументы, если желательно подчеркнуть подобие случаев или их различие. Подробное .описание этих алгоритмов выходит за рамки настоящей книги, но главная их особенность заключается в том, что они основаны на применении очень специфичной схемы индексирования, связанной с базой знаний о предметной области.
Рассуждения, основанные на прецедентах
ГЛАВА 22. Рассуждения, основанные на прецедентах 22.1. База прецедентов 22.1.1. Программа CHEF 22.1.2. Методы извлечения и адаптации прецедентов 22.2. Обучение с помощью компьютера: система САТО 22.2.1. Предметная область программы САТО 22.2.2. Расследования и рассуждения в юриспруденции 22.2.3. Обучение с помощью системы САТО 22.3. Формирование отчетов в системе FRANK 22.4. Сравнение систем, основанных на правилах и прецедентах Рекомендуемая литература Упражнения
Предметная область программы САТО
22.2.1.
Предметная область программы САТО
Ежедневно в апелляционных судах США выносится около 500 судебных решений. Каждое из них представляет собой определенный прецедент в судебной практике (подборки таких отчетов распространяются через сеть World Wide Web или на компакт-дисках). Решение, принимаемое апелляционным судом, как правило, основывается на так называемом "прецедентном праве" и включает интерпретацию соответствующих статей существующего законодательства и набор прецедентов, в которых были приняты аналогичные решения. Для юриста одним из главных компонентов знания законодательства, касающегося дел определенного вида, например о банкротстве или об ответственности за выпуск продукции, является знакомство с ранее расследованными подобными делами.
Другая часть юридического знания — умение найти в законодательстве аргументы за или против определенных обстоятельств в конкретном деле. Поскольку квалифицированный юрист должен уметь выступать в обеих ипостасях— и как защитник, и как прокурор, — такие знания должны быть обобщены. Они непременно должны включать стратегию поведения обеих сторон в судебном процессе при определенных обстоятельствах. Эти обстоятельства включают по большей части мириады фактов, сопряженных с рассматриваемым делом, т.е. кто кому что сделал или что точно сказал и в каком контексте.
Хотя кажется невероятным, что компьютер может взять на себя роль советчика в юридических делах, юристы вполне могут воспользоваться им для поиска прецедентов, имеющих отношение к тому, что их интересует в настоящее время. Поиск и интерпретация таких прецедентов представляет собой отнюдь не тривиальную задачу, которую с полным правом можно отнести к классу интеллектуальных. Однако нас сейчас интересует не столько такая экспертная система, сколько структура программы, которая могла бы обучить будущего юриста.
Расследования и рассуждения в юриспруденции
22.2.2.
Расследования и рассуждения в юриспруденции
И расследования, и рассуждения в юриспруденции направляются аргументацией, а более точно — аргументами, выражающими противоположные интересы, с помощью которых стороны процесса пытаются склонить на свою строну судью или присяжных, убедить их в том, что именно предлагаемая интерпретация закона и фактов является корректной в данном случае. Забота сторон в процессе, т.е. юристов, выступающих от имени сторон, не столько установить истину (это — забота судьи и присяжных), сколько наилучшим образом представить в судебном процессе интересы клиента. Следовательно, в том, что происходит в судебном заседании, имеется некоторый аспект игрового соперничества — стороны делают определенные ходы в борьбе за преимущество.
Базовая предпосылка, сделанная разработчиками системы САТО, состоит в том, что эти ходы могут быть описаны в рамках какой-то системы и затем использованы для обучения. Для выполнения очередного хода в игре нужно выбрать прецеденты в базе знаний о прецедентах, причем выбор должен учитывать как информацию о текущем случае, так и возможные ходы оппонентов. Таким образом, поведение сторон можно рассматривать как планирование трехходовой комбинации в игре:
одна сторона с помощью своего набора прецедентов "продвигает" свою позицию в игре;
противоположная сторона выдвигает другой набор прецедентов для представления своих аргументов;
первая сторона наносит новый удар, выдвигая соображения, парирующие в определенной степени аргумент противной стороны.
Ходы и контрходы можно анализировать в терминах суждений, основанных на прецедентах. Эшли считает, что в основе такой модели аргументации лежит следующий процесс [Ashley, 1990].
(1) Сравнение текущего случая с прецедентом с прицелом на обоснование аналогичного результата.
(2) Определение отличия (противопоставление) между текущим случаем и прецедентом, чтобы найти аргумент против того же результата.
(3) Поиск контрпримера к (1), в котором аналогичный прецедент привел к другому результату.
(4) Формулировка гипотетических прецедентов, которые дали бы аргументы за и против определенной позиции.
(5) Комбинирование сравнений и противопоставлений в аргумент, который включает оценку конкурирующих аргументов.
Эта модель аргументации реализована в системе HIPO, в которой процесс формирования аргумента выполняется за шесть шагов.
(1) Анализ факторов, присущих текущему случаю.
(2) Извлечение прецедентов на основе этих факторов.
(3) Упорядочение извлеченных прецедентов по степени близости к текущему случаю.
(4) Выбор наиболее подходящих прецедентов как с точки зрения одной стороны, так и с точки зрения другой.
(5) Формирование аргументов для трехходовой комбинации по каждому из пунктов текущего дела.
(6) Проверка результатов на гипотетических случаях.
Выполнение шага (5) усложняется тем обстоятельством, что судебное дело может содержать более одного пункта. Например, дело о разводе может содержать множество пунктов, касающихся раздела имущества, обеспечения детей и т.д., по каждому из которых стороны должны представить свои аргументы.
Рассуждения, основанные на прецедентах
Рассуждения, основанные на прецедентах
22.1. База прецедентов
22.2. Обучение с помощью компьютера: система САТО
22.3. Формирование отчетов в системе FRANK
22.4. Сравнение систем, основанных на правилах и прецедентах
Рекомендуемая литература Упражнения
В главе 2 мы отмечали, что в ранних программах искусственного интеллекта отчетливо прослеживалась тенденция использовать по возможности единообразные методы решения проблем. Логические рассуждения строились на основе небольшого количества предположений или аксиом, а множество правил, применяемых для формирования нового состояния проблемы, также было невелико. Такие классические области искусственного интеллекта, как игры и доказательство теорем, являются формальными системами, которые по самой своей сути годятся для подобной комбинации логического анализа и эвристического поиска. Хотя в подавляющем большинстве экспертных систем применяется большое количество правил, специфичных для определенной предметной области, и используются разнообразные методы решения проблем, способы поиска и организации логического вывода, по сути, не очень отличаются от тех, что использовались в ранних программах искусственного интеллекта.
Например, в процессе работы производящей системы представление состояния проблемы в рабочей памяти последовательно изменяется, все более приближаясь к состоянию, характеризующему искомое решение. Такой пошаговый процесс очень напоминает последовательность ходов, дозволенных правилами игры, а отличие заключается в основном в семантике используемых правил. Программа игры в шахматы, основанная на знаниях, должна опираться не только на правила выполнения ходов, но и на информацию о стратегии, типовых ситуациях на доске, способах распознавания стадий игры (дебют, миттельшпиль или эндшпиль) и т.д.
Существует, однако, множество рутинных задач, выполняемых человеком, которые не вписываются в эту парадигму. Трудно себе представить, что, решая задачу, куда пойти сегодня вечером (в какой ресторан или кинотеатр), человек сознательно или подсознательно выполняет логический анализ или эвристический поиск. Если обратиться к менее тривиальным примерам, то также трудно поверить, будто судья, архитектор или ваш шеф, принимая решение, всегда прибегают к логическому анализу. Скорее всего, в большинстве случаев в основе наших действий в повседневных ситуациях лежит другой механизм рассуждений и принятия решения.
В отличие от большинства машин, человек почти всегда чем-то занят или озабочен, а потому при решении повседневных проблем уже на подсознательном уровне стремится сэкономить время и силы. И здесь на помощь всегда приходят память и прежний опыт — для человека проще распознать ситуацию и найти для нее аналог, чем заново формировать решение.
Но как все это можно реализовать в компьютерной модели рассуждений? Мы уже знаем, что воспоминания и приобретенный опыт не так просто свести к набору правил, но можно представить себе некоторую "библиотеку" ситуаций, встречавшихся в прошлом, которые имеют отношение к возникшей проблеме, например "репертуар" указаний шефа, или судебные решения, принятые в прошлом по аналогичным делам, или наброски архитектурных планов для сооружений аналогичного назначения и т.п. Естественно, что такая библиотека должна быть индексирована каким-то разумным способом, чтобы в массиве хранящихся описаний ситуаций можно было довольно быстро распознать аналогичную текущей. Кроме того, понадобится также и некоторый механизм, который позволит адаптировать ранее принятое решение к новой проблеме (текущей ситуации).
Описанный подход получил наименование рассуждение, основанное на прецедентах (case-based reasoning). Мы рассмотрим эту новую технологию на трех примерах, взятых из разных предметных областей, — кулинарии, юриспруденции и делопроизводства. После этого мы вновь вернемся к сравнению рассуждений, основанных на прецедентах, с более привычной технологией логического вывода в экспертных системах и покажем, что эти технологии не противоречат, а дополняют друг друга. В главе 23 этот тезис будет подкреплен примерами и дальнейшим анализом.
Рекомендуемая литература
Рекомендуемая литература
Единственной книгой, в которой достаточно полно рассмотрена технология использования прецедентов в системах искусственного интеллекта, является [Kolodner, 1993]. В перечень кратких обзорных статей, которые можно рекомендовать для первого знакомства, я бы включил [Blade, 1991], [Harmon, 1992], [Kolodner, 1992] и [Watson and Marir, 1994]. Обзор инструментальных средств, предназначенных для работы с базами данных прецедентов, представлен в работе [Harmon and Hall, 1993].
Описания действующих систем, основанных на прецедентах, читатель найдет в работах [Acorn and Walden, 1992], [Allen, 1994], [Nguyen et al, 1993], [Hislop andPracht, 1994],-[Barren etal, 1993].
Что представляет собой библиотека прецедентов?
Упражнения
1. Что представляет собой библиотека прецедентов? В чем ее отличие от обычной книги?
2. В чем состоит основное отличие методики формирования суждений на основе прецедентов от логического вывода на основе правил?
3. Как соотносятся прецеденты и фреймы? Как можно применить концепцию фреймов по отношению к прецедентам?
4. Предположим, вы купили омара и желаете приготовить из него какое-нибудь блюдо для себя и гостей. Библиотека прецедентов о блюдах из омаров состоит из записей такого формата.
| Свойство |
Вес |
Свойство Вес |
|||
| Наименование |
0.0 |
Приправы |
0.7 |
||
| Основной соус |
0.9 |
Алкоголь |
0.5 |
||
Например, блюдо "Омар в сметане" будет представлено в этой библиотеке следующей записью.
| Свойство |
Значение |
||
| Наименование |
Омар в сметане |
||
| Основной соус |
Сметана |
||
| Основная приправа |
Паприка |
||
| Алкоголь |
Шерри |
||
| Свойство |
Значение |
||
| Наименование |
Омар о-Гратен |
||
| Основной соус |
Сметана |
||
| Основная приправа |
Паприка |
||
| Алкоголь |
Коньяк |
||
| Свойство |
Значение |
||
| Наименование |
Омар франко-американский |
||
| Основной соус |
Пищевая глазурь |
||
| Основная приправа |
Стручковый красный перец |
||
| Алкоголь |
Шерри |
||
блюда могут включать не один вариант соуса, например, "Омар в сметане" в действительности подается не только со сметаной, но и с голландским соусом;
блюда могут содержать не один алкогольный компонент, например, "Омар о-Гратен" может содержать помимо коньяка еще и белое вино;
некоторые приправы, соусы или алкогольные добавки более близки к одним, чем к другим, например, паприка ближе к карри, чем к орегано, белый шерри можно заменить мадерой, но не коньяком.
Как эти соображения могут повлиять на сопоставления с ближайшим соседом?
5. Подумайте над тем, как можно учесть перечисленные ниже факторы при вынесении решения, можно или нельзя оправдать человека в соответствии со статьей 35 Закона о
наказаниях как применившего для самозащиты при нападении "насилие, повлекшее за собой смерть".
Такой приговор считается обоснованным, если:
насилие использовано в качестве чрезвычайной меры, чтобы избежать угрозы поражения, не спровоцированного обвиняемым;
обвиняемый не имел возможности отступить или каким-либо другим способом избежать применения силы;
обвиняемый имел основания полагать, что другое лицо подвергается угрозе похищения, изнасилования или ограбления.
Такой приговор не может быть вынесен в случае, если:
обвиняемый является инициатором происшествия;
физическая сила была применена в обстоятельствах, не предусмотренных законом, например на дуэли;
обвиняемый имел возможность убежать с места происшествия или каким-либо другим способом избежать нападения, но не воспользовался им.
Существуют еще и усложняющие дело факторы, например:
лицо не обязано убегать, если находится в собственном доме;
применение силы со смертельным исходом считается недопустимым, если угрозе подвергается только собственность обвиняемого;
ответное применение силы со смертельным исходом считается недопустимым, если оно неадекватно угрозе, возникшей со стороны нападавшего.
Постройте иерархию этих фактов, аналогичную приведенной на рис. 22.2.
Возвратить MATCH.
Возвратить MATCH.
Базовая процедура называется сопоставлением с ближайшим соседом (Nearest-Neighbor matching), поскольку прецеденты, которые имеют близкие значения свойств, и концептуально ближе друг другу. Это может найти отражение и в структуре сети, где степень близости прецедентов будет соответствовать близости их свойств.
Вычисленное по этому алгоритму значение MATCH обычно называется агрегированной оценкой совпадения (aggregate match score). Естественно, что из базы прецедентов выбирается тот, который "заслужил" самую высокую оценку. Если же алгоритм работы системы предполагает и исследование альтернативных прецедентов, то оставшиеся должны быть ранжированы по полученным оценкам. Большинство доступных на рынке программ, имеющих дело с базами прецедентов, использует именно этот простой алгоритм. Применяемый на шаге (2) метод вычисления степени близости зависит от типа данных в каждом конкретном случае. При качественном сопоставлении свойств достаточно будет использовать двоичные оценки или вычислять расстояние в абстрактной иерархии. Так, в абстрактной иерархии ингредиентов кулинарных рецептов "брокколи" ближе к "горошку", чем к "цыплятам", и вычисленное значение должно отражать этот неоспоримый факт. Количественное сопоставление будет включать и шкалирование.
Для адаптации найденного прецедента к текущим целевым данным программы также используют разные методы. В большинстве случаев можно обойтись заменой некоторых компонентов в имеющемся решении или изменением порядка операций в плане. Но существуют и другие подходы, которые перечислены ниже.
Повторная конкретизация переменных в существующем прецеденте и присвоение им новых значений. Например, сопоставление переменной овощи со значением брокколи вместо прежнего значения горошек.
Уточнение параметров. Некоторые прецеденты могут содержать числовые значения, например время выполнения какого-либо этапа плана. Это значение должно быть уточнено в соответствии с новым значением другого свойства. Например, если в рецепте требуется заменить один ингредиент другим, то, вероятно, придется соответственно изменить и время его обработки.
Поиск в памяти. Иногда требуется найти способ преодоления затруднения, возникшего как побочный эффект замены одних компонентов решения другими. Примером может послужить уже упоминавшийся выше эффект нежелательного изменения свойств брокколи при обжаривании вместе с кусочками баранины. Такой способ можно отыскать в той же базе прецедентов или в специальной базе знаний.
Большинство из перечисленных методов жестко связано со способом представления иерархии абстракций, который используется в конкретной программе. Это может быть система фреймов или семантическая сеть, и в каждом из этих вариантов подстановка одних концептов вместо других должна быть организована по-своему.
В следующем разделе мы рассмотрим систему, в которой используется довольно специфический способ представления знаний для моделирования предметной области. Для организации базы прецедентов в этой системе используется не разделяемая сеть свойств, а факторы более высокого уровня абстракции, связанные со спецификой предметной области. Такое представление требует применения более сложного механизма индексирования прецедентов и их поиска, чем тот, который использовался в модуле извлечения программы CHEF.
